






 本文介绍了如何爬取雀魂牌谱屋的牌谱数据来训练日麻AI。首先,通过分析页面结构和网络请求,批量获取牌谱ID。然后,模拟WebSocket通信,构造包含牌谱ID的请求,实现与雀魂服务器的交互,获取完整牌谱信息。最后,详细描述了登录、发送牌谱请求的流程和JavaScript实现。
本文介绍了如何爬取雀魂牌谱屋的牌谱数据来训练日麻AI。首先,通过分析页面结构和网络请求,批量获取牌谱ID。然后,模拟WebSocket通信,构造包含牌谱ID的请求,实现与雀魂服务器的交互,获取完整牌谱信息。最后,详细描述了登录、发送牌谱请求的流程和JavaScript实现。
牌谱AI
牌谱爬取
概述
为了训练日麻AI,我们首先需要爬取足量的现实牌谱作为训练数据。
雀魂牌谱屋(https://amae-koromo.sapk.ch/ )是一个第三方维护的牌谱收集网站,收集了2019年8月23日开始的对局数据。网页如下图所示,可以看到,我们希望可以爬取一位的牌谱作为训练数据,从而使得我们可以更好地模拟一位玩家的行为,做出更好的决策。
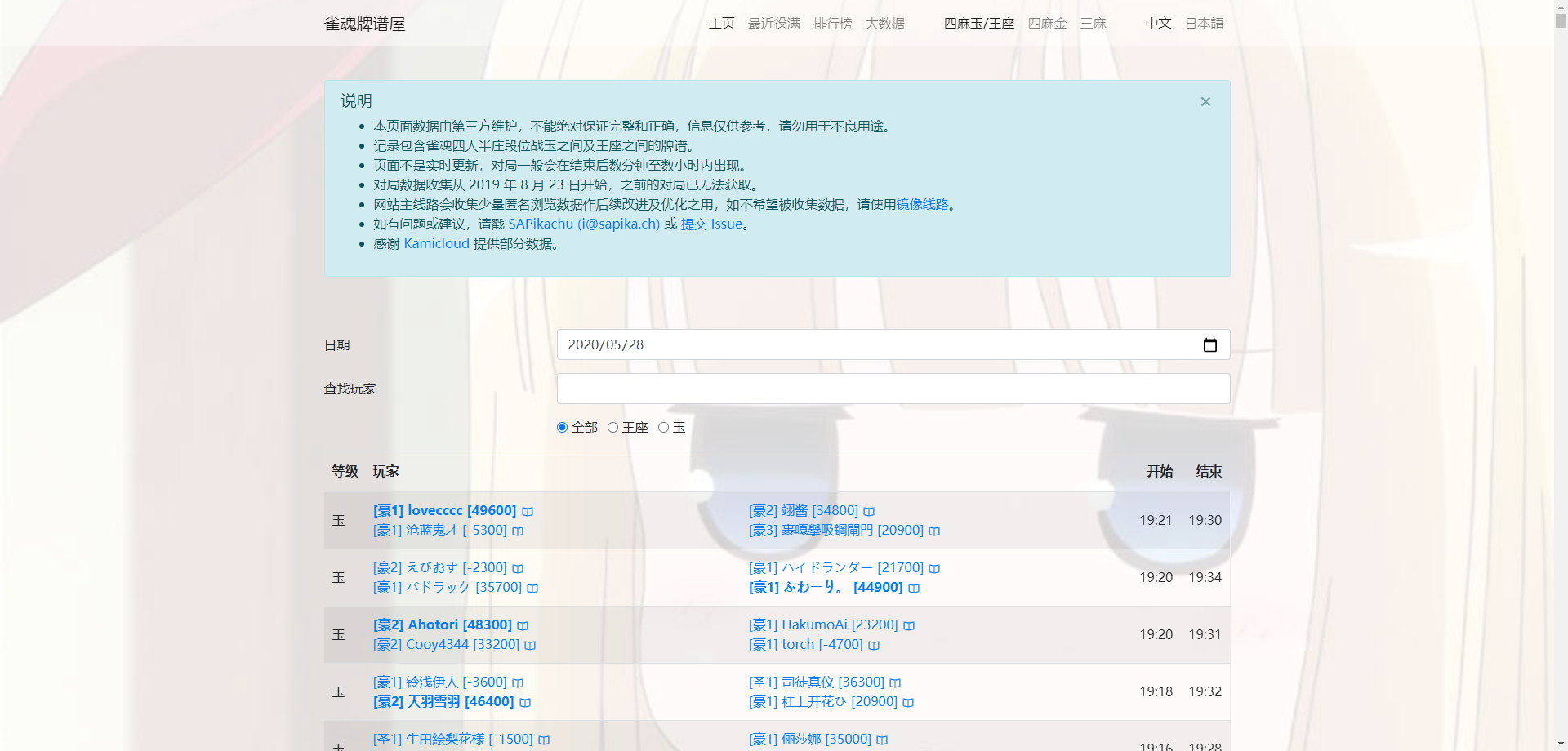
查看元素可以看到一个典型的牌谱链接,包含了一个较长的牌谱id。
点击链接之后,发现会首先进行登录,然后会逐步加载到牌谱查看界面,通过chrome浏览器的开发者工具我们可以发现,雀魂的数据通信是通过websocket实现,客户端与服务器连接之后,客户端会通过不断地发送二进制信息实现与服务器的通信,从而获得用户状态,牌谱等信息。下图展示了获取牌谱的信息,可以看到,信息中包含了“fetchGameRecord”用以标识信息的类型,同时也包含了之前提到的牌谱id。
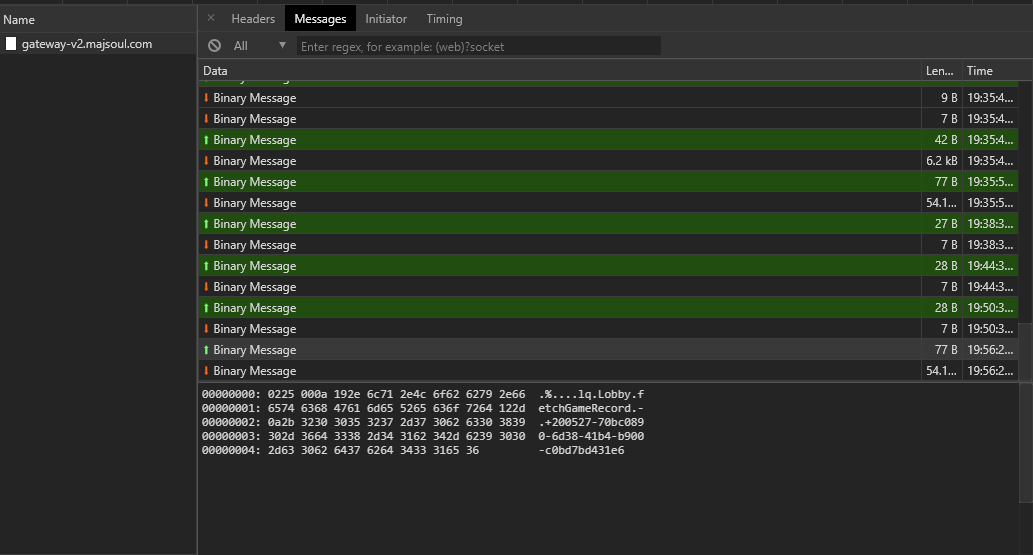
因此,我们可以确定整体的爬取过程。首先,从雀魂牌谱屋中批量获取牌谱id,然后,通过模拟浏览器的行为与服务器进行通信,获取牌谱id对应的牌谱信息,最后解析服务器返回的牌谱信息,保存为易于处理和理解的形式。
批量获取牌谱id
雀魂牌谱屋的数据是采用流式加载的形式,向下滑动可以加载更多的数据。随意地向下滑动并打开开发者工具,我们可以清晰地看到大量极为一致的请求,显然是用于请求牌谱数据的请求,不难看出请求共计包含三个参数,其中两个参数为skip和limit,skip表示返回时跳过前多少条数据,limit表示需要返回多少条数据,如果不设置这两个参数则默认返回前100条数据。第三个参数为一长串数字,显然是用于标识时间。为了得到表示时间的具体规律,调节时间并查看不同的请求可以看出,2020年5月28日对应“1590595200000 ”,2020年5月27日对应“1590508800000”,不难发现,该字符串是单位为毫秒的时间戳。
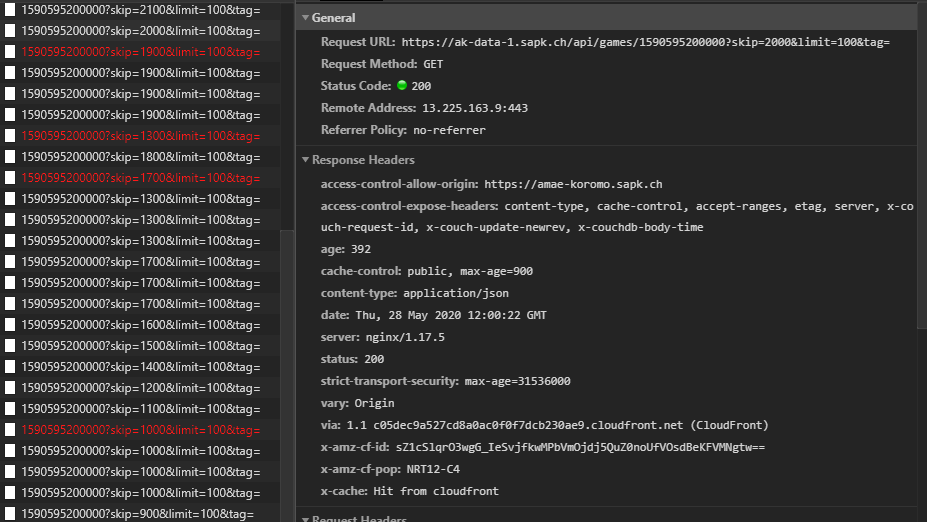
因此,可以通过下面的程序获取需要的牌谱id列表。
import requests
import time
import json
def date_to_timestamp(date, format_string="%Y-%m-%d %H:%M:%S"):
time_array = time.strptime(date, format_string)
time_stamp = int(time.mktime(time_array)) * 1000
return str(time_stamp)
def get_data_by_date(date):
print("开始爬取" + date + "的牌谱id列表。")
time_stamp = date_to_timestamp(date)
count_url = "https://ak-data-1.sapk.ch/api/count/" + time_stamp
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/71.0.3578.98 Safari/537.36'}
try:
req = requests.get(count_url, headers=headers)
data = json.loads(req.text)
count = data["count"]
print("共计包含牌谱数据" + str(count) + "条。")
except:
return []
date_data = []
for i in range(int(count / 100)):
try:
url = "https://ak-data-1.sapk.ch/api/games/" + time_stamp + "?skip=" + str(i*100) + "&limit=100"
req = requests.get(url, headers=headers)
data = json.loads(req.text)
date_data += data
except:
pass
return date_data
加上try是因为远端请求的链接有时候不太稳定,会返回错误的结果,而我们并不要求数据的连续性,因此对于返回错误的就直接忽略,而不重新进行请求。
尝试获取2020年5月1日至2020年5月28日的牌谱id列表,最终得到了103200条牌谱数据。
模拟浏览器进行ws通信
WebSocket是一种在单个TCP协议上进行的协议,浏览器和服务器之间只需要完成一次握手,两者之间就可以实现持久性连接,并且进行双向数据传输。
因此我们只需要在本地搭建一个WebSocket客户端与雀魂服务器实现通信,之后不断将牌谱id发送给服务器获取牌谱数据。
之前我们提到,浏览牌谱时,在chrome浏览器的开发者工具中可以看到发送和接受的WebSocket消息,并且支持以hex形式进行复制。所以,我们首先创建一个html文件,同样用WebSocket形式进行连接,将复制得到hex字符串转换为二进制数组发送给服务器,并实时接受服务器的反馈。
websocket测试var ws;
window.onload = function() {
if ("WebSocket" in window) {
alert("您的浏览器支持 WebSocket!");
ws = new WebSocket("wss://gateway-v2.majsoul.com:5201/");
ws.onmessage = function (evt) {
var received_msg = evt.data;
console.log(received_msg);
alert("数据已接收...");
};
ws.onclose = function() {
alert("连接已关闭...");
};
}
else {
alert("您的浏览器不支持 WebSocket!");
}
}
function WebSocketTest() {
text = document.getElementById("text").value;
buffer = new Uint8Array(text.match(/[\da-f]{2}/gi).map(function (h) {
return parseInt(h, 16)
})).buffer;
ws.send(buffer);
alert("数据发送中...");
}
复制的hex字符串:
运行 WebSocket
直接将请求牌谱的字符串发送到服务器,发现服务器会返回结果,但返回结果为空。考虑到点击牌谱链接时需要首先进行登录,因此猜测服务器需要首先接收到登录信息才能够接受获取牌谱的请求。从所有二进制请求中找到标识了”lq.Lobby.oauth2Login"的请求,同样复制,在请求牌谱的字符串之前发送,发现服务器返回了非空的结果。因此,我们只需要构造包含指定牌谱id的hex字符串就可以实现牌谱查询。
hex字符串可以转换为utf-8格式,下图展示了具体的转换结果,但是由于直接转换前半部分产生了乱码,因此我们可以直接将第三行以后的牌谱id替换并重新转换为hex字符串。

这里为将utf-8转换16进制字符串的js函数。
function bin2hex(str) {
var ret = '';
var r = /[0-9a-zA-Z_.~!*()]/;
for (var i = 0, l = str.length; i < l; i++) {
if (r.test(str.charAt(i))) {
ret += str.charCodeAt(i).toString(16);
} else {
ret += encodeURIComponent(str.charAt(i)).replace(/%/g, '');
}
}
return ret;
}
以上图为例,bin2hex("200527-70bc0890-6d38-41b4-b900-c0bd7bd431e6")的结果为"323030353237-3730626330383930-36643338-34316234-62393030-633062643762643433316536",可以看到,只需要用"2d"替换"-"就可以得到和解码完全一直的结果,因此我们只需要将3230之前的字符与uid转换之后的结果进行拼接,就可以得到新的获取牌谱请求。实际处理的时候还需要利用async/await将各部分的操作转换为同步操作。
var ws = new WebSocket("wss://gateway-v2.majsoul.com:5201/");
ws.onopen = function() {
console.log("连接建立。");
};
ws.onclose = function() {
console.log("连接关闭。")
};
function send_message(ws, msg) {
ws.send(msg);
}
function receive_message(ws) {
return new Promise((resolve) => {
ws.onmessage = function(e) {
resolve(e.data);
};
});
}
function hex2array(hex_string) {
return new Uint8Array(hex_string.match(/[\da-f]{2}/gi).map(function (h) {
return parseInt(h, 16)
})).buffer;
}
function login() {
hex_text = "登录字符串";
buffer = hex2array(hex_text);
send_message(ws, buffer);
}
async function get_paipu(uid) {
hex_text = "0221000a192e6c712e4c6f6262792e666574636847616d655265636f7264122d0a2b" + bin2hex(uid);
hex_text = hex_text.replace(new RegExp(/(\-)/g),'2d');
buffer = hex2array(hex_text);
send_message(ws, buffer);
result = await receive_message(ws);
return result;
}
function sleep (time) {
return new Promise((resolve) => setTimeout(resolve, time));
}
await sleep(500);
paipu_id = "200605-211ffb8e-16ff-4d1a-a4be-c0aaac794896"
login();
await get_paipu(paipu_id);

















 4328
4328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









