







数据源相关的技术栈有:
目录
一、Hadoop
1、简介:
Hadoop是在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,核心是HDFS和MapReduce。
HDFS是一个分布式文件系统,引入存放文件元数据信息的服务器Namenode和实际存放数据的服务器Datanode,对数据进行分布式存储和读取;
MapReduce是一个计算框架,核心思想是把计算任务分配给集群内的服务器里执行。通过对计算任务的拆分(Map计算/Reduce计算)再根据任务调度器(JobTracker)对任务进行分布式计算。
2、组件:
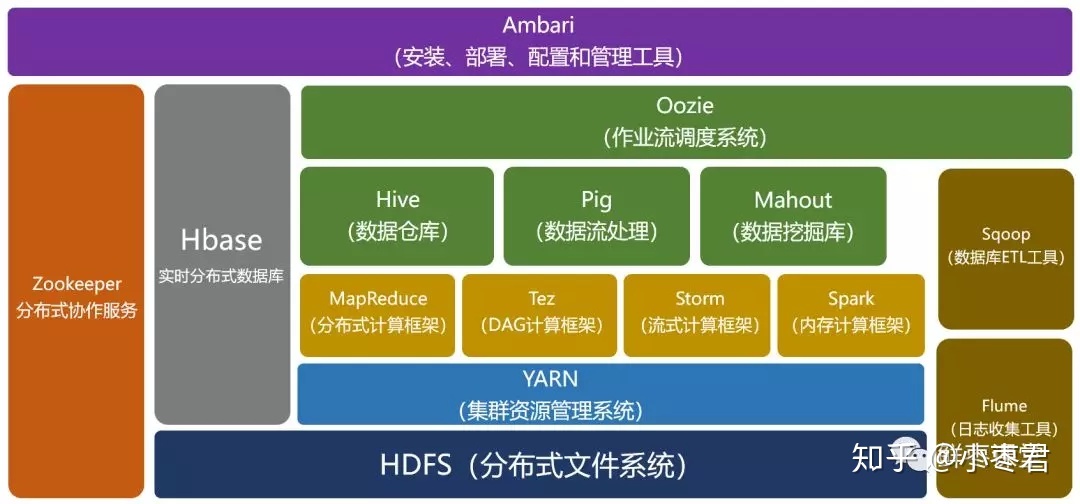
重要组件有:
HBase:来源于Google的BigTable;是一个高可靠性、高性能、面向列、可伸缩的分布式数据库。
Hive:是一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Pig:是一个基于Hadoop的大规模数据分析工具,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。
ZooKeeper:来源于Google的Chubby;它主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度。
Ambari:Hadoop管理工具,可以快捷地监控、部署、管理集群。
Sqoop:用于在Hadoop与传统的数据库间进行数据的传递。
Mahout:一个可扩展的机器学习和数据挖掘库。
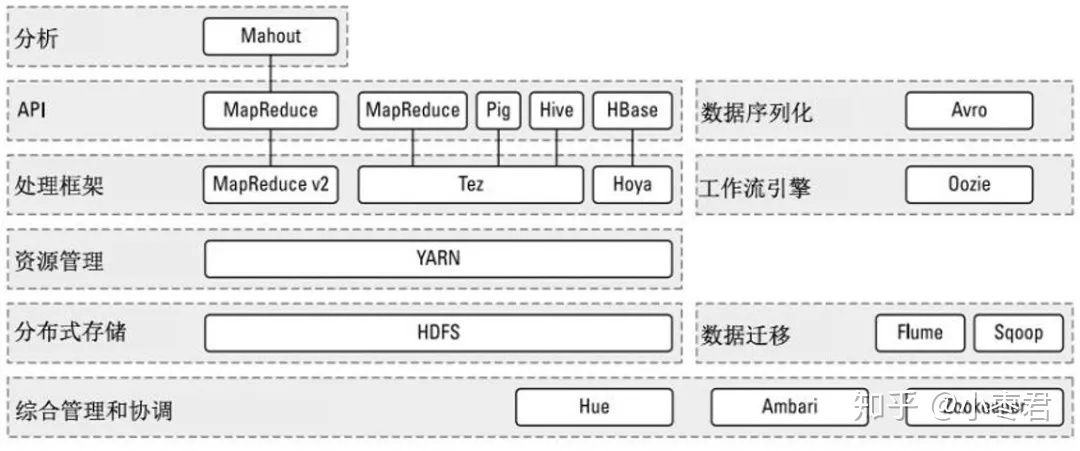
3、特性:
高可靠性和高容错性:Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
高扩展性:Hadoop是在可用的计算机集群间分配数据并完成计算任务的,这些集群可以方便地进行扩展。说白了,想变大很容易。
高效性:Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
低成本:Hadoop是开源的,依赖于社区服务,使用成本比较低。
4、HDFS:
由NameNode名称节点、DataNode数据节点、Client客户机组成;
写入流程:
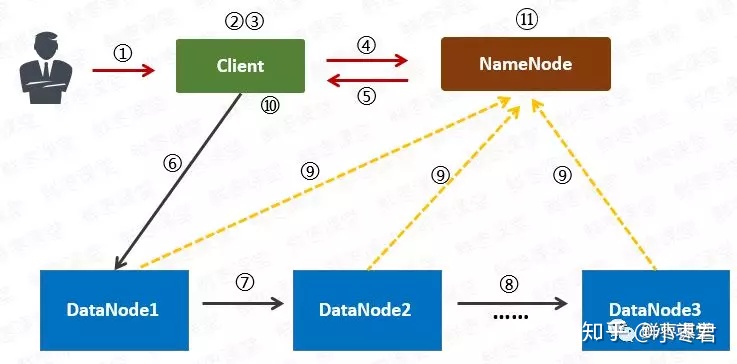
读取流程:
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3538
3538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









