






Word2Vec(Neural Language Model,NLM)
(本专栏会依次对NLP领域模型按照时代发展的顺序进行精讲并提供实现,欢迎各位积极探讨,关注)
本次将介绍 Tomas Mikolov的经典论文Efficient Estimation of Word Representations in Vector Space
1,什么是Word2Vec?
Word2vec是一组用于生成word embedding的模型,这些模型以浅层的神经网络模型为基础,经过大量语料的训练来重建word之间的语言关系,并产生一个通常具有几百个维度的向量空间,同时为语料库中的每个单词在该空间中分配一个对应的向量(这个稠密的vector就是对应单词的embedding)。word2vec的目标就是构建一个向量空间,在这个向量空间中,每个词都会拥有一个唯一的向量值,这些词向量的表示会维持原本词与词之间存在的一些关系,那么如何构建这样的一个向量空间呢?
2,Word2Vec的两种网络架构
目前主流实现架构有两种,其核心思路都在于利用滑窗得到句子片段并对片段内的词关系进行建模,下面将详细介绍两种架构。
(1)CBOW模型架构解析

如图所示,该模型结构思想十分明确,我们可以将其抽象分为三个部分并分别给出解释:
- 词向量输入层:从初始化的词向量矩阵中依据对应词语的序(即指示向量,只有该词所在的位置为1,其余为0)抽取对应的列,也就是词向量(对CBOW来说就是上下文中所有的词),在未训练之前可以是随机初始化或先验的一些数值。
- 融合层:多种数学操作来融合不同词的词向量(常见的有平均,拼接,求和等)。
- 输出层:构建可以参数化的概率值输出以便模型进行学习。
由于采取的融合操作,所以CBOW让上下文单词的分布在词向量上进行平滑,进而消除了噪音,这使得其对小数据集比较友好。
(2)skip-gram模型架构解析
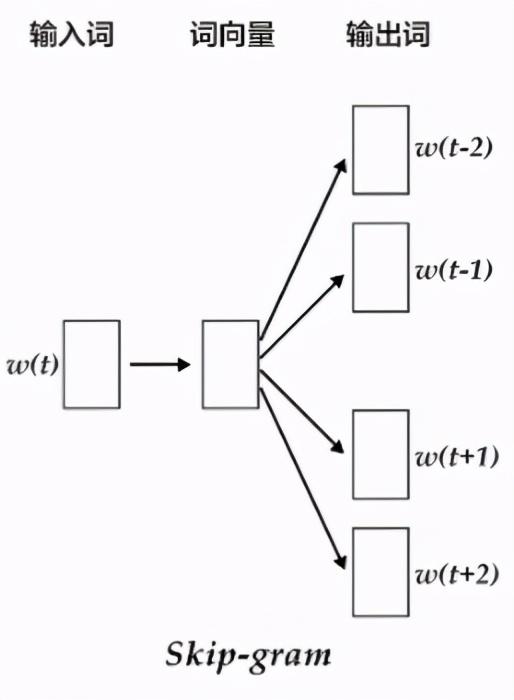
CBOW与Skip-gram最大的区别在于所使用的上下文思想不同。两者均会使用滑动窗口从一段语料中截取出一部分文字,CBOW架构会在窗口内选定一个中心词(上图的窗口大小为2),然后用窗口内所有的上下文去预测这个词,使得这个词出现的概率最大,而Skip-gram的想法则相反,选定的这个中心词会被用来预测窗口内所有的上下文词,使这些词的概率最大。如上图所示,因为输入只有一个单词,所以不需要像CBOW一样构造一个融合层,而是直接将输入单词的词向量经过映射层,再根据前后共4个单词的词向量,结合softmax函数来分别获得这4个单词的分类损失值并求和,得到模型最终的损失并以此进行优化。
2,逐步骤代码实现
(本文将使用paddlepaddle来实现整个流程,尽量屏蔽不同框架间独有的特征,展示所有的细节,这样如果需要使用其他框架实现会十分的容易)
步骤一:引入相关库,定义常量
import paddleimport paddle.fluid as fluidimport siximport numpyimport mathEMBED_SIZE = 32 # embedding dimensionsHIDDEN_SIZE = 256 # hidden layer size 隐层大小BATCH_SIZE = 100 # batch sizePASS_NUM = 100 # Training roundsuse_cuda = False # Set to True if trained with GPU步骤二:构建词典,定义训练数据
sentences = [" i have a company", "i have a company that", "have a company that one", "a company that one day", "company that one day "]word_dict = paddle.dataset.imikolov.build_dict() dict_size = len(word_dict)步骤三:定义模型结构
此处我们采用paddlepaddle内置的api来直接构建embedding层,其主要实现了词向量输入层的功能,可参考以前发的文章中对NLM模型的讲解来了解其具体的实现细节。
def inference_program(words, is_sparse): # 注意以下几点: # (1)启用is_sparse来加速稀疏矩阵的训练 # (2)设置param_attr来保证参数是被共享的(在paddle中,将参数属性中的名称设置一致就可以保证参数共享,即同一套参数),也就是说下面的4个输入对同一个embedding矩阵进行查表操作。 embed_first = fluid.embedding( input=words[0], size=[dict_size, EMBED_SIZE], dtype='float32', is_sparse=is_sparse, param_attr='shared_w') embed_second = fluid.embedding( input=words[1], size=[dict_size, EMBED_SIZE], dtype='float32', is_sparse=is_sparse, param_attr='shared_w') embed_third = fluid.embedding( input=words[2], size=[dict_size, EMBED_SIZE], dtype='float32', is_sparse=is_sparse, param_attr='shared_w') embed_fourth = fluid.embedding( input=words[3], size=[dict_size, EMBED_SIZE], dtype='float32', is_sparse=is_sparse, param_attr='shared_w') # 链接起来,尺寸大小为batch_size * 上下文单词数 * embedding size concat_embed = fluid.layers.concat(input=[embed_first, embed_second, embed_third, embed_fourth], axis=1) sum_embed = fluid.layers.reduce_sum(concat_embed, dim=1, keep_dim=True) # 融合操作,此处用求和 hidden1 = fluid.layers.fc(input=sum_embed, size=HIDDEN_SIZE, act='sigmoid') predict_word = fluid.layers.fc(input=hidden1, size=dict_size, act='softmax') return predict_word步骤四:训练流程定义
首先定义数据读取器,其本质就是将前面定义的句子进行合适的处理,以便于喂给模型。
def data_reader(): def reader(): for sent in sentences: words = sent.split(' ') # 本次就固定取中心的词作为中心词,事实上在真正实践的时候,也可以通过不同的句子切分手段,随机选取构造。 centre_word_index = 2 surround_words = [] # 由于采用的词典key值是bytes类型的字符串,因此这里也需要转换一下 target_id = word_dict[bytes(words[centre_word_index], encoding="utf8")] # 目标词的词表id for i, word in enumerate(words): if i == centre_word_index: continue if word == "" or word == "": input_id = word_dict[word] else: input_id = word_dict[bytes(word, encoding="utf8")] surround_words.append(input_id) # 上下文词的词表id yield [surround_words[0],surround_words[1],surround_words[2],surround_words[3],target_id] return reader再进行训练主流程的定义,这部分不同框架以及不同任务实现的方法不太一样,可以按需进行修改。
# 训练主流程def train(if_use_cuda, params_dirname, is_sparse=True): place = fluid.CUDAPlace(0) if if_use_cuda else fluid.CPUPlace() train_reader = paddle.batch(data_reader(), BATCH_SIZE) test_reader = paddle.batch(data_reader(), BATCH_SIZE) # 定义输入 first_word = fluid.data(name='firstw', shape=[None, 1], dtype='int64') second_word = fluid.data(name='secondw', shape=[None, 1], dtype='int64') third_word = fluid.data(name='thirdw', shape=[None, 1], dtype='int64') forth_word = fluid.data(name='fourthw', shape=[None, 1], dtype='int64') next_word = fluid.data(name='nextw', shape=[None, 1], dtype='int64') word_list = [first_word, second_word, third_word, forth_word, next_word] feed_order = ['firstw', 'secondw', 'thirdw', 'fourthw', 'nextw'] main_program = fluid.default_main_program() star_program = fluid.default_startup_program() predict_word = inference_program(word_list, is_sparse) avg_cost = train_program(predict_word) test_program = main_program.clone(for_test=True) optimizer = optimizer_func() optimizer.minimize(avg_cost) exe = fluid.Executor(place) def train_test(program, reader): count = 0 feed_var_list = [ program.global_block().var(var_name) for var_name in feed_order ] feeder_test = fluid.DataFeeder(feed_list=feed_var_list, place=place) test_exe = fluid.Executor(place) accumulated = len([avg_cost]) * [0] for test_data in reader(): avg_cost_np = test_exe.run( program=program, feed=feeder_test.feed(test_data), fetch_list=[avg_cost]) accumulated = [ x[0] + x[1][0] for x in zip(accumulated, avg_cost_np) ] count += 1 return [x / count for x in accumulated] def train_loop(): step = 0 feed_var_list_loop = [ main_program.global_block().var(var_name) for var_name in feed_order ] feeder = fluid.DataFeeder(feed_list=feed_var_list_loop, place=place) exe.run(star_program) for pass_id in range(PASS_NUM): for data in train_reader(): avg_cost_np = exe.run( main_program, feed=feeder.feed(data), fetch_list=[avg_cost]) if step % 10 == 0: outs = train_test(test_program, test_reader) print("Step %d: Average Cost %f" % (step, outs[0])) if outs[0] < 1: if params_dirname is not None: fluid.io.save_inference_model(params_dirname, [ 'firstw', 'secondw', 'thirdw', 'fourthw' ], [predict_word], exe) return step += 1 if math.isnan(float(avg_cost_np[0])): sys.exit("got NaN loss, training failed.") train_loop()def main(use_cuda, is_sparse): if use_cuda and not fluid.core.is_compiled_with_cuda(): return params_dirname = "word2vec.inference.model" train( if_use_cuda=use_cuda, params_dirname=params_dirname, is_sparse=is_sparse)main(use_cuda=use_cuda, is_sparse=True)步骤五:done!执行看看!
至此,我们已经实现了基于CBOW的word2vec模型,执行这份代码,可以得到如下图所示的输出,可以看到,模型的loss在不断的下降。
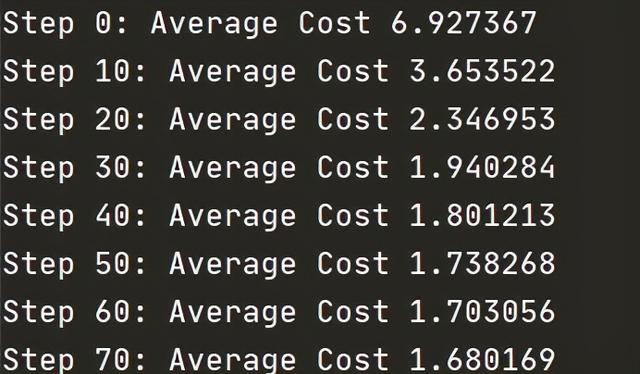
因为我们的数据集极小,所以模型的收敛过程是十分快速的,在面对大型工程的时候,可能需要更多的训练技巧来加速模型的收敛(如果大家感兴趣,我将会在后续给出相关的实践方法)。
结语:
在这一章中,我们介绍了word2vec并通过paddlepaddle手把手的实现了CBOW。那么当模型充分训练后,我们就可以将训练好的词向量矩阵作为NLP任务的基础信息在不同任务中使用。在信息检索中,我们可以根据向量之间的余弦值来判断查询与文档关键词之间的相关性。而在在句法分析和语义分析中,可以使用经过训练的词向量来初始化模型,进而获得更好的结果。在文本分类中,获取词向量之后,我们可以对文本中的同义词进行聚类,也可以使用N-gram来预测下一个单词。作为NLP发展历史中的一个重要进展,希望大家在阅读本文后,能够更深入的理解word2vec的理论并了解到其工程实现的方法。
如果你觉得我的文章有价值,请持续关注我,我会持续更新。















 4402
4402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









