






在上一篇中,我们使用了多种方法对肝炎数据集中的缺失值进行填充,在这个过程中,也对数据集的数据结构和基本信息有了一定的了解。下面,让我们进一步对肝炎数据集进行分析。
主要知识点:决策树、随机森林
前文回顾:
侦探L:Pandas与机器学习实例——肝炎数据集(1)zhuanlan.zhihu.com
正文开始~
一、回顾一下我们的数据集,进行信息提取:
df.head()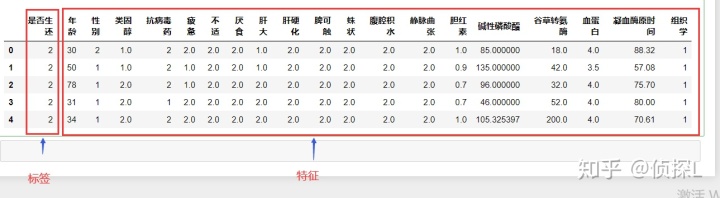
大家看一下上图我标注的地方,实际上,我们的数据表可以看成一个由“标签”和‘特征’组成的集合。
在数据表中,每一行数据相当于一个样本,而不同的样本有着自己独一无二的“特征”和“标签”。特征是样本的具体表现,而样本的所有特征,最终都会作用于标签。
换句话说,
标签是我们要预测的事物,相当于简单线性回归中的 y 变量。
特征相当于是输入变量,相当于简单线性回归中的 x 变量。
简单的机器学习项目可能会使用单个特征,而比较复杂的机器学习项目可能会使用数百万个特征。相当于Y=f(X1, X2, X3, ... , Xn)。
回到我们的数据集:
在‘是否生还’这一列中,1表示患者死亡,2表示患者生还,我们下面要做的事情,就是研究一下其他的特征列(也即是患者的症状、性别、年龄)是否会影响患者的生还率,以及影响的程度如何。
二、建立模型
(1)建立决策树模型进行数据分析
1、将数据集分割成训练集和测试集
导入做决策树相应需要的包:
from sklearn import tree
from sklearn.model_selection import train_test_split首先,将原数据集按特征和目标进行分割:
df_x=df.drop(labels='是否生还',axis=1)
df_y=df.loc[:,'是否生还']

然后,使用train_test_split将数据分成训练集和测试集。
注意~在这里我们指定了拆分系数为0.3,也是说将7/10的数据作为训练集,剩下3/10的数据作为测试集。
X_train, X_test, Y_train, Y_test = train_test_split(df_x,df_y,test_size=0.3)拆分成功~查看一下拆分后训练集和测试集的数据。
X_train.shape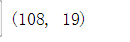
X_test.shape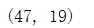
下面开始建模,并使用X_train,和Y_train进行数据训练:
clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(X_train, Y_train)查看一下在测试集上的准确度(将经过训练集训练后的模型,应用到测试集里,并查看拟合的得分情况)
score = clf.score(X_test, Y_test)
score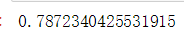
使用GridSearchCV 网格搜索对决策树进行调参并返回最佳参数:
先计算最优深度:
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier, export_graphviz
tree_params = {'max_depth': range(5, 12)}
locally_best_tree = GridSearchCV(DecisionTreeClassifier(random_state=17),
tree_params, cv=5)
locally_best_tree.fit(X_train, Y_train)查看一下结果:
print("最优深度:{}".format(locally_best_tree.best_params_))
设置最优深度为6后,重新计算得分情况:
clf = tree.DecisionTreeClassifier(criterion="entropy",max_depth=6, random_state=17)
clf = clf.fit(X_train, Y_train)
score = clf.score(X_test, Y_test)
print("最优深度下的得分情况:{}".format(score))
2、根据结果,我们可以画出一个决策树~
feature_name=[ '年龄', '性别', '类固醇', '抗病毒药','疲惫','不适','厌食','肝大','肝硬化','脾可触','蛛状','腹腔积水','静脉曲张','胆红素'
,'碱性磷酸酯','谷草转氨酶','血蛋白','凝血酶原时间','组织学']
import graphviz
clf = tree.DecisionTreeClassifier(criterion="entropy",max_depth=6, random_state=17)
clf = clf.fit(X_train, Y_train)
dot_data = tree.export_graphviz(clf
,out_file = None
,feature_names= feature_name
,class_names=["病逝","治愈"]
,filled=True
,rounded=True
)
graph = graphviz.Source(dot_data)
graph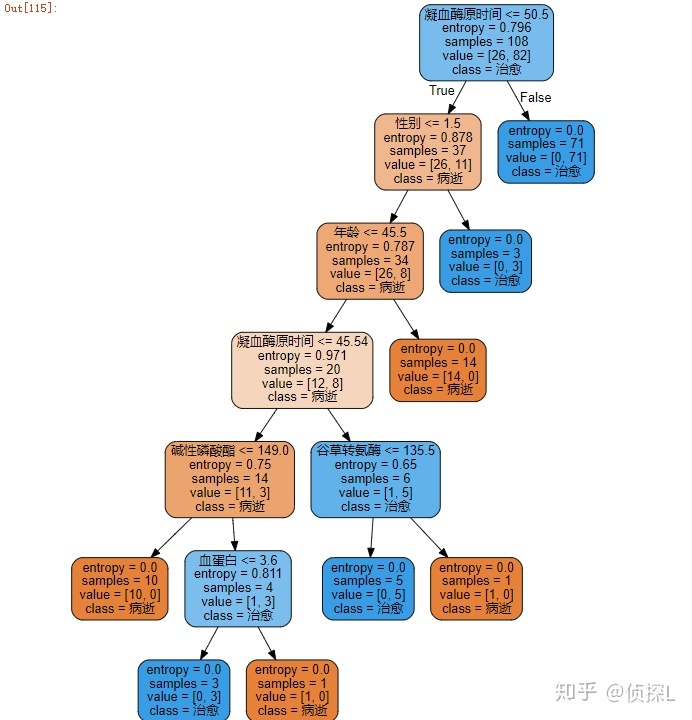
如果想要自己运行代码作出决策树的同学,需要进行下面三个步骤:
- 安装graphviz:
下载地址:http://www.graphviz.org/。如果是windows,就在官网下载msi文件安装。安装完后要设置环境变量:将graphviz的bin目录加到PATH。
- 安装python插件graphviz:
pip install graphviz
- 安装python插件pydotplus:
pip install pydotplus
(不懂的同学可以百度一下~有空我也会专门写一篇这方面的文章)
(2)建立随机森林模型进行数据分析
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=100, random_state=17)
rf.fit(X_train, Y_train)查看拟合的得分情况:
score = rf.score(X_test, Y_test)
print("随机森林的得分情况:{}".format(score))
可以看到,使用随机森林模型的拟合得分要明显高于决策树模型,比较可惜的是,随机森林是无法被可视化的。
以上便是<Pandas与机器学习实例——肝炎数据集(2)>的内容,感谢大家的细心阅读,同时欢迎感兴趣的小伙伴一起讨论、学习,想要了解更多内容的可以看我的其他文章,同时可以持续关注我的动态~















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









