







项目数据来源于kaggle,为House Prices Prediction.
案例说明及相关数据可在kaggle上查询并下载:
House Prices: Advanced Regression Techniques
数据包含用于建模的Train数据集以及用于模型验证的Test数据集
这是一份用于回归预测的数据集,其目的是利用数据集中的特征数据,来预测房屋的销售价格(SalePrice)。评判规则为均方根误差,即预测售价与实际售价相符的程度。查看数据发现,共有81个变量,其中第一个为ID,最后一个为SalePrice,即要预测的目标值。
数据挖掘的流程包括以下七个步骤:定义问题、准备数据、数据可视化探索、数据清洗、数据处理、特征工程、建模预测。对于比赛来说,前两个步骤可以省略,要解决的问题和数据都已经给出,重点就在后面五个步骤上,下面我们一个个来过。
首先,导入本次分析会用到的工具包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
color=sns.color_palette()
sns.set_style('darkgrid')
import warnings
warnings.filterwarnings('ignore')
from scipy import stats
from scipy.stats import norm,skew读取数据集
train=pd.read_csv('train.csv')
test=pd.read_csv('test.csv')
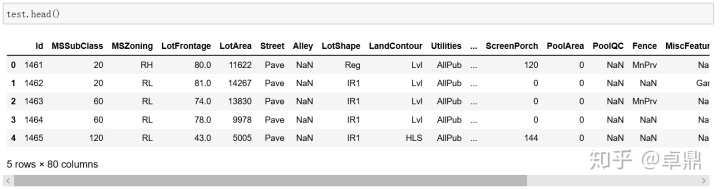
一、数据可视化探索
id列对于该次分析不起作用,可在数据集中删掉
train_ID = train['Id']
test_ID = test['Id']
train.drop('Id',axis=1,inplace=True)
test.drop('Id',axis=1,inplace=True)合并train,test,并查看基本信息
ntrain=train.shape[0]
ntest=test.shape[0] #分别计算train和test的行数,若为shape[1]表示计算列数
y_train=train.SalePrice.values
all_data=pd.concat((train,test)).reset_index(drop=True) #pandas contact 之后,一定要记得用reset_index去处理index,不然容易出现莫名的逻辑错误
all_data.drop('SalePrice',axis=1,inplace=True)
print(f'all_data size is:{all_data.shape}')all_data size is:(2919, 79)
统计每个特征的缺失值,并按降序排列
all_data_na=(all_data.isnull().sum()/len(all_data))*100
all_data_na=all_data_na.drop(all_data_na[all_data_na==0].index).sort_values(ascending=False)[:30]
missing_data=pd.DataFrame({'Missing Ratio':all_data_na})
missing_data.head(20)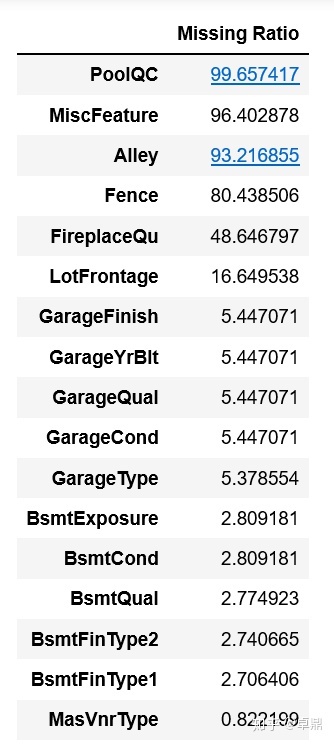
将缺失值的比例用柱形图表示
fig,ax=plt.subplots(figsize=(15,12))
plt.xticks(rotation='45')
sns.barplot(x=all_data_na.index,y=all_data_na)
plt.xlabel('Features',fontsize=15)
plt.ylabel('Percent of missing values',fontsize=15)
plt.title('Percent of missing values VS Features')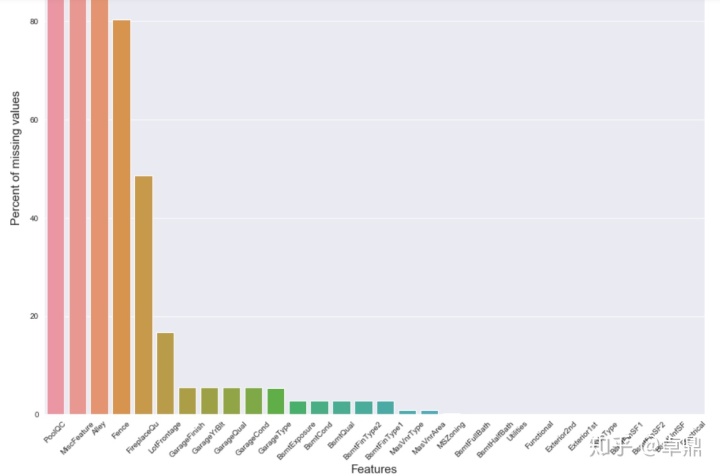
通过热力图观察各变量之间的线性相关性
corrmat=train.corr() #用pandas计算相关系数
fig,ax=plt.subplots(figsize=(12,9))
sns.heatmap(corrmat,vmax=.8,square=True)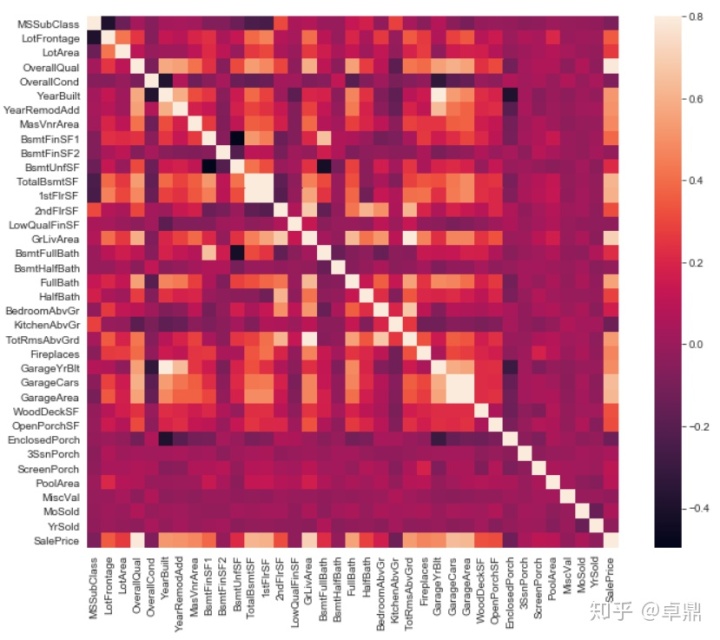
选出10个与房价相关性最强的变量查看相关性系数
k=10
fig,ax=plt.subplots(figsize=(12,12))
cols=corrmat.nlargest(k,'SalePrice')['SalePrice'].index
cm=np.corrcoef(train[cols].values.T) #用numpy计算相关系数
sns.set(font_scale=1.25)
hm=sns.heatmap(cm,cbar=True,annot=True,square=True,fmt='.2f',lw=1,annot_kws={'size':10},yticklabels=cols,xticklabels=cols)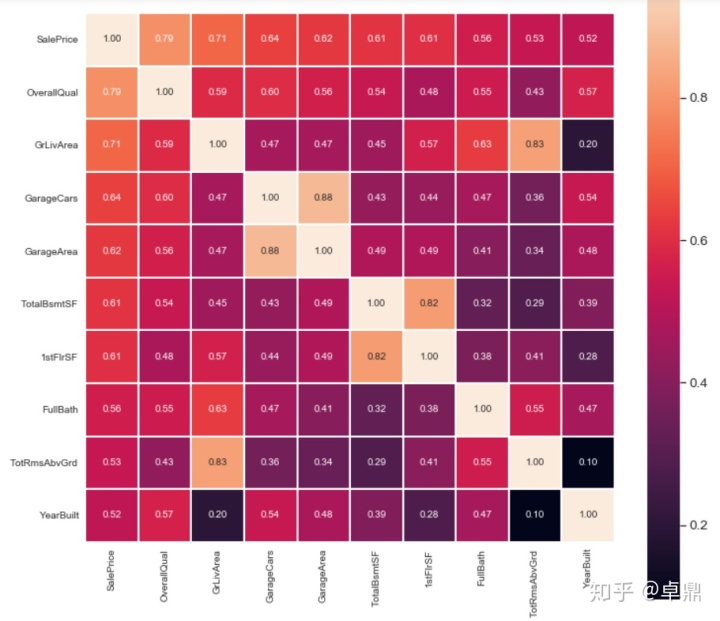
通过上面的热力图,我们可以有如下的结论:
1、'OverallQual', 'GrLivArea' 和 'TotalBsmtSF'与房价的相关性很强,可以后面再深入探索
2、'GarageCars'(车库能放多少量车) 和 'GarageArea' (车库面积)和房价同样有比较强的相关性,但注意到这两个变量本身的相关性也很强,因为车库面积和车库能放多少车本身就是有强相关性的,所以这就会涉及到我们之前提到过的多重共线性的问题,对于这两个变量,我们可以去掉一个,只留一个就可以了
就发现的和房价相关性较强的变量,再深入看一下它们和房价的关系
GrLivArea代表含义是居住面积,发现和房价有比较明显的正相关关系。可以在右下角看到两个明显的outlier,价格很低,但面积巨大,所以可以考虑删除掉这两个异常值。
fig,ax=plt.subplots()
plt.scatter(x=train['GrLivArea'],y=train['SalePrice'])
plt.xlabel('GrLivArea',fontsize=13)
plt.ylabel('SalePrice',fontsize=13)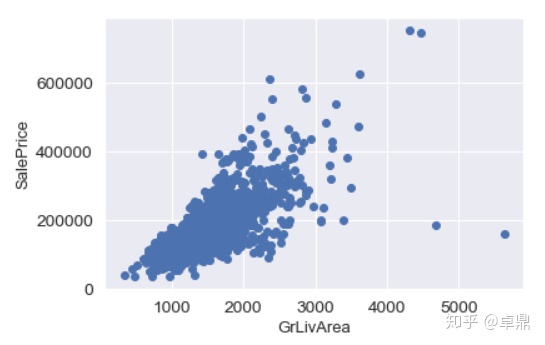
TotalBsmtSF含义为地下室面积,发现地下室面积与房价似乎有更强的潜在线性关系,同时在右侧似乎也有一个异常值存在
fig,ax=plt.subplots()
plt.scatter(x=train['TotalBsmtSF'],y=train['SalePrice'])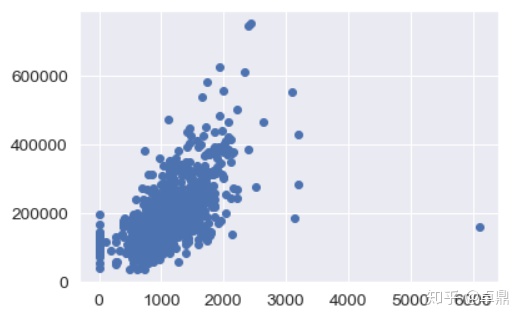
GarageArea含义为车库面积,可以看到车库面积和房价也存在一定的正相关关系
fig,ax=plt.subplots()
plt.scatter(x=train['GarageArea'],y=train['SalePrice'])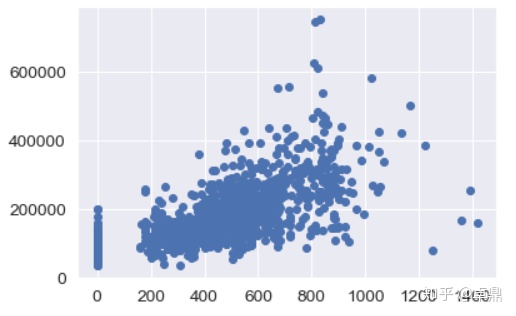
散点图可以查看连续性变量与房价之间的线性关系,下面用箱型图查看分类型变量与房价之间的关系
房屋质量OverallQual与房价之间的关系
fig,ax=plt.subplots(figsize=(8,6))
sns.boxplot(x=train['OverallQual'],y=train['SalePrice'])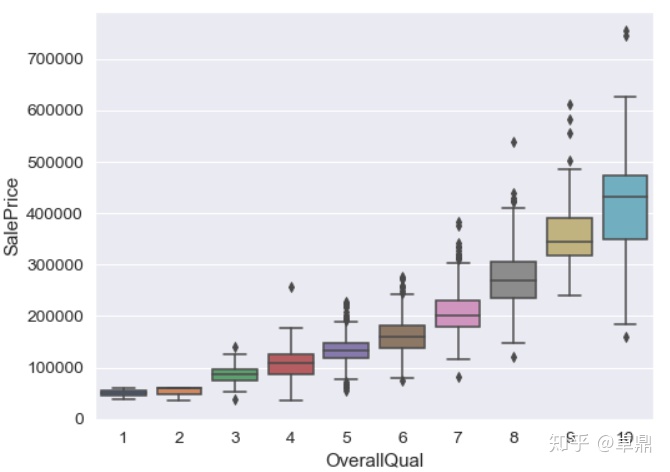
再看一下房屋的建造时间(YearBuilt)和价格的关系
fig,ax=plt.subplots(figsize=(16,8))
sns.boxplot(x=train['YearBuilt'],y=train['SalePrice'])
plt.xticks(rotation=90)
plt.show()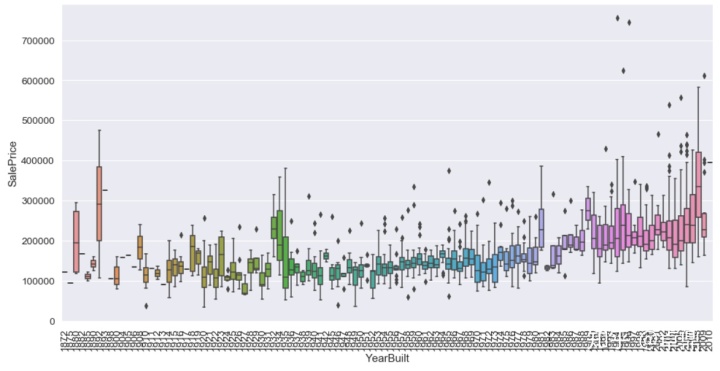
再看一下壁炉数量(Fireplaces)和房价的关系
fig,ax=plt.subplots(figsize=(16,8))
sns.boxplot(x=train['Fireplaces'],y=train['SalePrice'])
plt.xticks(rotation=90)
plt.show()
二、数据处理
通过可视化探索,我们对数据可以建立起基本的了解,下一步我们对数据的质量做一些处理。首先是异常值,我们已经发现在房屋面积和地下室面积这两个特征里面可能存在异常值,可以把它们删掉
删除房屋面积与房价关系散点图中的异常值
train = train.drop(train[(train['GrLivArea']>4000) & (train['SalePrice']<300000)].index)
plt.scatter(x=train['GrLivArea'],y=train['SalePrice'])
plt.xlabel('GrLivArea',fontsize=13)
plt.ylabel('SalePrice',fontsize=13)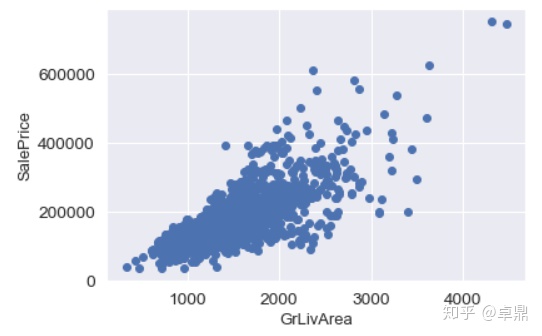
删除地下室面积与房价关系散点图中的异常值
train=train.drop(train[(train['TotalBsmtSF']>5000) & (train['SalePrice']<200000)].index)
plt.scatter(train['TotalBsmtSF'], train['SalePrice'])
plt.ylabel('SalePrice', fontsize=13)
plt.xlabel('TotalBsmtSF', fontsize=13)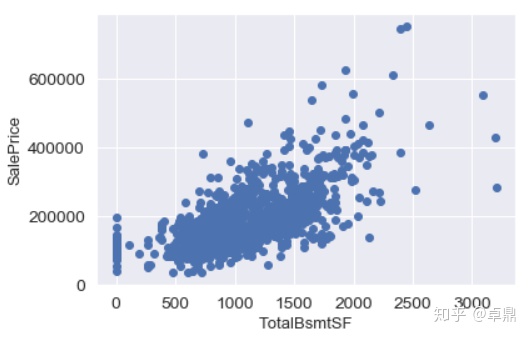
查看异常值的分布情况
all_data_na= (all_data.isnull().sum()/len(all_data))*100
all_data_na=all_data_na.drop(all_data_na[all_data_na==0].index).sort_values(ascending=False)[:30]
missing_data=pd.DataFrame({'Missing Ratio':all_data_na})
missing_data.head(50)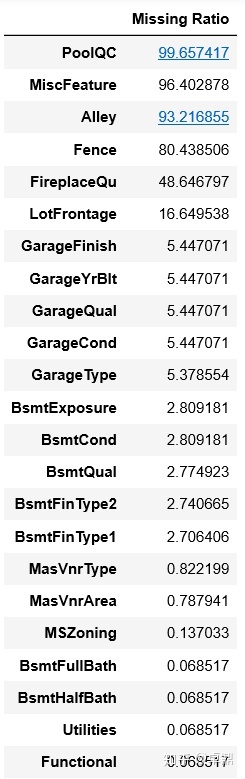
PoolQC、MiscFeature、Alley的缺失值都在90%以上,可以考虑直接删掉这些特征
all_data=all_data.drop('PoolQC',axis=1)
all_data=all_data.drop('MiscFeature',axis=1)
all_data=all_data.drop('Alley',axis=1)
all_data.shape
(2919, 76)Fence栅栏,FireplaceQu壁炉,如果数据缺失的话可能是代表房屋没有栅栏或壁炉, 可以用None填补缺失值,代表没有
all_data['Fence']=all_data['Fence'].fillna('None')
all_data['FireplaceQu']=all_data['FireplaceQu'].fillna('None')LotFrontage代表房屋前街道的长度,从现实中考虑,房屋前街道的长度可能是会和房屋所在一个街区的房屋相同,所以我们可以考虑位于同一个街区的LotFrontage的均值来填补缺失值
all_data['LotFrontage']=all_data.groupby('Neighborhood')['LotFrontage'].transform(lambda x:x.fillna(x.mean()))Garage相关的车库变量,注意到这些变量的缺失比例是完全相同的,缺失这些变量的房屋可能是没有车库,用None填充
for col in ('GarageType', 'GarageFinish', 'GarageQual', 'GarageCond'):
all_data[col]=all_data[col].fillna('None')同样猜测缺失值缺失的原因可能是因为房屋没有车库,对于连续型变量用0填充
for col in ('GarageYrBlt', 'GarageArea', 'GarageCars'):
all_data[col]=all_data[col].fillna(0)地下室相关连续变量,缺失同样认为房屋可能是没有地下室,用0填充
for col in ('BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF','TotalBsmtSF', 'BsmtFullBath', 'BsmtHalfBath'):
all_data[col]=all_data[col].fillna(0)地下室相关离散变量,同理用None填充
for col in ('BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2'):
all_data[col]=all_data[col].fillna('None')Mas为砖石结构相关变量,缺失值同样认为是没有砖石结构,用0和none填补缺失值
all_data["MasVnrType"] = all_data["MasVnrType"].fillna("None")
all_data["MasVnrArea"] = all_data["MasVnrArea"].fillna(0)MSZoning代表房屋所处的用地类型,查看一下不同取值的个数可以看到RL的取值最多
all_data.groupby('MSZoning')['Fence'].count().reset_index()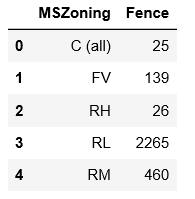
业务上讲,房屋应该都有所在用地类型,且应该是上面几个值中的一个,所以有缺失值可能不是因为房屋没有用地类型导致,对于这种情况我们就最好不要用None填充,可以考虑用众数
all_data['MSZoning']=all_data['MSZoning'].fillna(all_data['MSZoning'].mode()[0])对于其他缺失值处理的思路,和上面类似
all_data = all_data.drop(['Utilities'], axis=1)
all_data["Functional"] = all_data["Functional"].fillna("Typ")
all_data['Electrical'] = all_data['Electrical'].fillna(all_data['Electrical'].mode()[0])
all_data['KitchenQual'] = all_data['KitchenQual'].fillna(all_data['KitchenQual'].mode()[0])
all_data['Exterior1st'] = all_data['Exterior1st'].fillna(all_data['Exterior1st'].mode()[0])
all_data['Exterior2nd'] = all_data['Exterior2nd'].fillna(all_data['Exterior2nd'].mode()[0])
all_data['SaleType'] = all_data['SaleType'].fillna(all_data['SaleType'].mode()[0])
all_data['MSSubClass'] = all_data['MSSubClass'].fillna("None")再来看一下还有没有缺失值,发现已经没有了,到这我们就完成了对缺失值的处理
all_data_na = (all_data.isnull().sum() / len(all_data)) * 100
all_data_na = all_data_na.drop(all_data_na[all_data_na == 0].index).sort_values(ascending=False)
missing_data = pd.DataFrame({'Missing Ratio' :all_data_na})
missing_data.head()
拟合模型参数,并检验因变量SalePrice是否符合正太分布
sns.distplot(train['SalePrice'],kde=False,fit=norm) #绘制直方图和最大似然高斯分布拟合图
(mu,sigma)=norm.fit(train['SalePrice'])
print(f'mu={round(mu,2)} and sigma={round(sigma,2)}')
plt.legend([f'Normal Dist.(mu={round(mu,2)} and sigma={round(sigma,2)})' ],loc='best')
plt.ylabel('Frequency')
plt.title('SalePrice Distribution')
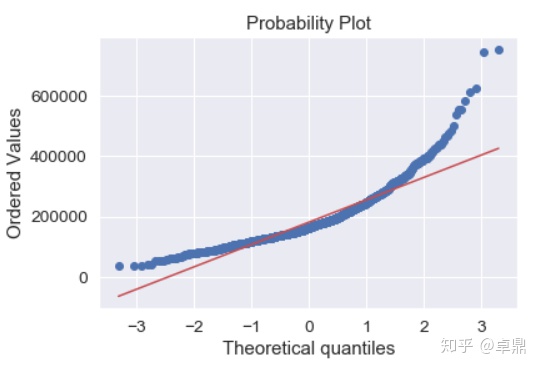
fig=plt.figure()
res=stats.probplot(train['SalePrice'],plot=plt)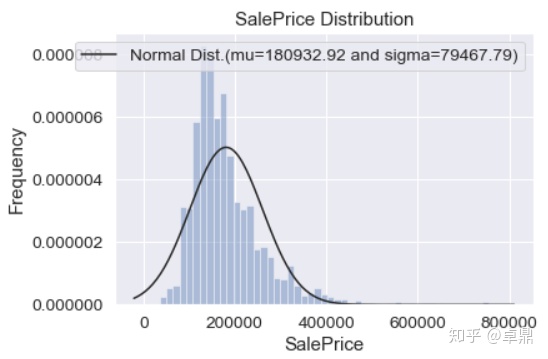
通过log转换,将非正态数据转换为正态数据,使得因变量SalePrice符合正态分布
train['SalePrice']=np.log1p(train['SalePrice'])
sns.distplot(train['SalePrice'],kde=False,fit=norm)
(mu,sigma)=norm.fit(train['SalePrice'])
print(f'mu={round(mu,2)} and sigma={round(sigma,2)}')
plt.legend([f'Normal Dist.(mu={round(mu,2)} and sigma={round(sigma,2)})' ],loc='best')
plt.ylabel('Frequency')
plt.title('SalePrice Distribution')
fig=plt.figure()
res=stats.probplot(train['SalePrice'],plot=plt)
三、特征工程
构造两个特征:房屋总面积(TotalSF),建造时间(YearBuilt_cut),并进行验证
all_data['TotalSF'] = all_data['TotalBsmtSF'] + all_data['1stFlrSF'] + all_data['2ndFlrSF']
all_data['YearBuilt_cut']=all_data['YearBuilt'].apply(lambda x:1 if x>1990 else 0)
tep=all_data[:ntrain]
tep['SalePrice']=y_train验证房屋总面积(TotalSF)与SalePrice的关系
plt.scatter(x=tep['TotalSF'],y=tep['SalePrice'])
plt.xlabel('TotalSF',fontsize=13)
plt.ylabel('SalePrice',fontsize=13)
plt.title('SalePrice VS TotalSF')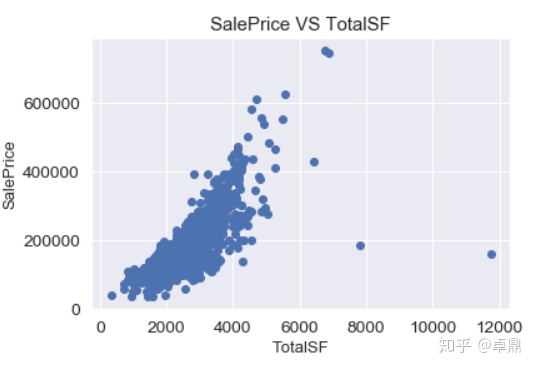
验证建筑年限(YearBuilt_cut)与SalePrice的关系
var = 'YearBuilt_cut'
data = pd.concat([tep['SalePrice'], tep[var]], axis=1)
sns.boxplot(x=var, y="SalePrice", data=data)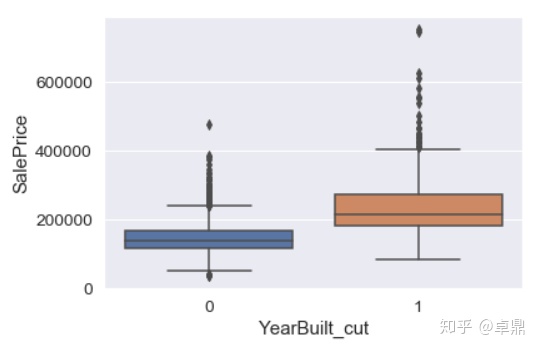
对离散型变量进行编码
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
cols = ('FireplaceQu', 'BsmtQual', 'BsmtCond', 'GarageQual', 'GarageCond',
'ExterQual', 'ExterCond','HeatingQC', 'KitchenQual', 'BsmtFinType1',
'BsmtFinType2', 'Functional', 'BsmtExposure', 'GarageFinish', 'LandSlope',
'LotShape', 'PavedDrive', 'Street', 'CentralAir', 'MSSubClass', 'OverallCond',
'YrSold', 'MoSold')
for c in cols:
lb1=LabelEncoder()
lb1.fit(all_data[c].values)
all_data[c]=lb1.transform(all_data[c].values)
all_data.shape
(2919, 219)对部分非有序型离散变量编码
all_data = pd.get_dummies(all_data)
all_data.shape
(2919, 219)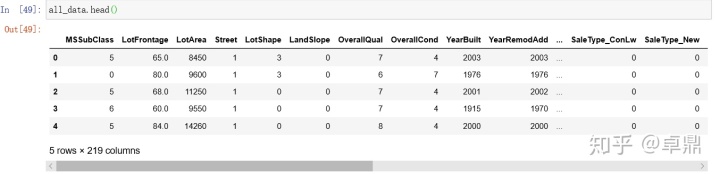
特征筛选,为避免多重共线性问题,删除皮尔森相关性系数大于0.9的特征
threshold=0.9
corr_matrix=all_data.corr().abs()
corr_matrix.head()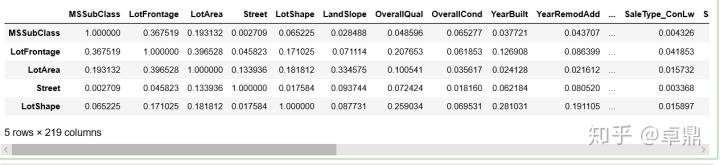
选择矩阵的上三角部分
upper=corr_matrix.where(np.triu(np.ones(corr_matrix.shape),1).astype(np.bool))
upper.head()
删除皮尔森相关性系数大于0.9的特征
to_drop=[column for column in upper.columns if any(upper[column]>threshold)]
all_data=all_data.drop(columns=to_drop)四、建模
导入一些所需要的包
from sklearn.linear_model import Ridge, RidgeCV, ElasticNet, LassoCV, LassoLarsCV
from sklearn.model_selection import cross_val_score
train = all_data[:ntrain]
test = all_data[ntrain:]
def rmse_cv(model):
rmse= np.sqrt(-cross_val_score(model, train, y_train, scoring="neg_mean_squared_error", cv = 5)) #neg_mean_squared_error(MSE、均方误差)
return(rmse)
model_ridge = Ridge()
alphas = [0.05, 0.1, 0.3, 1, 3, 5, 10, 15, 30, 50, 75]
cv_ridge = [rmse_cv(Ridge(alpha = alpha)).mean()
for alpha in alphas]
cv_ridge = pd.Series(cv_ridge, index = alphas)
cv_ridge.plot(title = "Validation - Just Do It")
plt.xlabel("alpha")
plt.ylabel("rmse")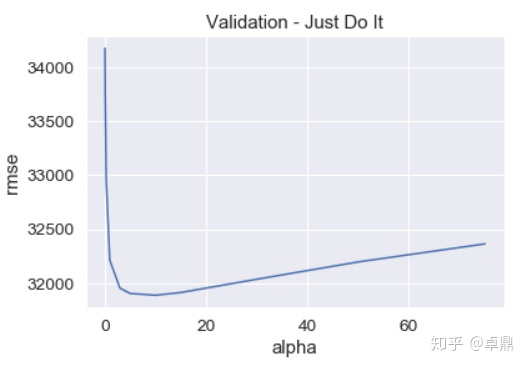
cv_ridge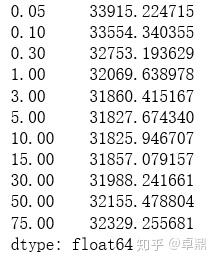
alpha参数用我们之前验证过的5,然后用训练集对模型进行训练
clf = Ridge(alpha=5)
clf.fit(train,y_train)
#最后对测试集进行预测
predict = clf.predict(test)
sub = pd.DataFrame()
sub['Id'] = test_ID
sub['SalePrice'] = predict
sub.head(10)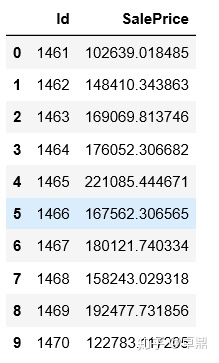














 433
433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









