





九 锁
1.GIL锁(Global Interpreter Lock)
首先,一些语言(java、c++、c)是支持同一个进程中的多个线程是可以应用多核CPU的,也就是我们会听到的现在4核8核这种多核CPU技术的牛逼之处。那么我们之前说过应用多进程的时候如果有共享数据是不是会出现数据不安全的问题啊,就是多个进程同时一个文件中去抢这个数据,大家都把这个数据改了,但是还没来得及去更新到原来的文件中,就被其他进程也计算了,导致数据不安全的问题啊,所以我们是不是通过加锁可以解决啊,多线程大家想一下是不是一样的,并发执行就是有这个问题。但是python最早期的时候对于多线程也加锁,但是python比较极端的(在当时电脑cpu确实只有1核)加了一个GIL全局解释锁,是解释器级别的,锁的是整个线程,而不是线程里面的某些数据操作,每次只能有一个线程使用cpu,也就说多线程用不了多核,但是他不是python语言的问题,是CPython解释器的特性,如果用Jpython解释器是没有这个问题的,Cpython是默认的,因为速度快,Jpython是java开发的,在Cpython里面就是没办法用多核,这是python的弊病,历史问题,虽然众多python团队的大神在致力于改变这个情况,但是暂没有解决。(这和解释型语言(python,php)和编译型语言有关系吗???待定!,编译型语言一般在编译的过程中就帮你分配好了,解释型要边解释边执行,所以为了防止出现数据不安全的情况加上了这个锁,这是所有解释型语言的弊端??)
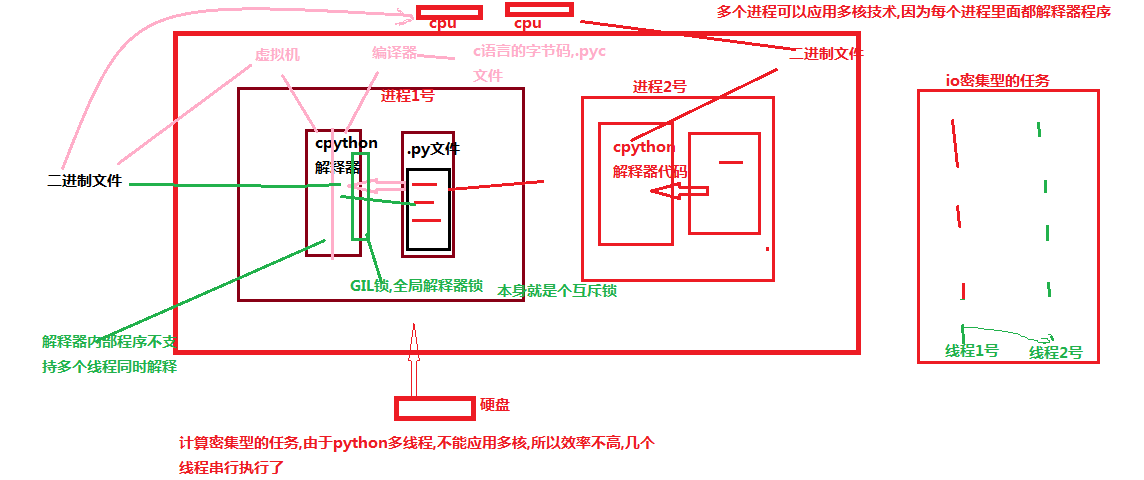
但是有了这个锁我们就不能并发了吗?当我们的程序是偏计算的,也就是cpu占用率很高的程序(cpu一直在计算),就不行了,但是如果你的程序是I/O型的(一般你的程序都是这个)(input、访问网址网络延迟、打开/关闭文件读写),在什么情况下用的到高并发呢(金融计算会用到,人工智能(阿尔法狗),但是一般的业务场景用不到,爬网页,多用户网站、聊天软件、处理文件),I/O型的操作很少占用CPU,那么多线程还是可以并发的,因为cpu只是快速的调度线程,而线程里面并没有什么计算,就像一堆的网络请求,我cpu非常快速的一个一个的将你的多线程调度出去,你的线程就去执行I/O操作了,
2.同步锁
三个需要注意的点:#1.线程抢的是GIL锁,GIL锁相当于执行权限,拿到执行权限后才能拿到互斥锁Lock,其他线程也可以抢到GIL,但如果发现Lock仍然没有被释放则阻塞,即便是拿到执行权限GIL也要立刻交出来
#2.join是等待所有,即整体串行,而锁只是锁住修改共享数据的部分,即部分串行,要想保证数据安全的根本原理在于让并发变成串行,join与互斥锁都可以实现,毫无疑问,互斥锁的部分串行效率要更高
#3. 一定要看本小节最后的GIL与互斥锁的经典分析
GIL VS Lock
机智的同学可能会问到这个问题,就是既然你之前说过了,Python已经有一个GIL来保证同一时间只能有一个线程来执行了,为什么这里还需要lock?
首先我们需要达成共识:锁的目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据
然后,我们可以得出结论:保护不同的数据就应该加不同的锁。
最后,问题就很明朗了,GIL 与Lock是两把锁,保护的数据不一样,前者是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据),后者是保护用户自己开发的应用程序的数据,很明显GIL不负责这件事,只能用户自定义加锁处理,即Lock
过程分析:所有线程抢的是GIL锁,或者说所有线程抢的是执行权限
线程1抢到GIL锁,拿到执行权限,开始执行,然后加了一把Lock,还没有执行完毕,即线程1还未释放Lock,有可能线程2抢到GIL锁,开始执行,执行过程中发现Lock还没有被线程1释放,于是线程2进入阻塞,被夺走执行权限,有可能线程1拿到GIL,然后正常执行到释放Lock。。。这就导致了串行运行的效果
既然是串行,那我们执行
t1.start()
t1.join
t2.start()
t2.join()
这也是串行执行啊,为何还要加Lock呢,需知join是等待t1所有的代码执行完,相当于锁住了t1的所有代码,而Lock只是锁住一部分操作共享数据的代码。
详解:
因为Python解释器帮你自动定期进行内存回收,你可以理解为python解释器里有一个独立的线程,每过一段时间它起wake up做一次全局轮询看看哪些内存数据是可以被清空的,此时你自己的程序 里的线程和 py解释器自己的线程是并发运行的,假设你的线程删除了一个变量,py解释器的垃圾回收线程在清空这个变量的过程中的clearing时刻,可能一个其它线程正好又重新给这个还没来及得清空的内存空间赋值了,结果就有可能新赋值的数据被删除了,为了解决类似的问题,python解释器简单粗暴的加了锁,即当一个线程运行时,其它人都不能动,这样就解决了上述的问题, 这可以说是Python早期版本的遗留问题。
看一段代码:解释为什么要加锁,如果下面代码中work函数里面的那个time.sleep(0.005),我的电脑用的这个时间片段,每次运行都呈现不同的结果,我们可以改改时间试一下。


from threading importThread,Lockimportos,timedefwork():globaln#lock.acquire() #加锁
temp=n
time.sleep(0.1) #一会将下面循环的数据加大并且这里的时间改的更小试试
n=temp-1
#time.sleep(0.02)
#n = n - 1
'''如果这样写的话看不出来效果,因为这样写就相当于直接将n的指向改了,就好比从10,经过1次减1之后,n就直接指向了9,速度太快,看不出效果,那么我们怎么办呢,找一个中间变量来接收n,然后对这个中间变量进行修改,然后再赋值给n,多一个给n赋值的过程,那么在这个过程中间,我们加上一点阻塞时间,来看效果,就像读文件修改数据之后再写回文件的过程。那么这个程序就会出现结果为9的情况,首先一个进程的全局变量对于所有线程是共享的,由于我们在程序给中间变量赋值,然后给n再次赋值的过程中我们加了一些I/O时间,遇到I/O就切换,那么每个线程都拿到了10,并对10减1了,然后大家都得到了9,然后再赋值给n,所有n等于了9'''
#lock.release()
if __name__ == '__main__':
lock=Lock()
n=100l=[]#for i in range(10000): #如果这里变成了10000,你在运行一下看看结果
for i in range(100): #如果这里变成了10000,你在运行一下看看结果
p=Thread(target=work)
l.append(p)
p.start()for p inl:
p.join()print(n) #结果肯定为0,由原来的并发执行变成串行,牺牲了执行效率保证了数据安全
需要仔细研究的示例
上面这个代码示例,如果循环次数变成了10000,在我的电脑上就会出现不同的结果,因为在线程切换的那个time.sleep的时间内,有些线程还没有被切换到,也就是有些线程还没有拿到n的值,所以计算结果就没准了。
锁通常被用来实现对共享资源的同步访问。为每一个共享资源创建一个Lock对象,当你需要访问该资源时,调用acquire方法来获取锁对象(如果其它线程已经获得了该锁,则当前线程需等待其被释放),待资源访问完后,再调用release方法释放锁:
importthreading
R=threading.Lock()
R.acquire() #
#R.acquire()如果这里还有一个acquire,你会发现,程序就阻塞在这里了,因为上面的锁已经被拿到了并且还没有释放的情况下,再去拿就阻塞住了'''对公共数据的操作'''R.release()
通过上面的代码示例1,我们看到多个线程抢占资源的情况,可以通过加锁来解决,看代码:
from threading importThread,Lockimportos,timedefwork():globaln
lock.acquire()#加锁
temp=n
time.sleep(0.1)
n=temp-1lock.release()if __name__ == '__main__':
lock=Lock()
n=100l=[]for i in range(100):
p=Thread(target=work)
l.append(p)
p.start()for p inl:
p.join()print(n) #结果肯定为0,由原来的并发执行变成串行,牺牲了执行效率保证了数据安全
同步锁的引用
看上面代码的图形解释:

分析:#1.100个线程去抢GIL锁,即抢执行权限
#2. 肯定有一个线程先抢到GIL(暂且称为线程1),然后开始执行,一旦执行就会拿到lock.acquire()
#3. 极有可能线程1还未运行完毕,就有另外一个线程2抢到GIL,然后开始运行,但线程2发现互斥锁lock还未被线程1释放,于是阻塞,被迫交出执行权限,即释放GIL
#4.直到线程1重新抢到GIL,开始从上次暂停的位置继续执行,直到正常释放互斥锁lock,然后其他的线程再重复2 3 4的过程
GIL锁与互斥锁综合分析(重点)
#不加锁:并发执行,速度快,数据不安全
from threading importcurrent_thread,Thread,Lockimportos,timedeftask():globalnprint('%s is running' %current_thread().getName())
temp=n
time.sleep(0.5)
n=temp-1
if __name__ == '__main__':
n=100lock=Lock()
threads=[]
start_time=time.time()for i in range(100):
t=Thread(target=task)
threads.append(t)
t.start()for t inthreads:
t.join()
stop_time=time.time()print('主:%s n:%s' %(stop_time-start_time,n))'''Thread-1 is running
Thread-2 is running
......
Thread-100 is running
主:0.5216062068939209 n:99'''
#不加锁:未加锁部分并发执行,加锁部分串行执行,速度慢,数据安全
from threading importcurrent_thread,Thread,Lockimportos,timedeftask():#未加锁的代码并发运行
time.sleep(3)print('%s start to run' %current_thread().getName())globaln#加锁的代码串行运行
lock.acquire()
temp=n
time.sleep(0.5)
n=temp-1lock.release()if __name__ == '__main__':
n=100lock=Lock()
threads=[]
start_time=time.time()for i in range(100):
t=Thread(target=task)
threads.append(t)
t.start()for t inthreads:
t.join()
stop_time=time.time()print('主:%s n:%s' %(stop_time-start_time,n))'''Thread-1 is running
Thread-2 is running
......
Thread-100 is running
主:53.294203758239746 n:0'''
#有的同学可能有疑问:既然加锁会让运行变成串行,那么我在start之后立即使用join,就不用加锁了啊,也是串行的效果啊#没错:在start之后立刻使用jion,肯定会将100个任务的执行变成串行,毫无疑问,最终n的结果也肯定是0,是安全的,但问题是#start后立即join:任务内的所有代码都是串行执行的,而加锁,只是加锁的部分即修改共享数据的部分是串行的#单从保证数据安全方面,二者都可以实现,但很明显是加锁的效率更高.
from threading importcurrent_thread,Thread,Lockimportos,timedeftask():
time.sleep(3)print('%s start to run' %current_thread().getName())globaln
temp=n
time.sleep(0.5)
n=temp-1
if __name__ == '__main__':
n=100lock=Lock()
start_time=time.time()for i in range(100):
t=Thread(target=task)
t.start()
t.join()
stop_time=time.time()print('主:%s n:%s' %(stop_time-start_time,n))'''Thread-1 start to run
Thread-2 start to run
......
Thread-100 start to run
主:350.6937336921692 n:0 #耗时是多么的恐怖'''
互斥锁与join的区别(重点)
3.死锁与递归锁
进程也有死锁与递归锁,在进程那里忘记说了,放到这里一切说了额,进程的死锁和线程的是一样的,而且一般情况下进程之间是数据不共享的,不需要加锁,由于线程是对全局的数据共享的,所以对于全局的数据进行操作的时候,要加锁。
所谓死锁: 是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程,如下就是死锁
from threading importLock as Lockimporttime
mutexA=Lock()
mutexA.acquire()
mutexA.acquire()print(123)
mutexA.release()
mutexA.release()
from threading importThread,Lockimporttime
mutexA=Lock()
mutexB=Lock()classMyThread(Thread):defrun(self):
self.func1()
self.func2()deffunc1(self):
mutexA.acquire()print('\033[41m%s 拿到A锁>>>\033[0m' %self.name)
mutexB.acquire()print('\033[42m%s 拿到B锁>>>\033[0m' %self.name)
mutexB.release()
mutexA.release()deffunc2(self):
mutexB.acquire()print('\033[43m%s 拿到B锁???\033[0m' %self.name)
time.sleep(2)#分析:当线程1执行完func1,然后执行到这里的时候,拿到了B锁,线程2执行func1的时候拿到了A锁,那么线程2还要继续执行func1里面的代码,再去拿B锁的时候,发现B锁被人拿了,那么就一直等着别人把B锁释放,那么就一直等着,等到线程1的sleep时间用完之后,线程1继续执行func2,需要拿A锁了,但是A锁被线程2拿着呢,还没有释放,因为他在等着B锁被释放,那么这俩人就尴尬了,你拿着我的老A,我拿着你的B,这就尴尬了,俩人就停在了原地
mutexA.acquire()print('\033[44m%s 拿到A锁???\033[0m' %self.name)
mutexA.release()
mutexB.release()if __name__ == '__main__':for i in range(10):
t=MyThread()
t.start()'''Thread-1 拿到A锁>>>
Thread-1 拿到B锁>>>
Thread-1 拿到B锁???
Thread-2 拿到A锁>>>
然后就卡住,死锁了'''
更难一些的死锁现象
解决方法,递归锁,在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。
这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使用RLock代替Lock,则不会发生死锁:
from threading importRLock as Lockimporttime
mutexA=Lock()
mutexA.acquire()
mutexA.acquire()print(123)
mutexA.release()
mutexA.release()
典型问题:科学家吃面 ,看下面代码示例:
importtimefrom threading importThread,Lock
noodle_lock=Lock()
fork_lock=Lock()defeat1(name):
noodle_lock.acquire()print('%s 抢到了面条'%name)
fork_lock.acquire()print('%s 抢到了叉子'%name)print('%s 吃面'%name)
fork_lock.release()
noodle_lock.release()defeat2(name):
fork_lock.acquire()print('%s 抢到了叉子' %name)
time.sleep(1)
noodle_lock.acquire()print('%s 抢到了面条' %name)print('%s 吃面' %name)
noodle_lock.release()
fork_lock.release()for name in ['taibai','egon','wulaoban']:
t1= Thread(target=eat1,args=(name,))
t2= Thread(target=eat2,args=(name,))
t1.start()
t2.start()
和上面更难一些的死锁现象是一样的
importtimefrom threading importThread,RLock
fork_lock= noodle_lock =RLock()defeat1(name):
noodle_lock.acquire()print('%s 抢到了面条'%name)
fork_lock.acquire()print('%s 抢到了叉子'%name)print('%s 吃面'%name)
fork_lock.release()
noodle_lock.release()defeat2(name):
fork_lock.acquire()print('%s 抢到了叉子' %name)
time.sleep(1)
noodle_lock.acquire()print('%s 抢到了面条' %name)print('%s 吃面' %name)
noodle_lock.release()
fork_lock.release()for name in ['taibai','wulaoban']:
t1= Thread(target=eat1,args=(name,))
t1.start()for name in ['alex','peiqi']:
t2= Thread(target=eat2,args=(name,))
t2.start()
递归锁解决死锁问题
递归锁大致描述: 当我们的程序中需要两把锁的时候,你就要注意,别出现死锁,最好就去用递归锁。
















 1125
1125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









