







前言: TensorFlow简介
TensorFlow 在新款 NVIDIA Pascal GPU 上的运行速度可提升高达 50%,并且能够顺利跨 GPU 进行扩展。 如今,训练模型的时间可以从几天缩短到几小时
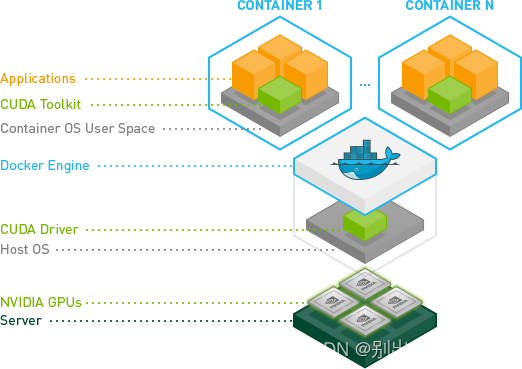
TensorFlow 使用优化的 C++ 和 NVIDIA® CUDA® 工具包编写,使模型能够在训练和推理时在 GPU 上运行,从而大幅提速
TensorFlow GPU 支持需要多个驱动和库。为简化安装并避免库冲突,建议利用 GPU 支持的 TensorFlow Docker 镜像。此设置仅需要 NVIDIA GPU 驱动并且安装 NVIDIA Docker。用户可以从预配置了预训练模型和 TensorFlow 库支持的 NGC (NVIDIA GPU Cloud) 中提取容器
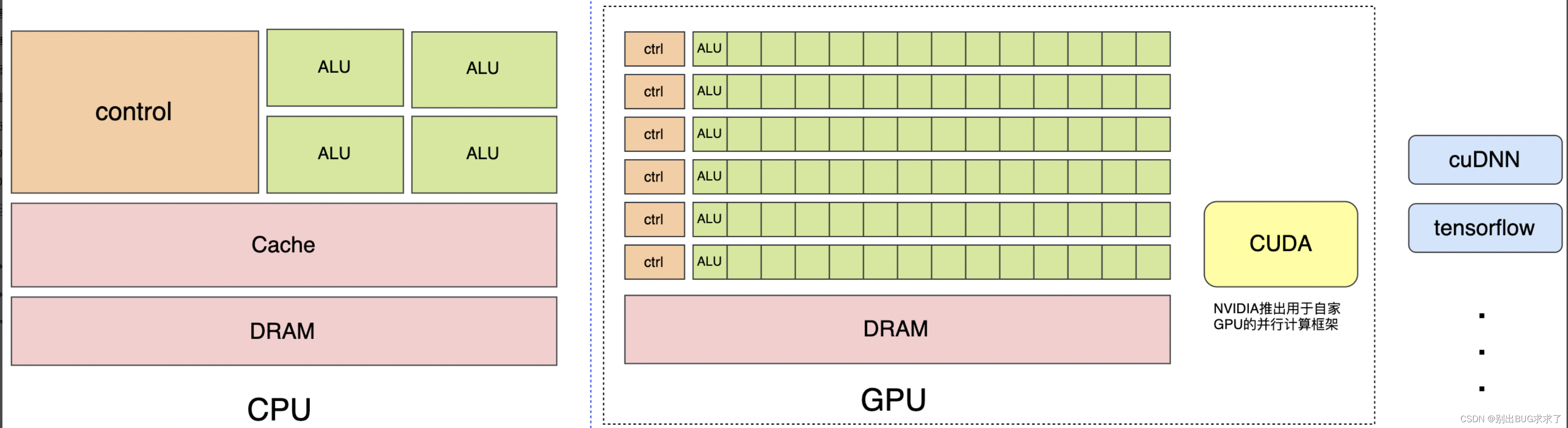
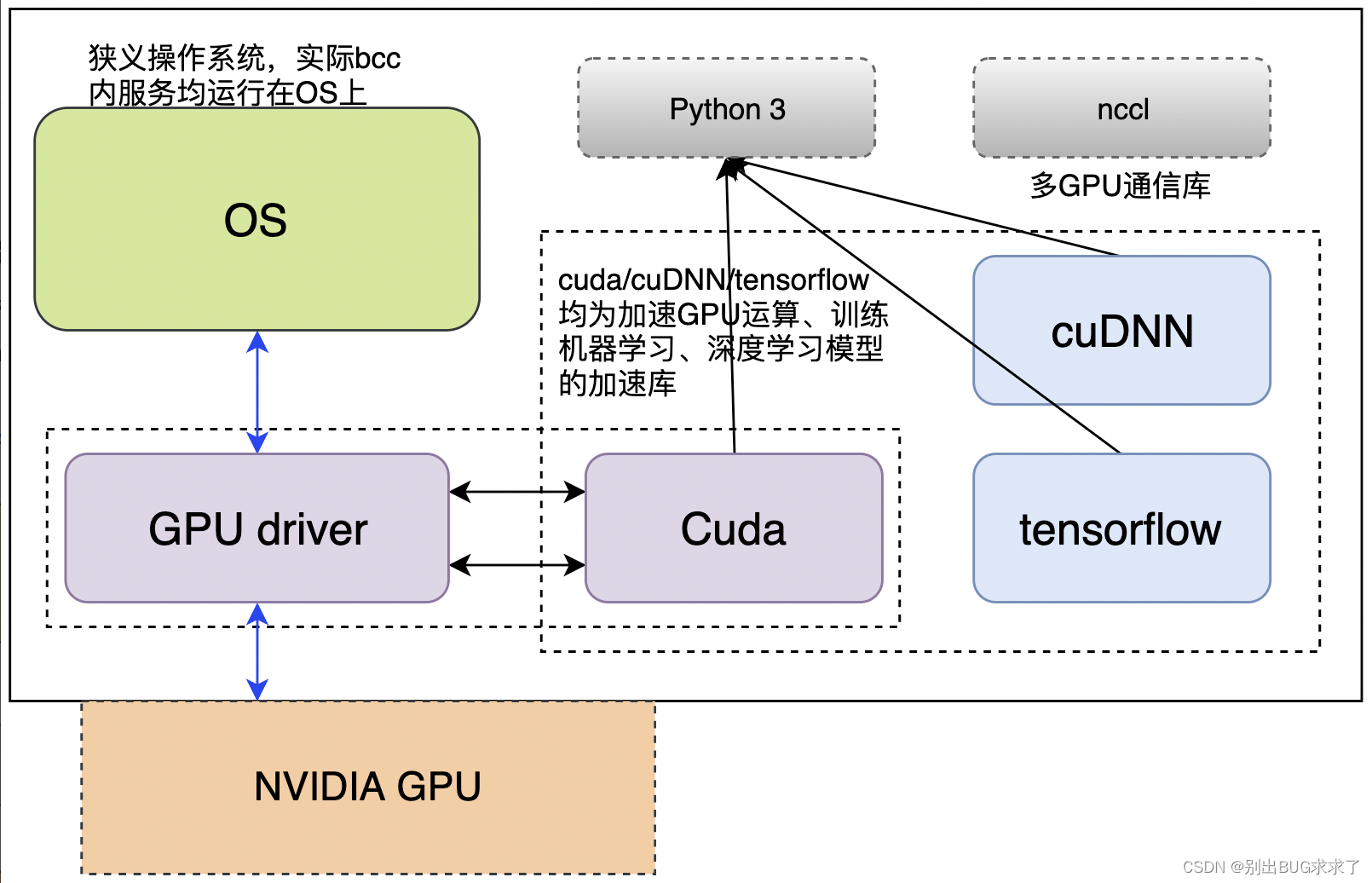
CPU擅长逻辑控制、串行计算,而GPU擅长高强度计算、并行计算。CUDA是NVIDIA推出用于自家GPU的并行计算框架,cuDNN & tensorflow是一系列机器学习,深度学习库,用于训练机器学习、深度学习模型
2. 依赖环境准备
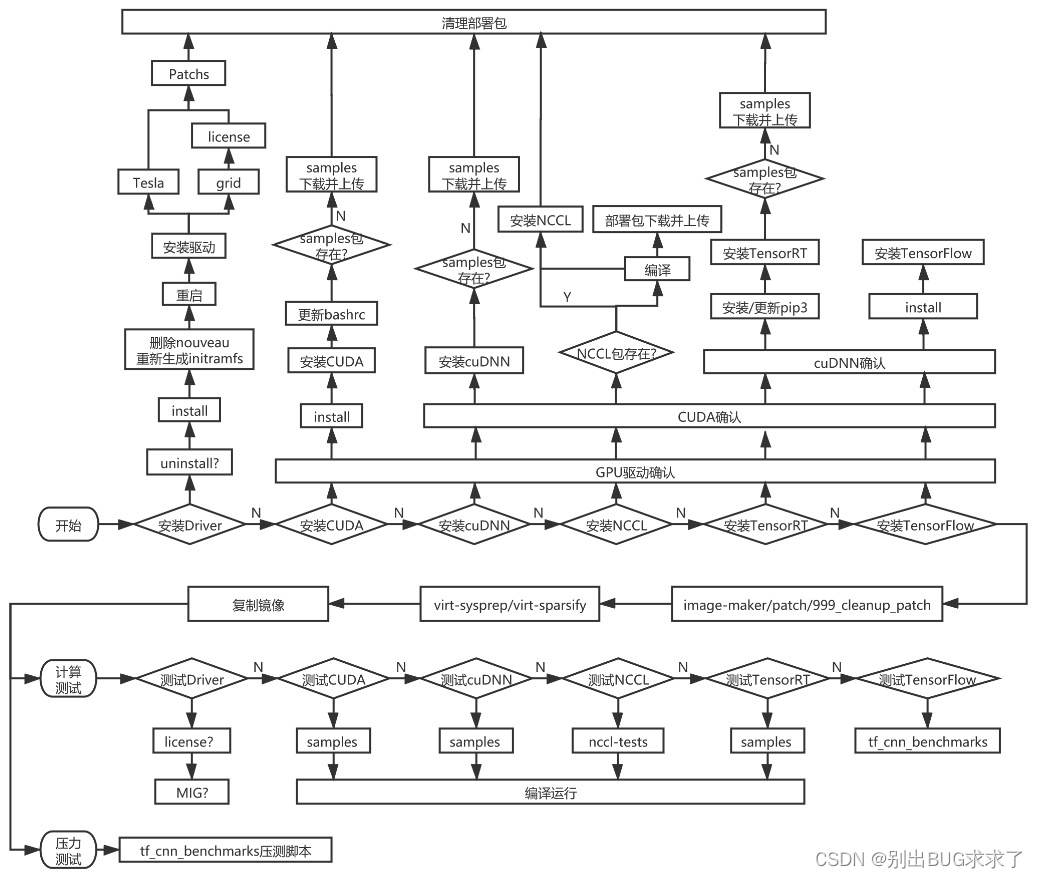
选取centos7.3作为基础操作系统镜像,选取适配驱动:Nvidia
GPU部署预装机器
深度学习框架:cuda、cudnn、tensorflow
由于cuda、cudnn、tensorflow等机器学习、深度学习框架,依赖python3,需要在centos7.3操作系统中集成python3
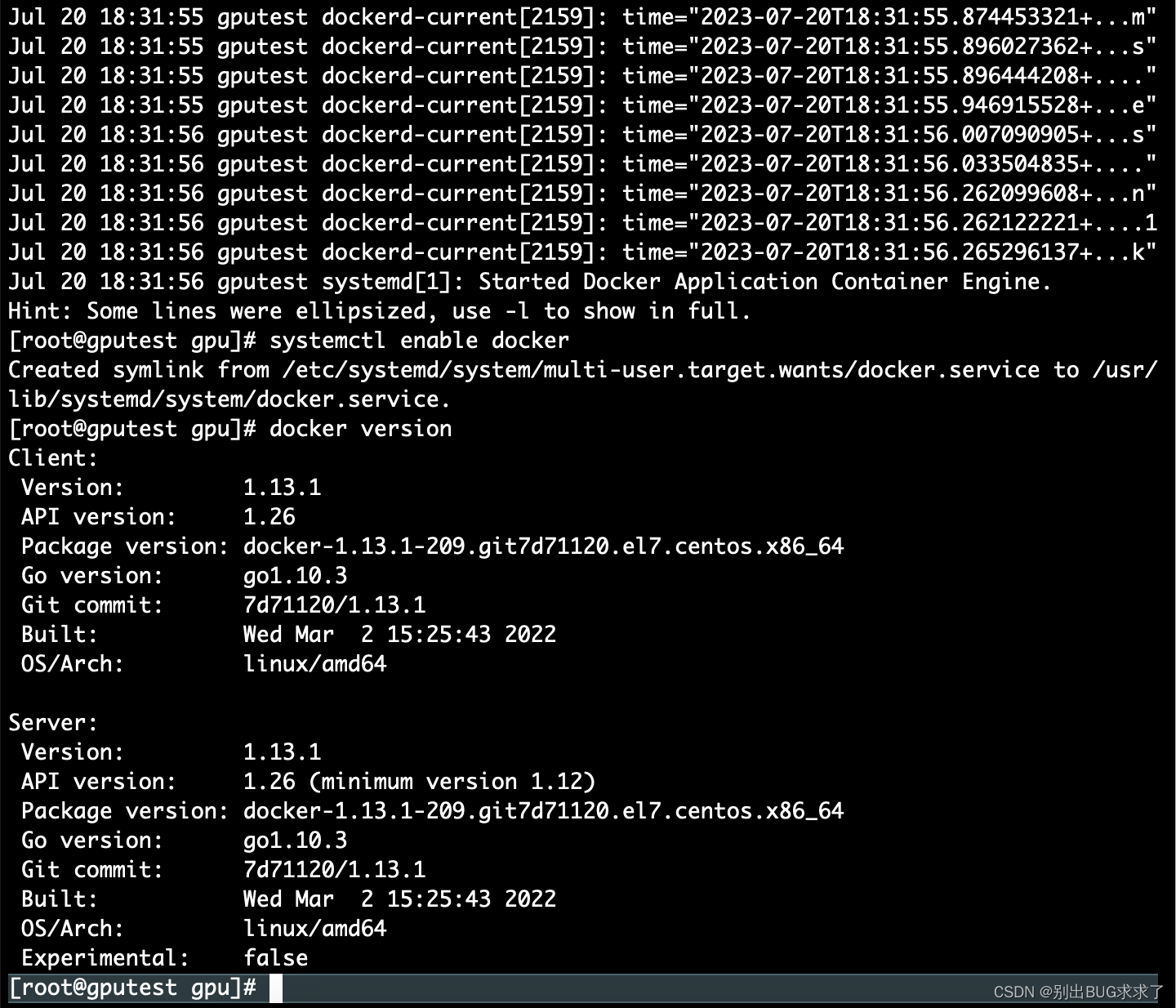
一、 nvidia-docker的安装cpu架构:x86
受够了TensorRT+cuda+opencv+ffmpeg+x264运行环境的部署的繁琐,每次新服务器上部署环境都会花费很大的精力去部署环境,听说nvidia-docker可以省去部署的麻烦,好多人也推荐使用docker方便部署,咱也在网上搜索了下,学习了下,根据网上的资料,开始安装docker学习一下,把学习记录记在这儿,听说要想使用GPU,就要安装Docker-CE和NVIDIA Container Toolkit,好的,开始。
1. 安装Dokcer-CE
首先,我的机器上没有安装过docker,要先把docker安装上,执行以下脚本,开始安装。
curl https://get.docker.com | sh \
> && sudo systemctl --now enable docker
安装结束后,查看Docker版本:
docker --version
结果如下:
Docker version 20.10.16, build aa7e414
CentOS7下安装docker详细教程
当基于nvidia gpu开发的docker镜像在实际部署时,需要先安装nvidia docker。安装nvidia docker前需要先安装原生docker compose
安装docker
- Docker 要求 CentOS 系统的内核版本高于 3.10 ,查看本页面的前提条件来验证你的CentOS 版本是否支持 Docker 。
通过 uname -r 命令查看你当前的内核版本
uname -r
uname -a
Linux gputest 3.10.0-1160.90.1.el7.x86_64 #1 SMP Thu May 4 15:21:22 UTC 2023 x86_64 x86_64 x86_64 GNU/Linux
uname -r
3.10.0-1160.90.1.el7.x86_64
- 使用 root 权限登录 Centos 确保 yum 包更新到最新
sudo yum update
- 卸载旧版本(如果安装过旧版本的话)
yum remove docker
docker-client
docker-client-latest
docker-common
docker-latest
docker-latest-logrotate
docker-logrotate
docker-selinux
docker-engine-selinux
docker-engine
- 安装需要的软件包, yum-util 提供yum-config-manager功能,另外两个是devicemapper驱动依赖的
yum install -y yum-utils device-mapper-persistent-data lvm2
- 设置yum源
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
- 可以查看所有仓库中所有docker版本,并选择特定版本安装
yum list docker-ce --showduplicates | sort -r
- 安装docker,版本号自选
yum install docker-ce-17.12.0.ce
- 启动并加入开机启动
systemctl start docker
systemctl status docker
systemctl enable docker
- 验证安装是否成功(有client和service两部分表示docker安装启动都成功了)
docker version
2. 安装NVIDIA Container Toolkit
执行以下脚本:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - \
&& curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
控制台输出如下:
[sudo] dingxin 的密码: OK deb
https://nvidia.github.io/libnvidia-container/stable/ubuntu18.04/KaTeX parse error: Expected 'EOF', got '#' at position 10: (ARCH) / #̲deb https://nvi…(ARCH)
/ deb
https://nvidia.github.io/nvidia-container-runtime/stable/ubuntu18.04/KaTeX parse error: Expected 'EOF', got '#' at position 10: (ARCH) / #̲deb https://nvi…(ARCH)
/ deb https://nvidia.github.io/nvidia-docker/ubuntu18.04/$(ARCH) /
安装nvidia-docker2包及其依赖
sudo apt-get update
接着执行安装nvidia-docker2:
sudo apt-get install -y nvidia-docker2
CentOS7下安装NVIDIA-Docker
依赖条件
如果使用的 Tensorflow 版本大于 1.4.0,要求 CUDA 9.0 以上版本
基于docker的测试环境的建立
测试环境基于docker构建,需要Nvidia GPU驱动的支持(不需要安装CUDA),安装好GPU驱动和docker以后,下载最新的包含tensorflow,CUDA,cudnn等的image,然后就可以运行tf_cnn_benchmark了
- 下载nvidia-docker安装包
$ wget https://github.com/NVIDIA/nvidia-docker/releases/download/v1.0.1/nvidia-docker-1.0.1-1.x86_64.rpm
- 安装nvidia-docker
$ rpm -ivh nvidia-docker-1.0.1-1.x86_64.rpm
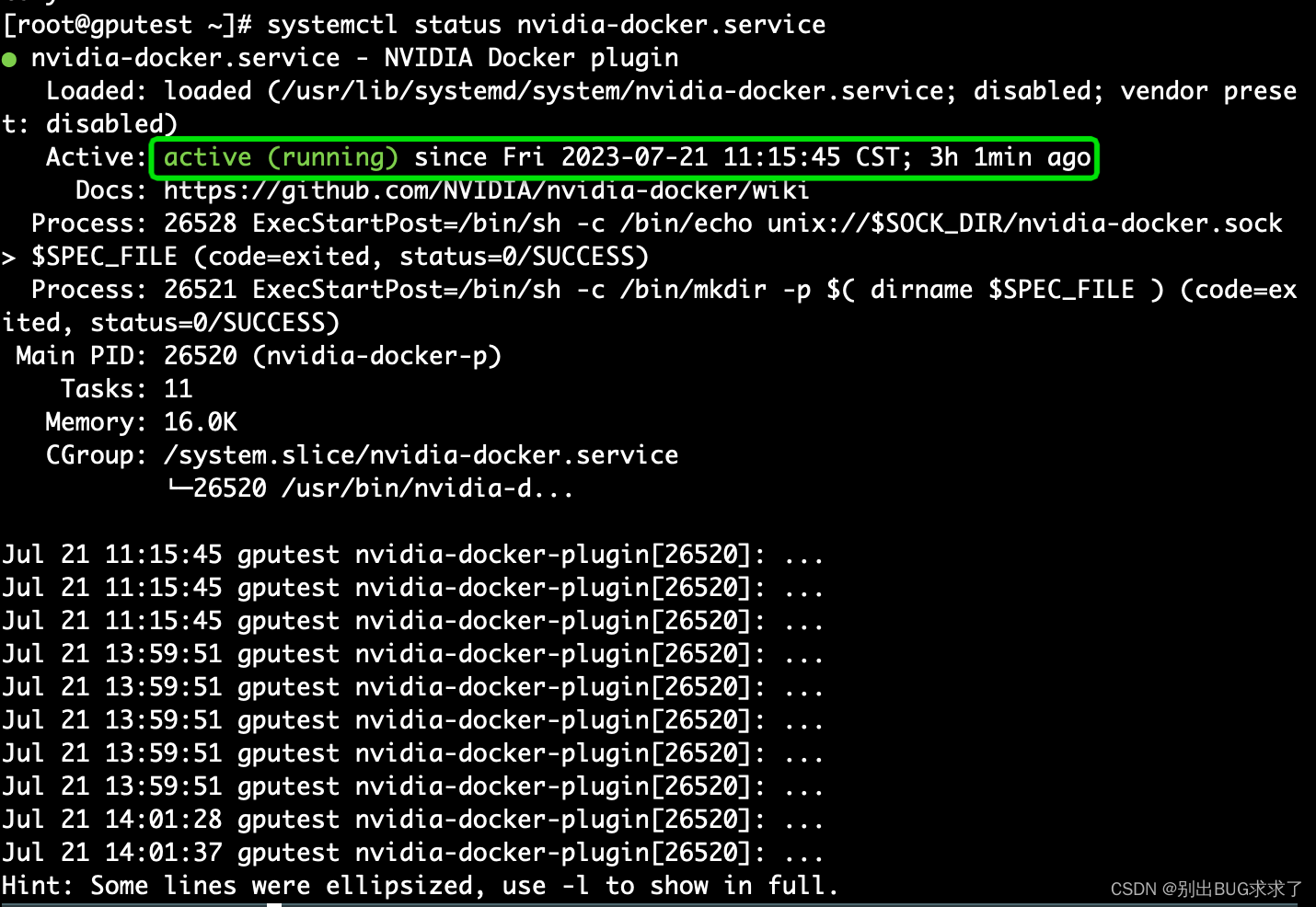
- 启动 nvidia-docker 服务
$ sudo systemctl restart nvidia-docker
- 执行以下命令,若结果显示 active(running) 则说明启动成功
$ systemctl status nvidia-docker.service
Active: active (running) since Fri 2023-07-21 11:15:45 CST; 1min ago
5. 使用 nvidia-docker查看 GPU 信息
$ nvidia-docker run --rm nvidia/cuda nvidia-smi
二、镜像安装
1. cuda 11下的安装(可选)
sudo docker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smi
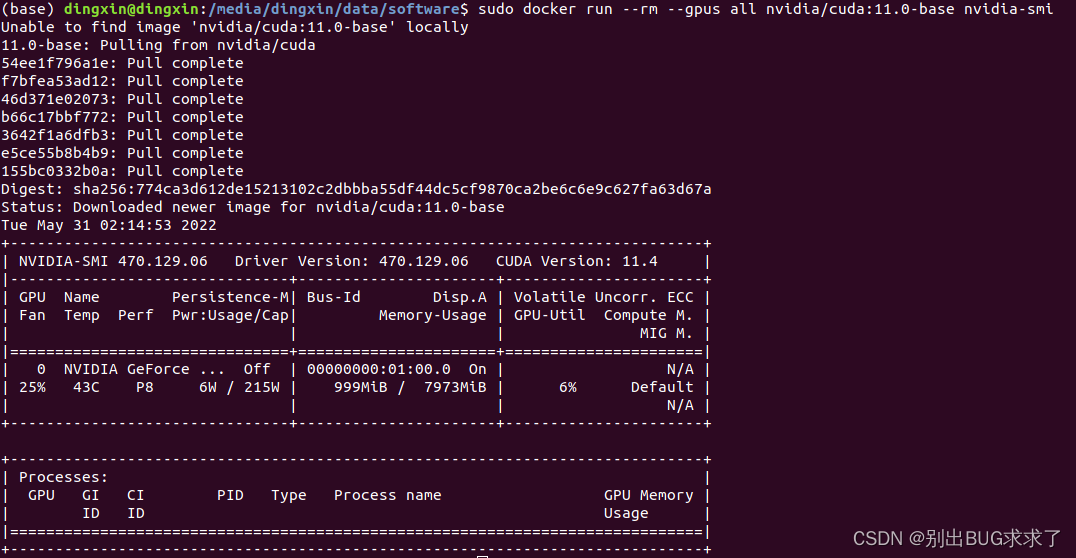
查看已下载的镜像
sudo docker images -a

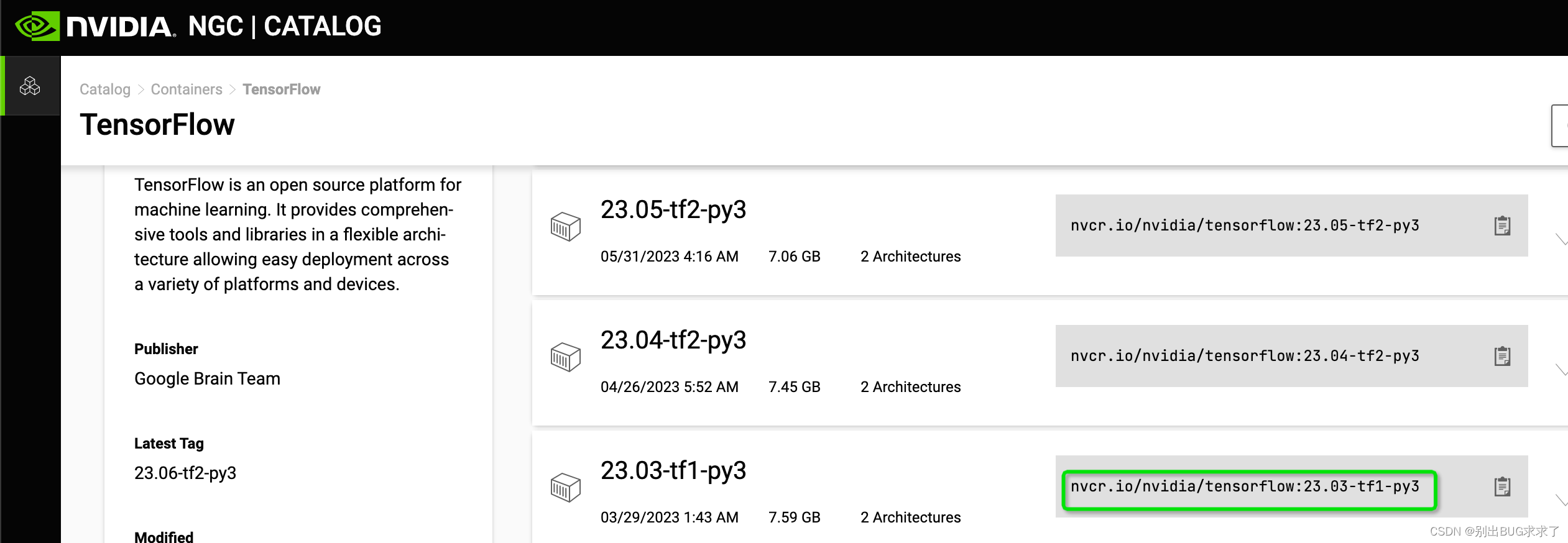
2. 下载tensorflow v1.15.5版本的镜像
官网下载:
https://catalog.ngc.nvidia.com/orgs/nvidia/containers/tensorflow/tags
大概1.5小时
安装testflow1.0版本(向下兼容)
docker pull nvcr.io/nvidia/tensorflow:23.03-tf1-py3
再次查看下载的镜像
docker image ls
image id = fc14c7fdf361为上述安装的tensorflow1.15版本容器

三、操作tensorflow容器
nvidia-docker run -it nvcr.io/nvidia/tensorflow:23.03-tf1-py3
格式:nvidia-docker run -it {REPOSITORY容器名称:TAG号}
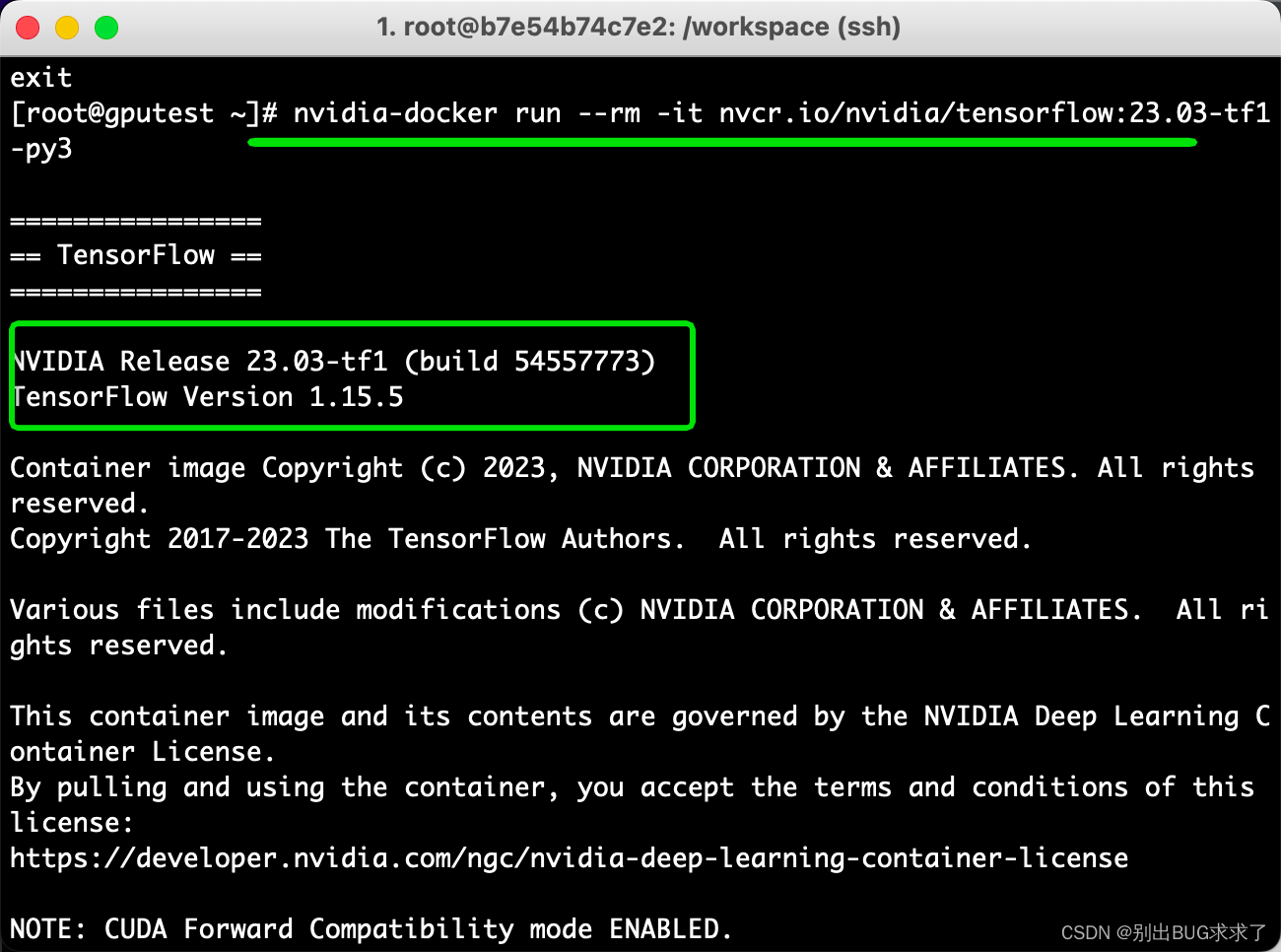
pip list|grep tensor
jupyter-tensorboard 0.2.0
tensorboard 1.15.0
tensorflow 1.15.5+nv23.3
tensorflow-estimator 1.15.1
tensorrt 8.5.3.1
测试脚本:
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
hello = tf.constant('--------Hello, TensorFlow!----------')
sess = tf.Session()
sess.run(hello)
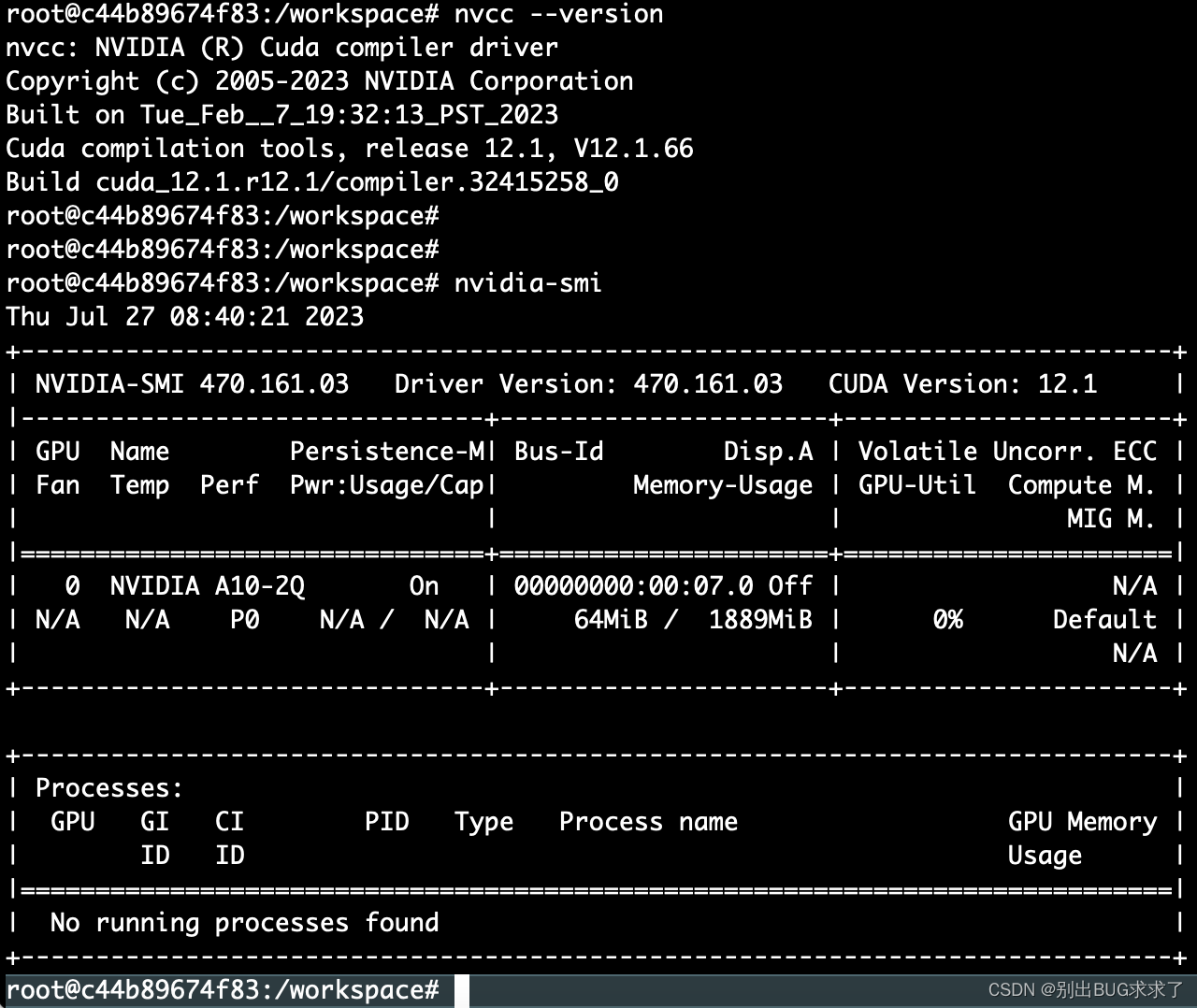
在container OS中使用命令cat /proc/driver/nvidia/version或nvcc --version可正常显示显卡驱动版本及CUDA版本
四、配置git
- 在本机生成公私钥
ssh-keygen -t rsa -b 4096 -C "xx@xx.com"默认生成的公私钥 ~/.ssh/
id_rsa.pub
id_rsa
-b 4096:b是bit的缩写
-b 指定密钥长度。对于RSA密钥,最小要求768位,默认是2048位。命令中的4096指的是RSA密钥长度为4096位。
DSA密钥必须恰好是1024位(FIPS 186-2 标准的要求)
Generating public/private rsa key pair. Enter file in which to save
the key (/Users/qa/.ssh/id_rsa): yes Enter passphrase (empty for no
passphrase): Enter same passphrase again: Your identification has been
saved in yes. Your public key has been saved in yes.pub. The key
fingerprint is: SHA256:MGbV/xx/xx lishan12@xx.com The key’s randomart
image is:
±–[RSA 4096]----+ | …OBB=Eo| | . .O+oO=o=| | = .o*+B *o.| | o o o+B =… | | S.+o . | | . o |
| . . | | . . | | . |
±—[SHA256]-----+
- 配置登录git的username email。为公司给你分配的用户名 密码
第一步:
git config --global user.name 'username'
git config --global user.email 'username@xx.com'
第二步: 设置永久保存
git config --global credential.helper store
第三步:手动输入一次用户名和密码,GIT会自动保存密码,下次无须再次输入
git pull
-
初始化仓库
git init -
拉取代码
git clone git@gitlab.xx.com:xx/xx.git
Cloning into ‘xx-xx’…
git@gitlab.xx.com’s password:
Permission denied, please try again.
git@gitlab.xx.com’s password:
遇到的问题:没有出username 和 password成对的输入项 ,而是出了password输入项
都不知道密码是啥,跟登录git库的密码不一样。
然后使用http的方式,报一个错误:
use:~/ecox # git clone https://vcs.in.ww-it.cn/ecox/ecox.git
正克隆到 ‘ecox’…
fatal: unable to access ‘https://vcs.in.ww-it.cn/ecox/ecox.git/’: SSL certificate problem: unable to get local issuer certificate
提示SSL证书错误。发现说这个错误并不重要是系统证书的问题,系统判断到这个行为会造成不良影响,所以进行了阻止,只要设置跳过SSL证书验证就可以了,那么用命令 :
git config --global http.sslVerify false
五、下载Benchmarks源码并运行
从 TensorFlow 的 Github 仓库上下载 TensorFlow Benchmarks,可以通过以下命令来下载。非常重要的参考代码:
https://github.com/tensorflow/benchmarks
我的 - settings -SSH and GPG Keys 添加公钥id_rsa.pub
拉取代码
git clone git@github.com:tensorflow/benchmarks.git
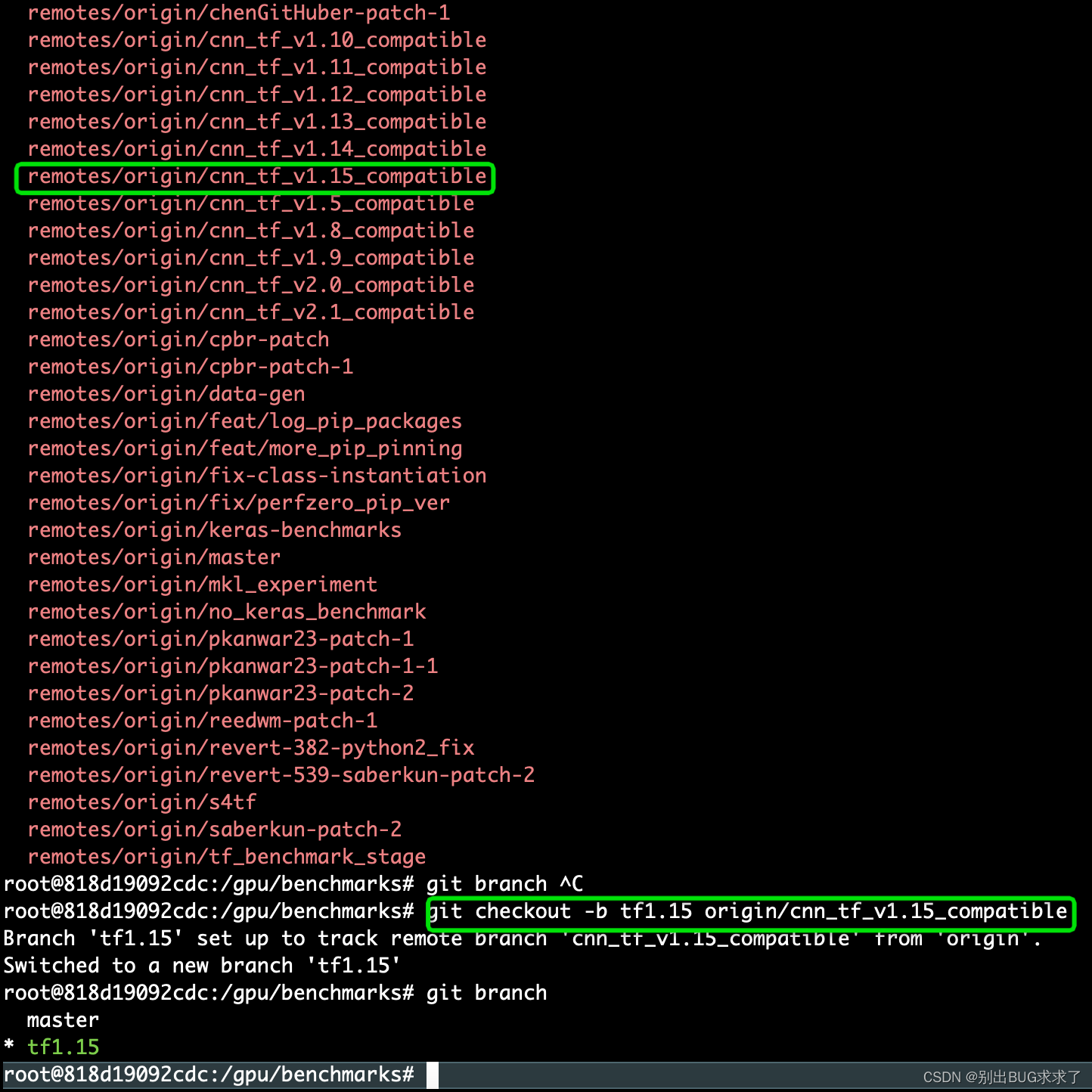
git同步远程分支到本地,拉取tensorflow对应版本的分支
git fetch origin 远程分支名xxx:本地分支名xxx
使用这种方式会在本地仓库新建分支xxx,但是并不会自动切换到新建的分支xxx,需要手动checkout,当然了远程分支xxx的代码也拉取到了本地分支xxx中。采用这种方法建立的本地分支不会和远程分支建立映射关系
root@818d19092cdc:/gpu/benchmarks# git checkout -b tf1.15 origin/cnn_tf_v1.15_compatible
运行不同模型
root@818d19092cdc:/gpu/benchmarks/scripts/tf_cnn_benchmarks# pwd
/gpu/benchmarks/scripts/tf_cnn_benchmarks
root@818d19092cdc:/gpu/benchmarks/scripts/tf_cnn_benchmarks#
python3 tf_cnn_benchmarks.py
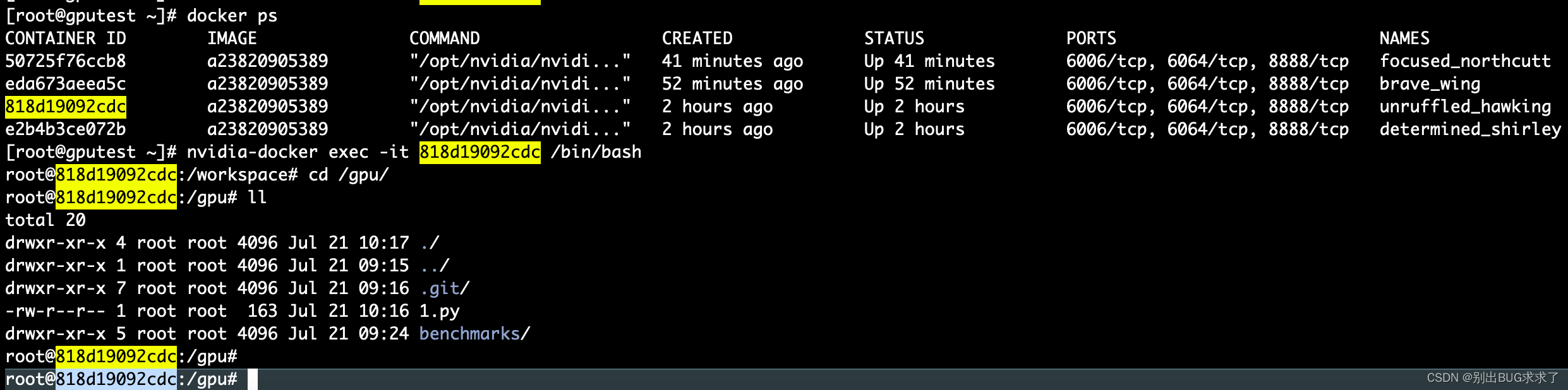
真实操作:
[root@gputest ~]# docker ps
进入CONTAINER ID containerid
[root@gputest ~]# nvidia-docker exec -it 818d19092cdc /bin/bash
新开窗口
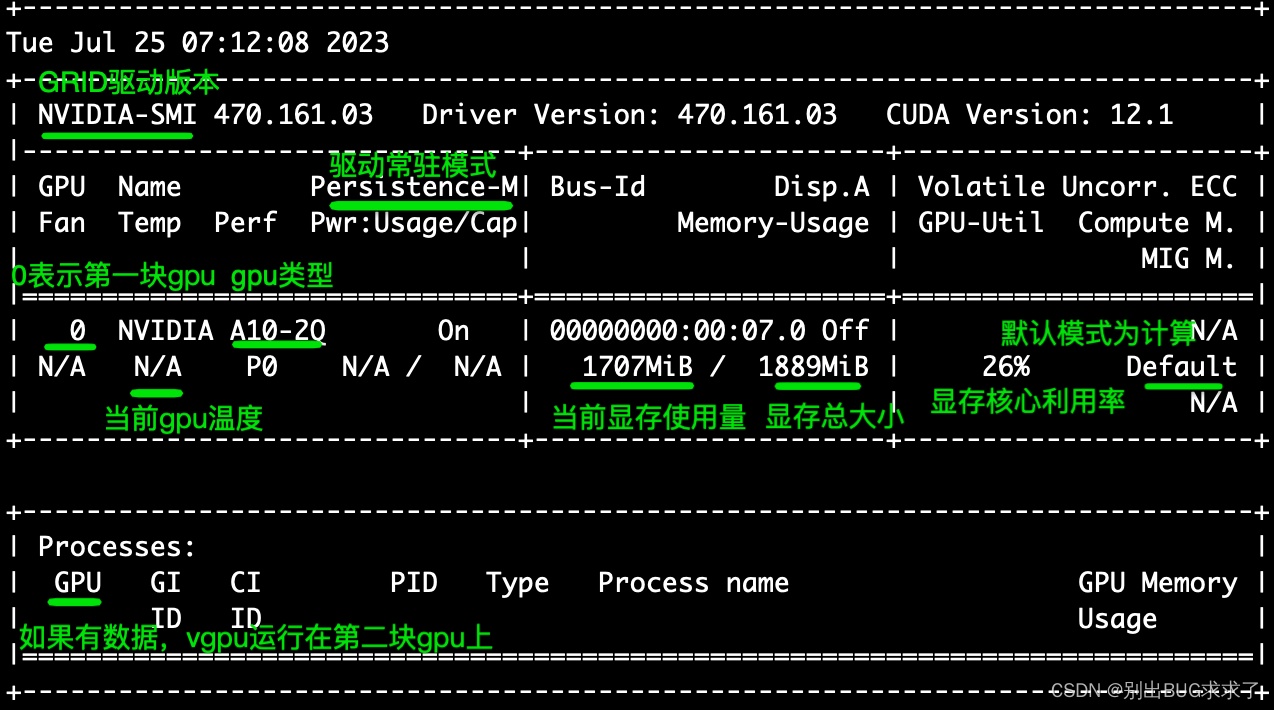
[root@gputest ~]# nvidia-smi -l 3
该命令将3秒钟输出一次GPU的状态和性能,可以通过查看输出结果来得出GPU的性能指标
一、resnet50模型
python3 tf_cnn_benchmarks.py --num_gpus=1 --batch_size=2 --model=resnet50 --variable_update=parameter_server
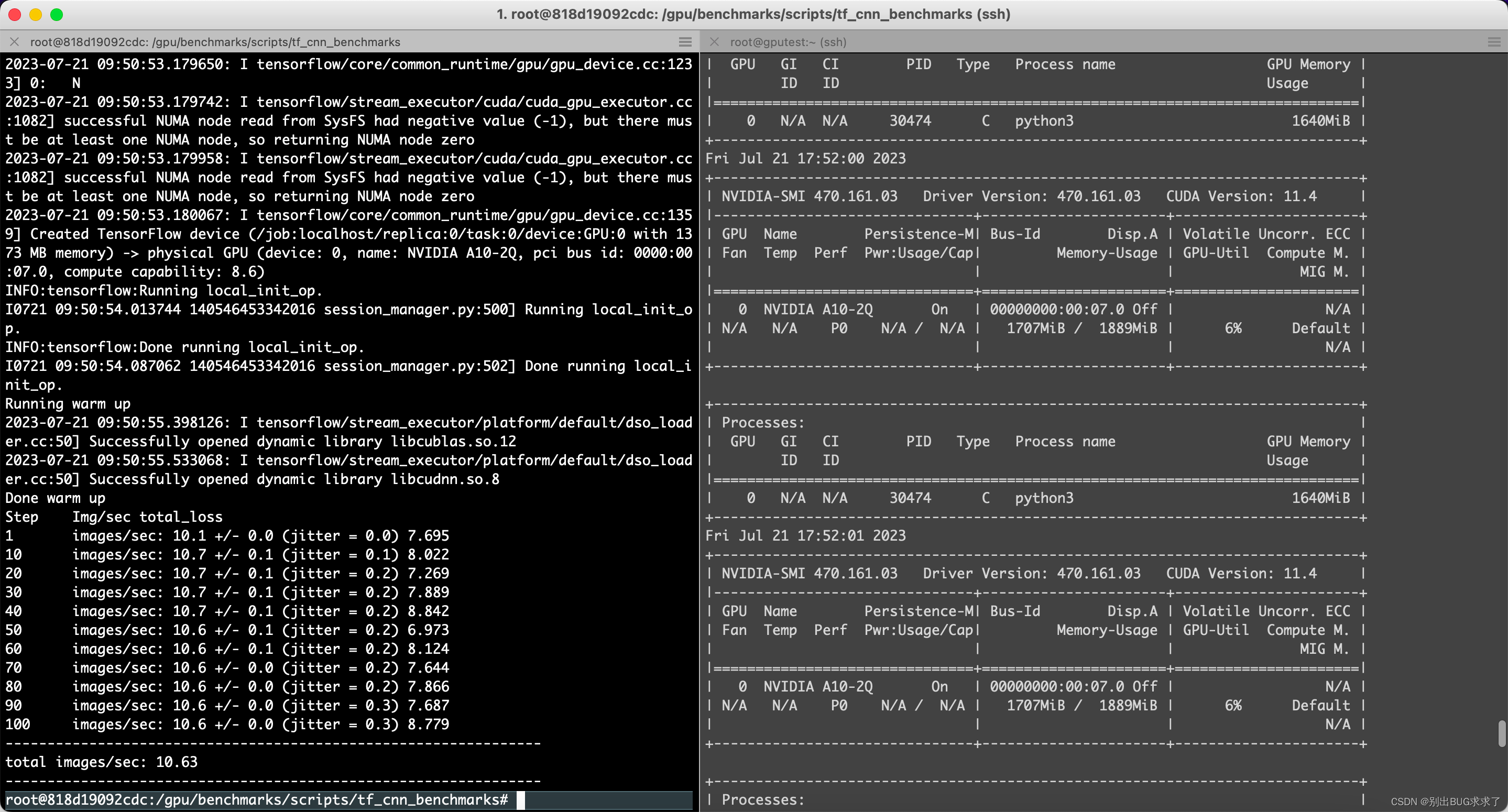
Running warm up
2023-07-21 09:50:55.398126: I tensorflow/stream_executor/platform/default/dso_loader.cc:50] Successfully opened dynamic library libcublas.so.12
2023-07-21 09:50:55.533068: I tensorflow/stream_executor/platform/default/dso_loader.cc:50] Successfully opened dynamic library libcudnn.so.8
Done warm up
Step Img/sec total_loss
1 images/sec: 10.1 +/- 0.0 (jitter = 0.0) 7.695
10 images/sec: 10.7 +/- 0.1 (jitter = 0.1) 8.022
20 images/sec: 10.7 +/- 0.1 (jitter = 0.2) 7.269
30 images/sec: 10.7 +/- 0.1 (jitter = 0.2) 7.889
40 images/sec: 10.7 +/- 0.1 (jitter = 0.2) 8.842
50 images/sec: 10.6 +/- 0.1 (jitter = 0.2) 6.973
60 images/sec: 10.6 +/- 0.1 (jitter = 0.2) 8.124
70 images/sec: 10.6 +/- 0.0 (jitter = 0.2) 7.644
80 images/sec: 10.6 +/- 0.0 (jitter = 0.2) 7.866
90 images/sec: 10.6 +/- 0.0 (jitter = 0.3) 7.687
100 images/sec: 10.6 +/- 0.0 (jitter = 0.3) 8.779
----------------------------------------------------------------total images/sec: 10.63
二、vgg16模型
python3 tf_cnn_benchmarks.py --num_gpus=1 --batch_size=2 --model=vgg16 --variable_update=parameter_server

由于阿里云服务器申请的是2个G显存,所以只能跑size=1 2 和 4 ,超出会吐核
已放弃(吐核)–linux 已放弃(吐核) (core dumped) 问题分析
出现这种问题一般是下面这几种情况:
-
1.内存越界
2.使用了非线程安全的函数
3.全局数据未加锁保护
4.非法指针
5.堆栈溢出
也就是需要检查访问的内存、资源。
可以使用 strace 命令来进行分析
在程序的运行命令前加上 strace,在程序出现:已放弃(吐核),终止运行后,就可以通过 strace 打印在控制台的跟踪信息进行分析和定位问题
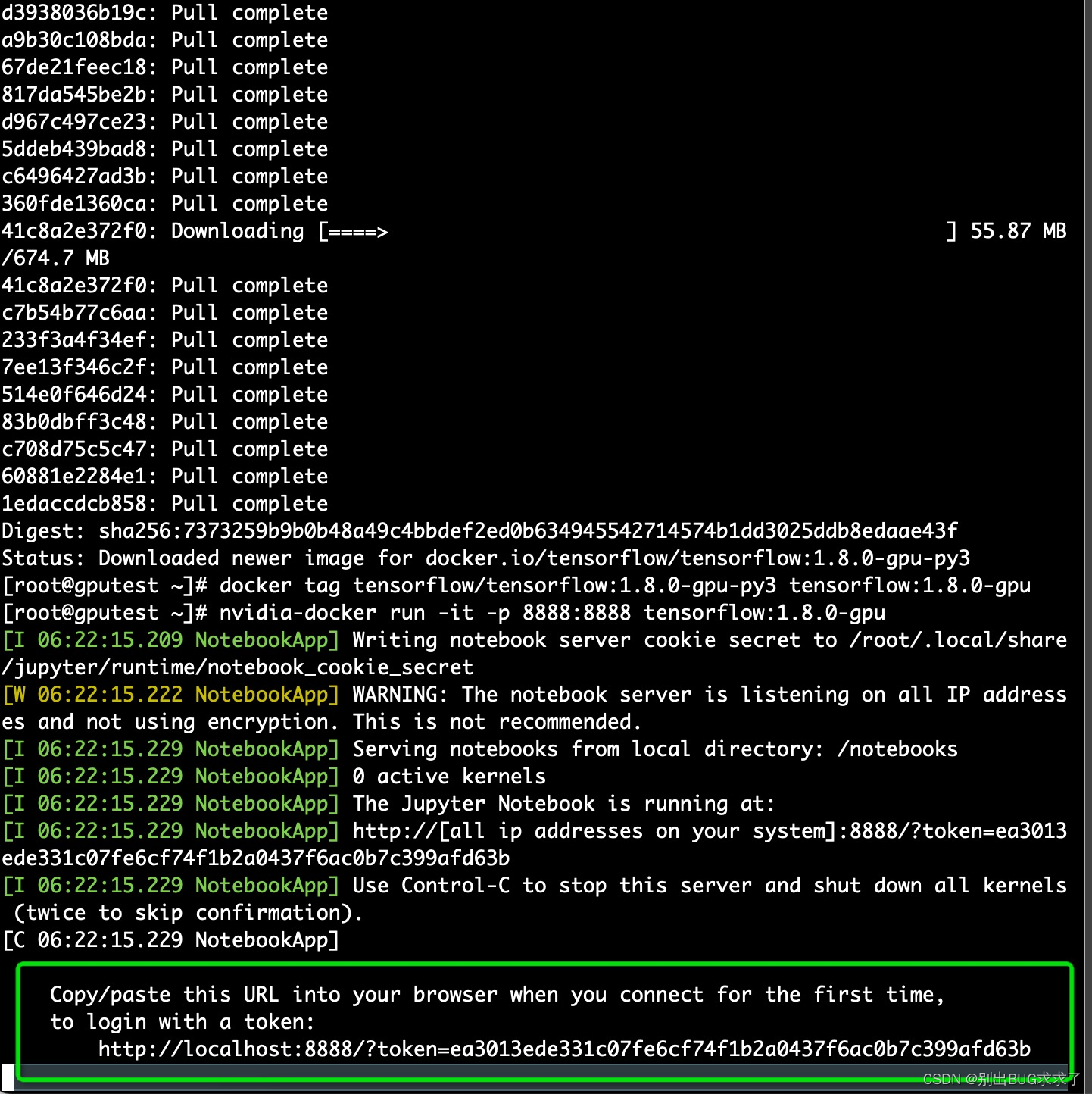
方法2:docker启动普通镜像的Tensorflow
$ docker pull tensorflow/tensorflow:1.8.0-gpu-py3
$ docker tag tensorflow/tensorflow:1.8.0-gpu-py3 tensorflow:1.8.0-gpu
nvidia-docker run -it -p 8888:8888 tensorflow:1.8.0-gpu
$ nvidia-docker run -it -p 8033:8033 tensorflow:1.8.0-gpu
浏览器进入指定 URL(见启动终端回显) 就可以利用 IPython Notebook 使用 tensorflow
评测指标
-
训练时间:在指定数据集上训练模型达到指定精度目标所需的时间
-
吞吐:单位时间内训练的样本数
-
加速效率:加速比/设备数*100%。其中,加速比定义为多设备吞吐数较单设备的倍数
-
成本:在指定数据集上训练模型达到指定精度目标所需的价格
-
功耗:在指定数据集上训练模型达到指定精度目标所需的功耗
在初版评测指标设计中,我们重点关注训练时间、吞吐和加速效率三项
六、保存镜像的修改
执行以下命令,保存TensorFlow镜像的修改
docker commit -m "commit docker" CONTAINER_ID nvcr.io/nvidia/tensorflow:18.03-py3
# CONTAINER_ID可通过docker ps命令查看。
[root@gputest ~]# docker commit -m “commit docker” 818d19092cdc nvcr.io/nvidia/tensorflow:23.03-tf1-py3
sha256:fc14c7fdf361308817161d5d0cc018832575e7f2def99fe49876d2a41391c52c
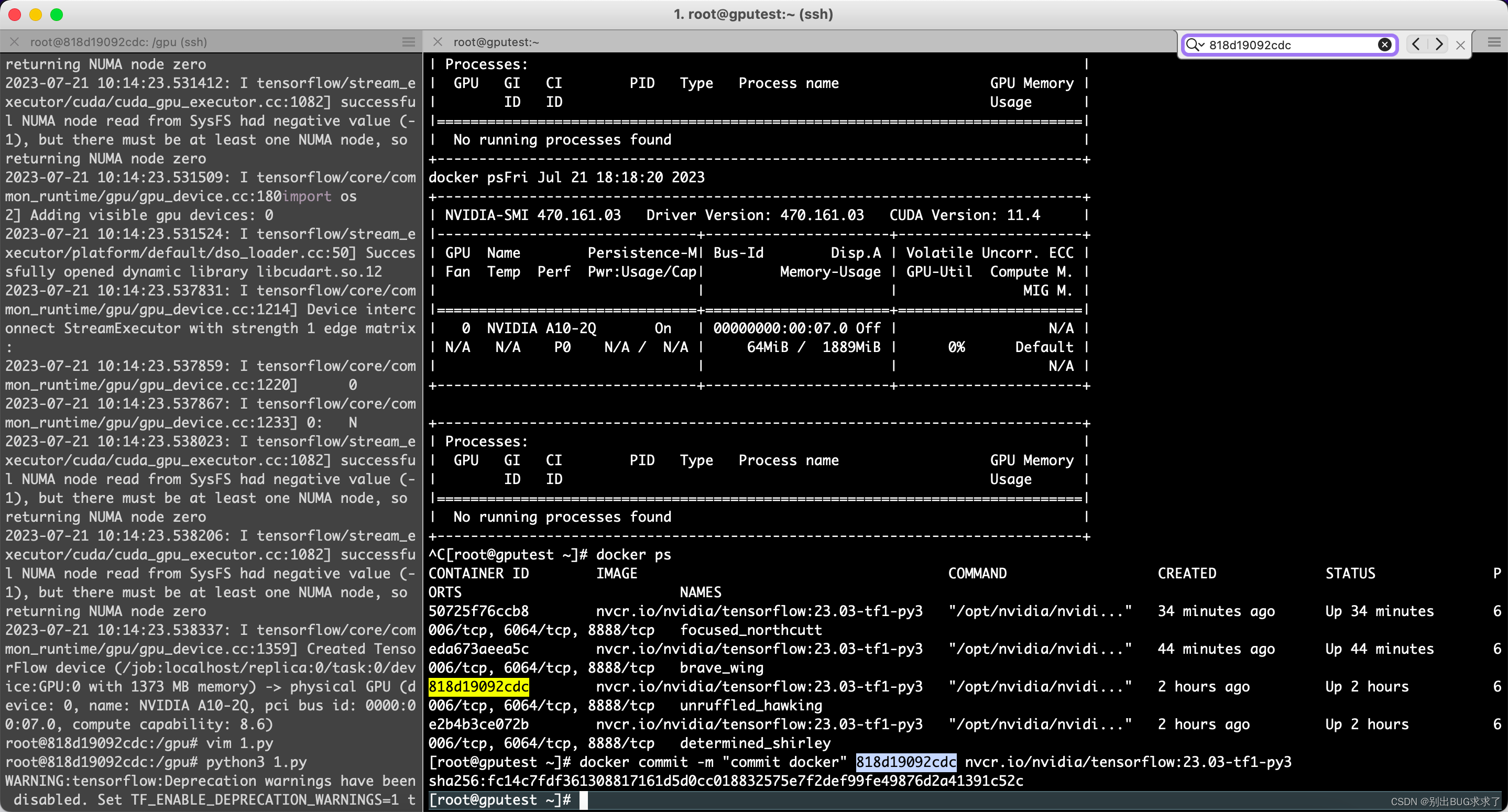
查看docker进程
[root@gputest ~]# docker ps
重新进入CONTAINER ID containerid
[root@gputest ~]# nvidia-docker exec -it 818d19092cdc /bin/bash
七、benchmarks 支持的所有参数
| 参数名称 | 描述 | 备注 |
| --help | 查看帮助信息 | |
| --backend | 使用的框架名称,如TensorFlow,PyTorch等,必须指定 | 当前只支持TensorFlow,后续会增加对PyTorch的支持 |
| --model | 使用的模型名称,如alexnet、resnet50等,必须指定 | 请查阅所有支持的模型 |
| --batch_size | batch size大小 | 默认值为32 |
| --num_epochs | epoch的数量 | 默认值为1 |
| --num_gpus | 使用的GPU数量。设置为0时,仅使用CPU。
| |
| --data_dir | 输入数据的目录,对于CV任务,当前仅支持ImageNet数据集;如果没有指定,表明使用合成数据 | |
| --do_train | 执行训练过程 | 这三个选项必须指定其中的至少一个,可以同时指定多个选项。 |
| --do_eval | 执行evaluation过程 | |
| --do_predict | 执行预测过程 | |
| --data_format | 使用的数据格式,NCHW或NHWC,默认为NCHW。
| |
| --optimizer | 所使用的优化器,当前支持SGD、Adam和Momentum,默认为SGD | |
| --init_learning_rate | 使用的初始learning rate的值 | |
| --num_epochs_per_decay | learning rate decay的epoch间隔 | 如果设置,这两项必须同时指定 |
| --learning_rate_decay_factor | 每次learning rate执行decay的因子 | |
| --minimum_learning_rate | 最小的learning rate值 | 如果设置,需要同时指定面的两项 |
| --momentum | momentum参数的值 | 用于设置momentum optimizer |
| --adam_beta1 | adam_beta1参数的值 | 用于设置Adam |
| --adam_beta2 | adam_beta2参数的值 | |
| --adam_epsilon | adam_epsilon参数的值 | |
| --use_fp16 | 是否设置tensor的数据类型为float16 | |
| --fp16_vars | 是否将变量的数据类型设置为float16。如果没有设置,变量存储为float32类型,并在使用时转换为fp16格式。 建议:不要设置 | 必须同时设置--use_fp16 |
| --all_reduce_spec | 使用的AllReduce方式 | |
| --save_checkpoints_steps | 间隔多少step存储一次checkpoint | |
| --max_chkpts_to_keep | 保存的checkpoint的最大数量 | |
| --ip_list | 集群中所有机器的IP地址,以逗号分隔 | 用于多机分布式训练 |
| --job_name | 任务名称,如‘ps'、’worker‘ | |
| --job_index | 任务的索引,如0,1等 | |
| --model_dir | checkpoint的存储目录 | |
| --init_checkpoint | 初始模型checkpoint的路径,用于在训练前加载该checkpoint,进行finetune等 | |
| --vocab_file | vocabulary文件 | 用于NLP |
| --max_seq_length | 输入训练的最大长度 | 用于NLP |
| --param_set | 创建和训练模型时使用的参数集。 | 用于Transformer |
| --blue_source | 包含text translate的源文件,用于计算BLEU分数 | |
| --blue_ref | 包含text translate的源文件,用于计算BLEU分数 | |
| --task_name | 任务的名称,如MRPC,CoLA等 | 用于Bert |
| --do_lower_case | 是否为输入文本使用小写 | |
| --train_file | 训练使用的SQuAD文件,如train-v1.1.json | 用于Bert模型,运行SQuAD, --run_squad必须指定 |
| --predict_file | 预测所使用的SQuAD文件,如dev-v1.1.json或test-v1.1.json | |
| --doc_stride | 当将长文档切分为块时,块之间取的间距大小 | |
| --max_query_length | 问题包含的最大token数。当问题长度超过该值时,问题将被截断到这一长度。 | |
| --n_best_size | nbest_predictions.json输出文件中生成的n-best预测的总数 | |
| --max_answer_length | 生成的回答的最大长度 | |
| --version_2_with_negative | 如果为True,表明SQuAD样本中含有没有答案(answer)的问题 | |
| --run_squad | 如果为True,运行SQUAD任务,否则,运行sequence (sequence-pair)分类任务 |
八、GPU使用注意事项
1. 如何在tensorflow中指定使用GPU资源
在配置好GPU环境的TensorFlow中 ,如果操作没有明确地指定运行设备,那么TensorFlow会优先选择GPU。在默认情况下,TensorFlow只会将运算优先放到/gpu:0上。如果需要将某些运算放到不同的GPU或者CPU上,就需要通过tf.device来手工指定
import tensorflow as tf
# 通过tf.device将运算指定到特定的设备上。
with tf.device('/cpu:0'):
a = tf.constant([1.0, 2.0, 3.0], shape=[3], name='a')
b = tf.constant([1.0, 2.0, 3.0], shape=[3], name='b')
with tf.device('/gpu:1'):
c = a + b
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print sess.run(c)
2. 虚拟化使用GPU的方案
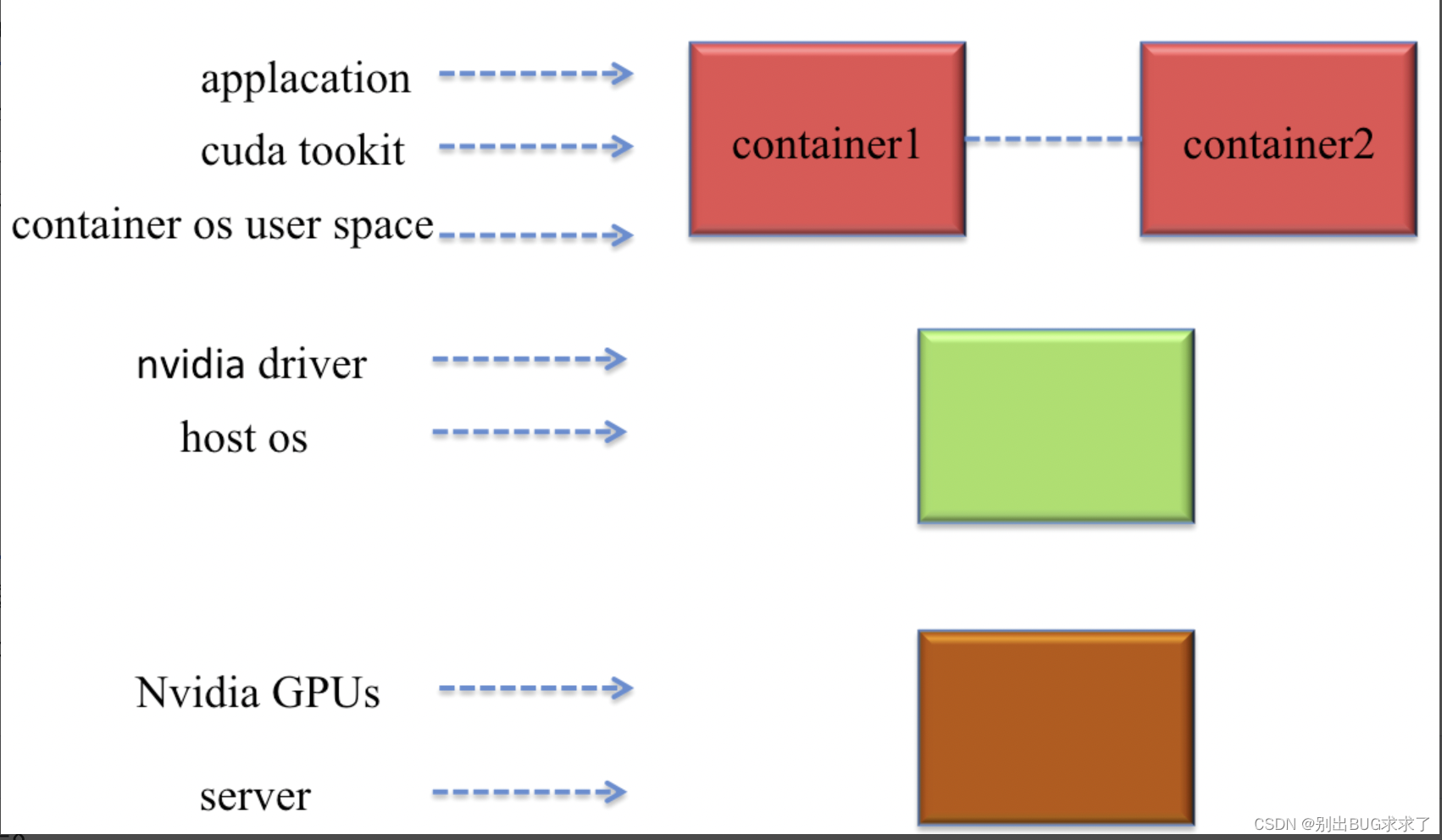
通过KVM虚拟化实例使用CPU和内存等资源,GPU不参与虚拟化。不同容器共享使用物理GPU资源
3. 分布式TensorFlow
#coding=utf-8
#多台机器,每台机器有一个显卡、或者多个显卡,这种训练叫做分布式训练
import tensorflow as tf
#现在假设我们有A、B、C、D四台机器,首先需要在各台机器上写一份代码,并跑起来,各机器上的代码内容大部分相同
# ,除了开始定义的时候,需要各自指定该台机器的task之外。以机器A为例子,A机器上的代码如下:
cluster=tf.train.ClusterSpec({
"worker": [
"A_IP:2222",#格式 IP地址:端口号,第一台机器A的IP地址 ,在代码中需要用这台机器计算的时候,就要定义:/job:worker/task:0
"B_IP:1234"#第二台机器的IP地址 /job:worker/task:1
"C_IP:2222"#第三台机器的IP地址 /job:worker/task:2
],
"ps": [
"D_IP:2222",#第四台机器的IP地址 对应到代码块:/job:ps/task:0
]})
使用分布式的TensorFlow比较容易。只需在集群服务器中为 worker 节点分配带名字的IP。 然后 就可以手动或者自动为 worker 节点分配操作任务
. GPU 显存资源监控
一个Server端的外挂模块,提供任务特征到资源特征的映射数据集,方便后续预测模型构建以及对芯片资源能力的定义
利用 with tf.device("{device-name}") 这种写法,可以将with statement代码块中的变量或者op指定分配到该设备上。 在上面例子中,变量 W 和 b 就被分配到 /cpu:0 这个设备上。注意,如果一个变量被分配到一个设备上,读取这个变量也就要从这个设备读取,写入这个变量也将会写入到这个设备。 而 output (也就是一个 tf.matmul 矩阵乘法的计算操作,跟着一个tensor的加法的计算操作),以及后面的 loss 的计算(即对 output 调用了 f 这个函数,该函数中可能还有很多逻辑,涉及很多tensor运算的op),分配给了 /gpu:0 这个设备。
基本原则:变量放到CPU,计算放到GPU。
这时,TensorFlow实际上会将代码中定义的Graph(计算图)分割,根据指定的device placement将图的不同部分分配到不同的设备上,并且在设备间建立通信(如DMA,Direct Memory Access)。这些都不需要在应用代码层面操作。
单机多卡
当我们在一台机器上有多个GPU可用时,要利用多个GPU,代码编写方式的示意如下:
# Calculate the gradients for each model tower.
tower_grads = []
with tf.variable_scope(tf.get_variable_scope()):
for i in xrange(FLAGS.num_gpus):
with tf.device('/gpu:%d' % i):
with tf.name_scope('%s_%d' % (cifar10.TOWER_NAME, i)) as scope:
# Dequeues one batch for the GPU
image_batch, label_batch = batch_queue.dequeue()
# Calculate the loss for one tower of the CIFAR model. This function
# constructs the entire CIFAR model but shares the variables across
# all towers.
loss = tower_loss(scope, image_batch, label_batch)
# Reuse variables for the next tower.
tf.get_variable_scope().reuse_variables()
# Retain the summaries from the final tower.
summaries = tf.get_collection(tf.GraphKeys.SUMMARIES, scope)
# Calculate the gradients for the batch of data on this CIFAR tower.
grads = opt.compute_gradients(loss)
# Keep track of the gradients across all towers.
tower_grads.append(grads)
# We must calculate the mean of each gradient. Note that this is the
# synchronization point across all towers.
grads = average_gradients(tower_grads)
本质上分配设备的方式和单机单卡的情况是一样的,使用同样的语法。 在上例中,假设我们有2个GPU,则代码会按照相同的逻辑定义两套操作,先后分配给名为 /gpu:0 和 /gpu:1 的两个设备。
注意:
-
tensorflow的代码中cpu和gpu的设备编号默认从0开始
-
比如我们在机器上看到有两块GPU,通过CUDA_VISIBLE_DEVICES环境变量进行控制,起了一个进程,只让0号GPU对其可见,再起一个进程,只让1号GPU对其可见,在两个进程的tensorflow代码中,都是通过/gpu:0来分别指代它们可用的GPU。
-
上例属于in-graph,从tensorboard绘制的计算图中可以明显看出来(下文会有对比展示)
-
上例属于数据并行
-
上例属于同步更新
下面展示一些示例,运行的代码是以TensorFlow官网指南(https://www.tensorflow.org/guide/using_gpu )为基础的,在单机2GPU的环境以multi-tower方式运行。运行过程中记录了Tensorboard使用的summary
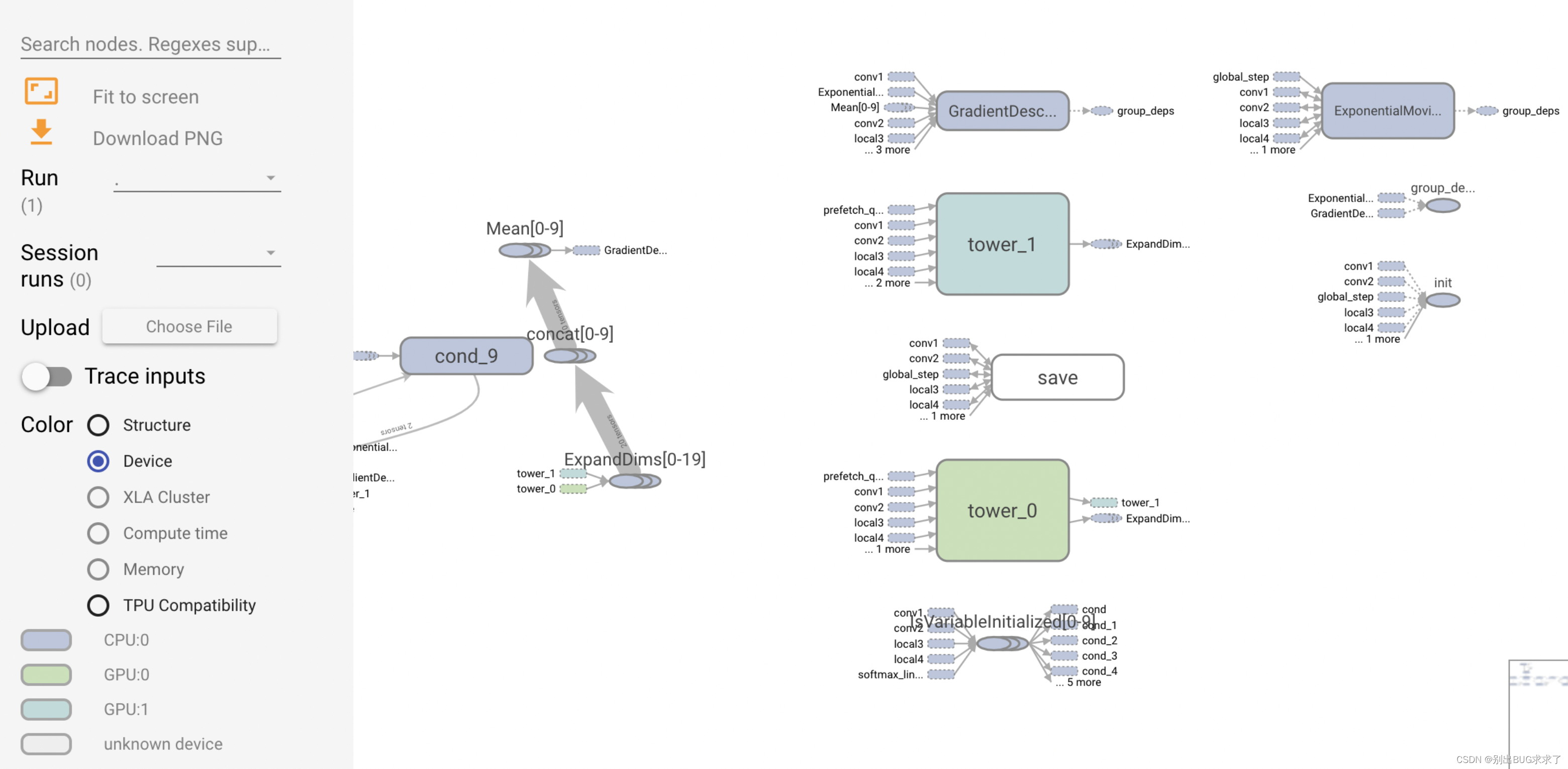
可以看到,CPU, GPU:0, GPU:1分别用三种颜色进行了标记。
重要参考资料
本文大部分内容都是看了自以下几个资料再进行试验总结出来的:
Distributed Tensorflow (TensorFlow官网): https://www.tensorflow.org/deploy/distributed
Distributed TensorFlow (TensorFlow Dev Summit 2017): https://www.youtube.com/watch?v=la_M6bCV91M&index=11&list=PLOU2XLYxmsIKGc_NBoIhTn2Qhraji53cv
Distributed TensorFlow (TensorFlow Dev Summit 2018): https://www.youtube.com/watch?v=-h0cWBiQ8s8 (本文没有包括Dev Summit 2018这个talk的内容,这里面除了基本原理之外,只讲了TensorFlow如何支持All Reduce,但是只适用于单机多卡,并且是High Level API。多机多卡的方面演讲者也只推荐了Horovod这种方式。)
另外还有官网关于使用GPU的指南: https://www.tensorflow.org/guide/using_gpu
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











