






RDD与DataSet的区别
二者都是由元素构成的分布式数据集合
1. 对于spark来说,并不知道RDD元素的内部结构,仅仅知道元素本身的类型,只有用户才了解元素的内部结构,才可以进行处理、分析;但是spark知道DataSet元素的内部结构,包括字段名、数据类型等。这为spark对数据操作进行优化奠定了基础。
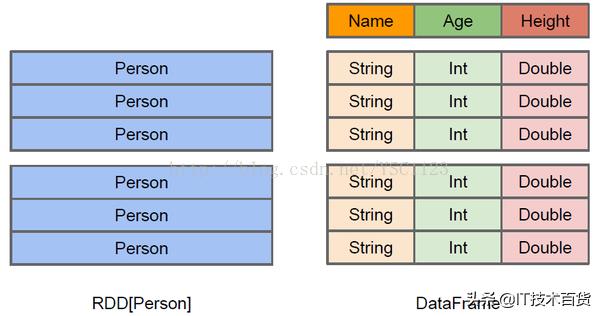
rdd&dataSet
2. DataSet序列化效率比RDD高很多,原因有二:其一是了解数据内部结构,不需要每一个元素都序列话字段名与数据类型,仅仅通过scheme就可以提供此信息;其二是引入了堆外内存,这在内存管理上可以更灵活自由,可以有效避免引起频繁的GC。
3. 由于spark了解数据内部结构,并且引入了endcoder机制,所以在内存中以二进制的形式存储,区别于RDD以jvm对象的形式存储,所以在shuffle过程中不需要序列化与反序列化,另外也有提到在排序过程中不需要反序列化,个人觉得是整体元素不需要反序列化,但是对于排序所依据的字段可能仍然需要反序列化,但序列化的消耗肯定比整体反序列化要小很多。
4. dataSet可与SparkSql结合使用。RDD具有只读性,一般都是基于已有RDD创建新的RDD,SparkSql引擎结合DataSet,可以在一定程度上牺牲内部不变性(但对用户来说是无感知的),来减少对象的创建,避免频繁GC。另外Sql引擎本身也有很多的优化点。
5. dataSet支持更多的数据存取格式,如:csv、json、parquet、jdbc等。
总之,对于结构化数据,dataset比rdd在cpu、内存、任务耗时上都有很大的性能提升。但对于非结构化数据,往往还是使用RDD处理。

DataSet和DataFrame的区别
DataFrame是DataSet的一个特例,spark源码定义如下:
type DataFrame = Dataset[Row]
DataFrame更像是介于DataSet与RDD之间的一种类型,为什么这么说呢?DataSet是强类型的数据集,但是DataFrame不是,只有通过解析才能获取各个字段的值,无法直接获取每一列的值。
df.filter(row => row.getAs[String](0).startsWith("#"))
实际上是先有的dataFrame(spark1.3.0)引入的,应该是基于RDD进行了一系列优化。之后再spark1.6引入了DataSet。从时间维度上来看,dataFrame也更像是rdd到DataSet的一个过度。
相关文章:
spark系列:spark core 数据交互技术点(数据模型)
spark系列:spark生态组件与应用场景















 2200
2200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









