






 本文通过Flink官方的SocketWindowWordCount示例,详细解析了一个Flink程序的执行过程,包括获取执行环境、加载数据、数据流操作等步骤。文章深入源码,解释了如何从socket读取数据、SourceFunction的工作原理,以及数据流转换如flatMap、keyBy、timeWindow和reduce的操作流程。
本文通过Flink官方的SocketWindowWordCount示例,详细解析了一个Flink程序的执行过程,包括获取执行环境、加载数据、数据流操作等步骤。文章深入源码,解释了如何从socket读取数据、SourceFunction的工作原理,以及数据流转换如flatMap、keyBy、timeWindow和reduce的操作流程。
在这之前已经介绍了如何在本地搭建Flink环境和如何创建Flink应用和如何构建Flink源码,这篇文章用官方提供的SocketWindowWordCount例子来解析一下一个常规Flink程序的每一个基本步骤。
示例程序
public class SocketWindowWordCount { public static void main(String[] args) throws Exception { // the host and the port to connect to final String hostname; final int port; try { final ParameterTool params = ParameterTool.fromArgs(args); hostname = params.has("hostname") ? params.get("hostname") : "localhost"; port = params.getInt("port"); } catch (Exception e) { System.err.println("No port specified. Please run 'SocketWindowWordCount " + "--hostname --port ', where hostname (localhost by default) " + "and port is the address of the text server"); System.err.println("To start a simple text server, run 'netcat -l ' and " + "type the input text into the command line"); return; } // get the execution environment final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // get input data by connecting to the socket DataStream text = env.socketTextStream(hostname, port, ""); // parse the data, group it, window it, and aggregate the counts DataStream windowCounts = text .flatMap(new FlatMapFunction() { @Override public void flatMap(String value, Collector out) { for (String word : value.split("s")) { out.collect(new WordWithCount(word, 1L)); } } }) .keyBy("word") .timeWindow(Time.seconds(5)) .reduce(new ReduceFunction() { @Override public WordWithCount reduce(WordWithCount a, WordWithCount b) { return new WordWithCount(a.word, a.count + b.count); } }); // print the results with a single thread, rather than in parallel windowCounts.print().setParallelism(1); env.execute("Socket Window WordCount"); } // ------------------------------------------------------------------------ /** * Data type for words with count. */ public static class WordWithCount { public String word; public long count; public WordWithCount() {} public WordWithCount(String word, long count) { this.word = word; this.count = count; } @Override public String toString() { return word + " : " + count; } }}上面这个是官网的SocketWindowWordCount程序示例,它首先从命令行中获取socket连接的host和port,然后获取执行环境、从socket连接中读取数据、解析和转换数据,最后输出结果数据。
每个Flink程序都包含以下几个相同的基本部分:
- 获得一个execution environment,
- 加载/创建初始数据,
- 指定此数据的转换,
- 指定放置计算结果的位置,
- 触发程序执行
Flink执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();Flink程序都是从这句代码开始,这行代码会返回一个执行环境,表示当前执行程序的上下文。如果程序是独立调用的,则此方法返回一个由createLocalEnvironment()创建的本地执行环境LocalStreamEnvironment。从其源码里可以看出来:
//代码目录:org/apache/flink/streaming/api/environment/StreamExecutionEnvironment.javapublic static StreamExecutionEnvironment getExecutionEnvironment() { if (contextEnvironmentFactory != null) { return contextEnvironmentFactory.createExecutionEnvironment(); } ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); if (env instanceof ContextEnvironment) { return new StreamContextEnvironment((ContextEnvironment) env); } else if (env instanceof OptimizerPlanEnvironment || env instanceof PreviewPlanEnvironment) { return new StreamPlanEnvironment(env); } else { return createLocalEnvironment(); }}获取输入数据
DataStream text = env.socketTextStream(hostname, port, "");这个例子里的源数据来自于socket,这里会根据指定的socket配置创建socket连接,然后创建一个新数据流,包含从套接字无限接收的字符串,接收的字符串由系统的默认字符集解码。当socket连接关闭时,数据读取会立即终止。通过查看源码可以发现,这里实际上是通过指定的socket配置来构造一个SocketTextStreamFunction实例,然后源源不断的从socket连接里读取输入的数据创建数据流。
//代码目录:org/apache/flink/streaming/api/environment/StreamExecutionEnvironment.java@PublicEvolvingpublic DataStreamSource socketTextStream(String hostname, int port, String delimiter, long maxRetry) { return addSource(new SocketTextStreamFunction(hostname, port, delimiter, maxRetry), "Socket Stream");}SocketTextStreamFunction的类继承关系如下:
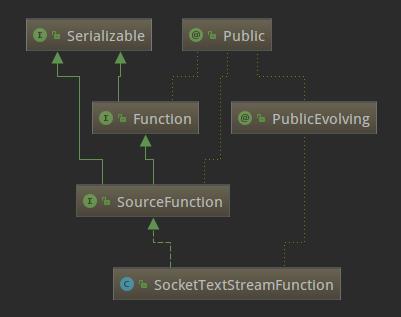
可以看出SocketTextStreamFunction是SourceFunction的子类,SourceFunction是Flink中所有流数据源的基本接口。SourceFunction的定义如下:
//代码目录:org/apache/flink/streaming/api/functions/source/SourceFunction.java@Publicpublic interface SourceFunction extends Function, Serializable { void run(SourceContext ctx) throws Exception; void cancel(); @Public interface SourceContext { void collect(T element); @PublicEvolving void collectWithTimestamp(T element, long timestamp); @PublicEvolving void emitWatermark(Watermark mark); @PublicEvolving void markAsTemporarilyIdle(); Object getCheckpointLock(); void close(); }}SourceFunction定义了run和cancel两个方法和SourceContext内部接口。
- run(SourceContex):实现数据获取逻辑,并可以通过传入的参数ctx进行向下游节点的数据转发。
- cancel():用来取消数据源,一般在run方法中,会存在一个循环来持续产生数据,cancel方法则可以使该循环终止。
- SourceContext:source函数用于发出元素和可能的watermark的接口,返回source生成的元素的类型。
了解了SourceFunction这个接口,再来看下SocketTextStreamFunction的具体实现(主要是run方法),逻辑就已经很清晰了,就是从指定的hostname和port持续不断的读取数据,按回车换行分隔符划分成一个个字符串,然后再将数据转发到下游。现在回到StreamExecutionEnvironment的socketTextStream方法,它通过调用addSource返回一个DataStreamSource实例。思考一下,例子里的text变量是DataStream类型,为什么源码里的返回类型却是DataStreamSource呢?这是因为DataStream是DataStreamSource的父类,下面的类关系图可以看出来,这也体现出了Java的多态的特性。
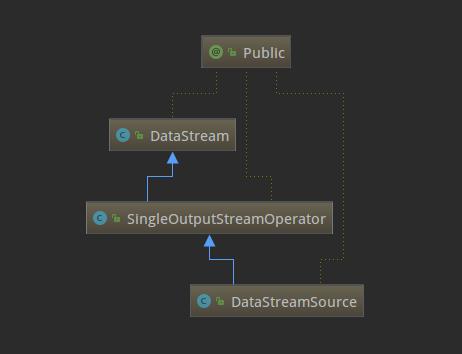
数据流操作
对上面取到的DataStreamSource,进行flatMap、keyBy、timeWindow、reduce转换操作。
DataStream windowCounts = text .flatMap(new FlatMapFunction() { @Override public void flatMap(String value, Collector out) { for (String word : value.split("s")) { out.collect(new WordWithCount(word, 1L)); } } }) .keyBy("word") .timeWindow(Time.seconds(5)) .reduce(new ReduceFunction() { @Override public WordWithCount reduce(WordWithCount a, WordWithCount b) { return new WordWithCount(a.word, a.count + b.count); } });这段逻辑中,对上面取到的DataStreamSource数据流分别做了flatMap、keyBy、timeWindow、reduce四个转换操作,下面说一下flatMap转换,其他三个转换操作读者可以试着自己查看源码理解一下。
先看一下flatMap方法的源码吧,如下。
//代码目录:org/apache/flink/streaming/api/datastream/DataStream.javapublic SingleOutputStreamOperator flatMap(FlatMapFunction flatMapper) { TypeInformation outType = TypeExtractor.getFlatMapReturnTypes(clean(flatMapper), getType(), Utils.getCallLocationName(), true); return transform("Flat Map














 219
219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









