





介绍
在这篇文章中,我们将了解什么是真正的梯度下降,为什么它变得流行,为什么AI和ML中的大多数算法都遵循这种技术。
在开始之前,梯度下降实际上意味着什么?听起来很奇怪对吧!
柯西是1847年第一个提出梯度下降的人
嗯,梯度这个词的意思是一个性质的增加和减少!而下降意味着向下移动的动作。所以,总的来说,在下降到某个地方然后观察并且继续下降的行为被称为梯度下降

所以,在正常情况下,如图所示,山顶的坡度很高,通过不断的移动,当你到达山脚时的坡度最小,或者接近或等于零。同样的情况在数学上也适用。
让我们看看怎么做
梯度下降数学

所以,如果你看到这里的形状和这里的山是一样的。我们假设这是一条形式为y=f(x)的曲线。
这里我们知道,任何一点上的斜率都是y对x的导数,如果你用曲线来检查,你会发现,当向下移动时,斜率在尖端或最小位置减小并等于零,当我们再次向上移动时,斜率会增加
记住这一点,我们将研究在最小点处x和y的值会发生什么,
观察下图,我们有不同位置的五个点!
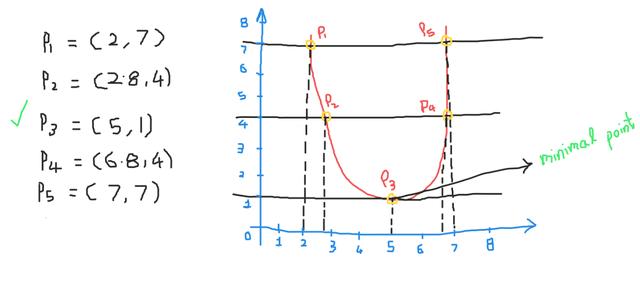
当我们向下移动时,我们会发现y值会减小,所以在这里的所有点中,我们在图的底部得到了相对最小的值。因此,我们的结论是我们总是在图的底部找到最小值(x,y)。现在让我们看看如何在ML和DL中传递这个,以及如何在不遍历整个图的情况下达到最小点?
在任何一种算法中,我们的主要目的是最小化损失,这表明我们的模型表现良好。为了分析这一点,我们将使用线性回归

因为线性回归使用直线来预测连续输出-
设直线y=w*x+c
这里我们需要找到w和c,这样我们就得到了使误差最小化的最佳拟合线。所以我们的目标是找到最佳的w和c值
我们从一些随机值开始w和c,我们根据损失更新这些值,也就是说,我们更新这些权重,直到斜率等于或接近于零。
我们将取y轴上的损失函数,x轴上有w和c。查看下图-

为了在第一个图中达到最小的w值,请遵循以下步骤-
- 用w和c开始计算给定的一组x _values的损失。
- 绘制点,现在将权重更新为- w_new =w_old – learning_rate * slope at (w_old,loss)
重复这些步骤,直到达到最小值!
- 我们在这里减去梯度,因为我们想移到山脚下,或者朝着最陡的下降方向移动
- 当我们减去后,我们会得到一个比前一个小的斜率,这就是我们想要移动到斜率等于或接近于零的点
- 我们稍后再讨论学习率
这同样适用于图2,即损失和c的函数

现在的问题是为什么要把学习率放在等式中?因为我们不能在起点和最小值之间遍历所有的点
我们需要跳过一些点
- 我们可以在最初阶段采取大步行动。
- 但是,当我们接近最小值时,我们需要小步走,因为我们可能会越过最小值,移动到一个斜坡的地方增加。为了控制图的步长和移动,引入了学习速率。即使没有学习速率,我们也会得到最小值,但我们关心的是我们的算法要更快!!

下面是一个使用梯度下降的线性回归的示例算法。这里我们用均方误差作为损失函数-
1.用零初始化模型参数
m=0,c=0
2.使用(0,1)范围内的任何值初始化学习速率
lr=0.01
误差方程-

现在用(w*x+c)代替Ypred并计算偏导
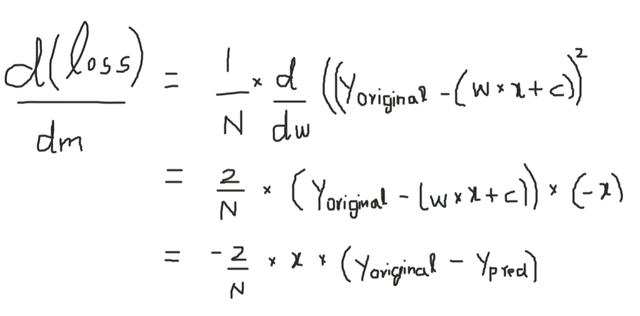
3.c也一样可以计算得出

4.将此应用于所有epoch的数据集
for i in range(epochs): y_pred = w * x +c D_M = (-2/n) * sum(x * (y_original - y_pred)) D_C = (-2/n) * sum(y_original - y_pred)这里求和函数一次性将所有点的梯度相加!
更新所有迭代的参数
W = W – lr * D_M
C = C – lr * D_C
梯度下降法用于神经网络的深度学习…

在这里,我们更新每个神经元的权值,以便在最小误差的情况下得到最佳分类。我们使用梯度下降法来更新每一层的所有权值…
Wi = Wi – learning_rate * derivative (Loss function w.r.t Wi)
为什么它受欢迎?
梯度下降是目前机器学习和深度学习中最常用的优化策略。
它用于训练数据模型,可以与各种算法相结合,易于理解和实现
许多统计技术和方法使用GD来最小化和优化它们的过程。















 950
950











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









