





还是该更新一下了,今天登进公众号,发现多了3个观众,据说是宋帆推荐的,这里口头表扬一下。应该主要是Excel,虽然感觉基础基本上都有了,但是毕竟那是3年前(还是4年前,忘了)写的,那时候对Excel的理解水平还不高,虽然基本上都会用,但是没有一个整体的概念,也没有太多自己的理解,都是按部就班的写了一下用法,对他人来说读起来还是不那么友好,所以有想过从新再系统的更新一遍,看后面有不有需求嘛。其他偏也是,先把粗浅理解的写出来,等后面有自己新的体会和理解后,再系统的更新一下,带点自己个感性色彩感觉更美妙一些。
不久前找到一张图,就是下面这张,R里面大概就这几种数据类型,前面说了第一个向量,这一篇说一说矩阵。向量是一维的,矩阵是二维数据,这一下面这张图的颜色,向量、矩阵、数据颜色都是相同的,说明他们必须是相同的数据类型。而我们最常用的表格(数据框dataframe),就可以每一列存不同的数据类型,日常使用起来很方便。
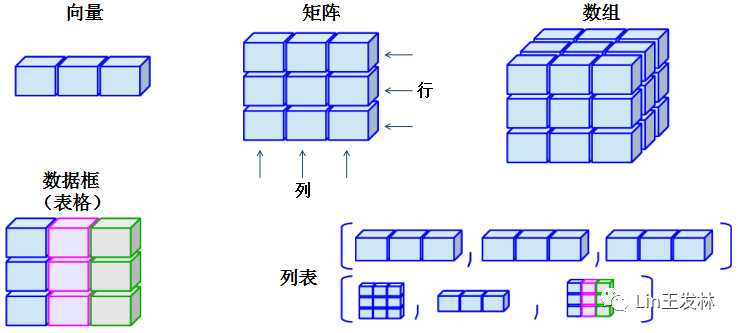
在R语言中,矩阵(matrix)是将数据按行和列组织数据的一种数据对象,相当于二维数组,可以用于描述二维的数据。与向量相似,矩阵的每个元素都拥有相同的数据类型。通常用列来表示来自不同变量的数据,用行来表示相同的数据。
【语法】↓
matrix(data = NA, #矩阵的元素,默认为NA,即未给出元素值的话,各项为NA nrow = 1, #矩阵的行数,默认为1 ncol = 1, #矩阵的列数,默认为1 byrow = FALSE, #元素是否按行填充,默认按列 dimnames = NULL) #以字符型向量表示的行名及列名【矩阵创建】
有时候你会发现,举例子的时候,用一些熟悉的、体系的名字,代入感会更强烈一些,所以就这样了。村上春树在挪威的森林里面多次赞美了菲兹杰拉德,虽然是接着渡边和永泽说的,这样让我更喜欢村上春树了。所以就用《了不起的盖茨比》里面的人物,感觉很亲切,虽然数据很简单。
mdata dimnames = list(c("财富需求","名誉需求","爱情需求"), c("盖茨比", "黛西", "尼克", "汤姆", "贝克")))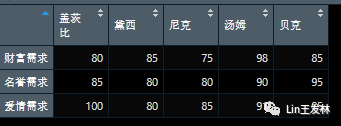
第二种方式,就是通过相同数据类型的向量合并就行了。
a b m2 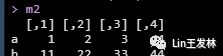
m3 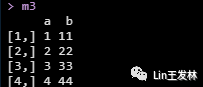
【矩阵元素访问】
方式都差不多,都是通过位置应用或者行列名字引用。
> mdata[3,1][1] 100> mdata[,1]财富需求 名誉需求 爱情需求 80 85 100 > mdata[3,]盖茨比 黛西 尼克 汤姆 贝克 100 80 85 91 85> mdata[,'盖茨比']财富需求 名誉需求 爱情需求 80 85 100 > mdata['财富需求',]盖茨比 黛西 尼克 汤姆 贝克 80 85 75 98 85 > mdata['爱情需求','盖茨比'][1] 100> mdata[,-4] 盖茨比 黛西 尼克 贝克财富需求 80 85 75 85名誉需求 85 80 80 95爱情需求 100 80 85 85> mdata[-2,-4] 盖茨比 黛西 尼克 贝克财富需求 80 85 75 85爱情需求 100 80 85 85> mdata[c(1,3),c(1,2,5)] 盖茨比 黛西 贝克财富需求 80 85 85爱情需求 100 80 85> mdata[c("财富需求","爱情需求"),c("盖茨比","尼克","黛西")] 盖茨比 尼克 黛西财富需求 80 75 85爱情需求 100 85 80【矩阵元素修改】
> mdata[1,1] > mdata 盖茨比 黛西 尼克 汤姆 贝克财富需求 83 85 75 98 85名誉需求 85 80 80 90 95爱情需求 100 80 85 91 85> mdata[,c("贝克")] > mdata 盖茨比 黛西 尼克 汤姆 贝克财富需求 83 85 75 98 90名誉需求 85 80 80 90 90爱情需求 100 80 85 91 88【矩阵元素删除】
> m1 > m1 盖茨比 黛西 尼克 贝克财富需求 83 85 75 90名誉需求 85 80 80 90爱情需求 100 80 85 88> m2 > m2 盖茨比 黛西 尼克 贝克财富需求 83 85 75 90爱情需求 100 80 85 88【矩阵合并】
行合并
> 文学需求 > rbind(mdata,文学需求) 盖茨比 黛西 尼克 汤姆 贝克财富需求 83 85 75 98 90名誉需求 85 80 80 90 90爱情需求 100 80 85 91 88文学需求 90 50 92 10 45列合并
> Wilson > cbind(mdata,Wilson) 盖茨比 黛西 尼克 汤姆 贝克 Wilson财富需求 83 85 75 98 90 95名誉需求 85 80 80 90 90 50爱情需求 100 80 85 91 88 75【矩阵运算】
求矩阵各列的和
> colSums(mdata)盖茨比 黛西 尼克 汤姆 贝克 268 245 240 279 268求矩阵各行的和
> rowSums(mdata)财富需求 名誉需求 爱情需求 431 425 444 求矩阵各列的均值
> colMeans(mdata) 盖茨比 黛西 尼克 汤姆 贝克 89.33333 81.66667 80.00000 93.00000 89.33333 求矩阵各行的均值
> rowMeans(mdata)财富需求 名誉需求 爱情需求 86.2 85.0 88.8 将矩阵转置
> t(mdata) 财富需求 名誉需求 爱情需求盖茨比 83 85 100黛西 85 80 80尼克 75 80 85汤姆 98 90 91贝克 90 90 88取矩阵的对角元素
> diag(mdata)[1] 83 80 85求矩阵的行数
> nrow(mdata)[1] 3求矩阵的列数
> ncol(mdata)[1] 5求矩阵的行维与列维
> dim(mdata)[1] 3 5求两个矩阵的内积
第一个矩阵的列数应与第二个矩阵的行数相同
m1 m2 m1 %*% m2 [,1] [,2][1,] 11 7[2,] 16 12求解方阵的行列式
> det(m1)[1] -2> det(m2)[1] -10求矩阵的逆阵
> ms <- solve(m1)> ms %*% m1 [,1] [,2][1,] 1 0[2,] 0 1> m1 %*% ms [,1] [,2][1,] 1 0[2,] 0 1> solve(m2) [,1] [,2][1,] -0.1 0.4[2,] 0.3 -0.2求矩阵的特征值和特征向量
> A = matrix(c(1,1,1,1,1,1,-1,-1,1,-1,1,-1,1,-1,-1,1),nrow = 4)> vv > vveigen() decomposition$values[1] 2 2 2 -2$vectors [,1] [,2] [,3] [,4][1,] 0.0000000 0.0000000 0.8660254 0.5[2,] -0.5773503 -0.5773503 0.2886751 -0.5[3,] -0.2113249 0.7886751 0.2886751 -0.5[4,] 0.7886751 -0.2113249 0.2886751 -0.5> A * vv$vectors [,1] [,2] [,3] [,4][1,] 0.0000000 0.0000000 0.8660254 0.5[2,] -0.5773503 -0.5773503 -0.2886751 0.5[3,] -0.2113249 -0.7886751 0.2886751 0.5[4,] 0.7886751 0.2113249 -0.2886751 -0.5> vv$values * vv$vectors [,1] [,2] [,3] [,4][1,] 0.0000000 0.0000000 1.7320508 1[2,] -1.1547005 -1.1547005 0.5773503 -1[3,] -0.4226497 1.5773503 0.5773503 -1[4,] -1.5773503 0.4226497 -0.5773503 1【数组】
> a3 1:> a3, , 1 [,1] [,2] [,3] [,4][1,] 1 3 5 7[2,] 2 4 6 8, , 2 [,1] [,2] [,3] [,4][1,] 9 11 13 15[2,] 10 12 14 16, , 3 [,1] [,2] [,3] [,4][1,] 17 19 21 23[2,] 18 20 22 24name"盖茨比", needs"财富需求",times'开始',GATSBYarray(sample( dim=c(5,3,2), dimnames=list(name,needs,times))GATSBY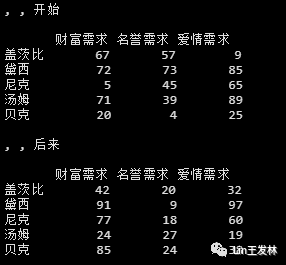
> GATSBY[1:2,3,] 开始 后来盖茨比 9 32黛西 85 97> GATSBY[,,1] 财富需求 名誉需求 爱情需求盖茨比 67 57 9黛西 72 73 85尼克 5 45 65汤姆 71 39 89贝克 20 4 25> GATSBY[1,,2] > GATSBY, , 开始 财富需求 名誉需求 爱情需求盖茨比 67 57 9黛西 72 73 85尼克 5 45 65汤姆 71 39 89贝克 20 4 25, , 后来 财富需求 名誉需求 爱情需求盖茨比 65 60 100黛西 91 9 97尼克 77 18 60汤姆 24 27 19贝克 85 24 38
End
















 1834
1834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









