






摘要
基于注意力的神经模型在自然语言推理(NLI)中取得了巨大的成功。在本文中,我们提出了卷积交互网络(CIN),它是捕获两个句子之间交互的通用模型,可以替代NLI的注意力机制。具体而言,CIN使用基于另一句话动态生成的过滤器对一个句子进行编码。由于可以自由设计过滤器数量和大小,因此CIN可以捕获更复杂的交互模式。在三个非常大的数据集上进行的实验证明了CIN的功效。
1 介绍
自然语言推理(NLI)是一项至关重要的挑战性自然语言处理(NLP)任务。NLI的目标是识别前提和相应假设之间的逻辑关系(蕴含,中立或矛盾)。通常,在两个文本的语义匹配范式下,NLI也与许多其他NLP任务相关,例如问题回答Hu等人(2014年);Wan等人(2016年)和信息检索Liu等人(2015),等等。一个基本挑战是捕获两个句子的语义相关性。由于语义鸿沟(或词汇鸿沟)问题,自然语言推理仍然是一个具有挑战性的问题。
最近,深度学习引起了人们对自然语言推理的极大兴趣,并取得了一些重大进展(2014) ;Parikh等人(2016);Chen等人(2017a)。为了对两个句子之间的复杂语义关系进行建模,先前的模型大量利用了各种注意机制Bahdanau等人(2014)。Aswani等人(2017)建立不同粒度(单词,短语和句子级别)的交互,例如ABCNN Yin等人(2016),注意力的LSTM Rocktäschel等人 (2015),双向注意力LSTM Chen等(2017a),等等。尽管注意力在自然语言推理中非常成功,但其机制却非常简单,可以视为目标向量的加权和。这种范例导致在更复杂的交互模式下缺乏灵活性。
在本文中,我们提出了一个新的交互模块,称为卷积交互网络(CIN),它可以用作注意机制的替代模块。具体而言,CIN利用卷积神经网络从句子中提取有价值的特征(或表示)。对于NLI,一个句子的特征是否重要取决于另一个句子。受使用一个网络生成另一个网络参数的想法启发,Ha等人(2016a);De Brabandere等(2016),我们引入了一个过滤器生成网络来动态生成卷积过滤器。每个句子由另一个句子动态生成的过滤器卷积。因此,一个句子的卷积特征可以看作是另一句子影响下的上下文感知表示。
本文的贡献可归纳如下。
1.CIN是一种新的交互模型,是作为注意力模型的替代模块而发明的。CIN还可以捕获两个句子的内部的交互。
2.与注意力模型相比,CIN更通用,更灵活,可以捕获复杂的交互。如本节3.3所述,注意力模型大约等效于CIN的特殊情况。
3.我们对三个非常大的数据集进行了广泛的实证研究。实验结果表明,我们提出的体系结构对自然语言推理是有效的。
2. 自然语言推理的注意力交互
当前,自然语言推理的主要方法是使用注意力机制来模拟两个句子之间的交互。给定两个输入句子x = [,,...,]和y = [,,...,]的长度分别为m和n,我们首先将它们编码为两个矢量序列。
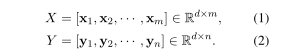
编码器通常由一个或几个CNN / RNN层组成,以获取上下文感知的单词表示。为了捕获两个句子之间的交互,可以使用各种神经注意力,例如sentence2word注意力Rocktäschel等人(2015),word2word注意力Parikh等人(2016);Chen等人(2017a)。
「Word2word注意力交互」 word2word注意分别从相关的两个句子中捕获了两个单词和之间的依存关系。word2word注意力计算了相似度矩阵M,其中每个元素i和和之间的对齐分数。
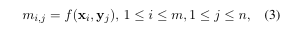
其中f是得分函数。
有两种最普遍的注意:乘法注意和加性注意。乘性注意是:
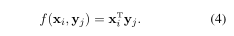
加法注意力由具有单个隐藏层的前馈网络计算兼容性函数。
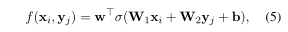
其中,,和是可学习的参数,
尽管这两种注意具有相似的性能,但是乘法注意在实践中更受欢迎,因为它需要较少的计算能力,并且通过优化的矩阵乘法具有较少的内存需求。有了乘法注意,我们可以计算X和Y的模拟表示。
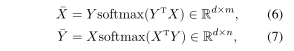
其中softmax(·)是列式归一化函数。每个向量∈X被称为模拟向量,它是 = 1的加权和。直观上,模拟向量提供了从句子Y中提取的单词的相关信息。
「预测」 交互后,使用预测模块汇总交互信息并提取两个句子的定长表示。最后,将最终的句子表示形式馈入前馈网络以预测两个句子之间的关系。
3 卷积交互网络
在本节中,我们提出了一种利用动态卷积滤波器的新交互方法,称为卷积交互网络(CIN)。CIN可以用作注意机制的替代模块。我们首先简要介绍卷积如何在文本序列上工作,然后描述所提出的模型与注意力模型的联系。
3.1 序列上的卷积
卷积是深度神经网络中的一种有效操作,它将输入与一组过滤器进行卷积以提取非线性成分特征。尽管卷积模型最初是为计算机视觉设计的,但后来证明对NLP有效,并且在句子建模中取得了出色的表现Kim(2014);Kalchbrenner等(2014),以及其他传统的NLP任务Hu等(2014);Zeng等(2014);Gehring等(2017)。
给定一个句子表示X = [,,···,]∈,卷积滤波器∈×,卷积过程定义为:
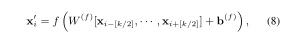
其中f(·)是非线性激活函数,例如ReLU,k表示卷积窗口的大小,∈是偏差矢量。卷积可以缩写为
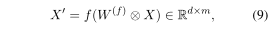
其中⊗表示卷积运算。为了确保卷积的输出与输入的长度相等,我们在输入端的两边填充[k/2]个零向量。
3.2 卷积交互网络
当从句子中提取有用的特征时,卷积非常有效。但是对于NLI任务,单词(或特征)在一个句子中是否重要取决于另一个句子。因此,更好的卷积运算应具有从一个句子根据另一个句子中提取实质特征的能力。因此,卷积滤波器应该是动态可变的。受到贾等人的启发(2016);Ha等(2016b),我们提出了一个过滤器生成网络(FGN)来生成动态过滤器,该动态过滤器用于提取上下文感知信息。
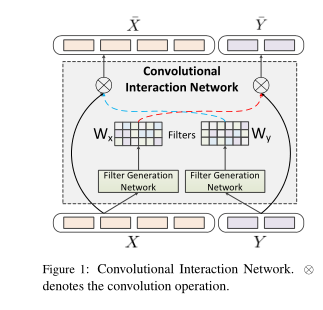
给定两个句子x,y及其表示形式X = [,,···,]∈和 Y = [,,···,]∈,每个句子的过滤器是根据另一句话生成的。
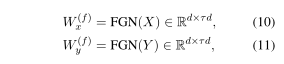
其中τ是过滤器的宽,FGN(·)是滤波器生成网络。第3.4节介绍了FGN的详细实现。
现在我们可以用生成的过滤器对两个句子进行卷积。
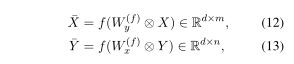
其中获得的矩阵X和Y可以看作是句子x和y的上下文感知表示,矩阵X和Y都共同取决于x和y。
3.3 与注意力交互的联系
CIN比注意模型更具概括性。假设我们设置k = 1且FGN表示为FGN(X)= 的函数,等式12和 等式13的CIN的可以写成:
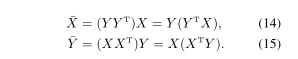
与等式(6)和(7)相比,在上述假设下,CIN等同于没有softmax归一化的word2word乘法注意力模型。
3.4 过滤器生成网络(FGN)的实现
要生成动态过滤器,关键因素是如何在等式(10)和(11)中选择过滤器生成网络FGN(·)。尽管可以使用许多复杂的网络,但我们在本文中给出了一个简单的实现。
为了便于说明,我们仅描述如何根据句子x生成动态过滤器。句子y使用相同的过程。首先,我们用X上的 k-max pooling over-time来提取句子x中的信息。
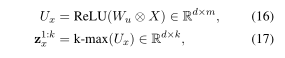
1max pooling over time如下图

k max-pooling over time 自然是取最大的k个值
其中是X通过卷积过滤器∈的非线性变换。k-max池化的想法是捕获句子X中最重要的特征(k个最大值)。
然后我们根据下式,生成k个过滤器,j= 1,···,k:
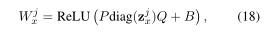
其中P∈R,Q∈τ和B∈τ都是可学习的参数。
最终的过滤器是通过串联生成的k个过滤器而获得的,
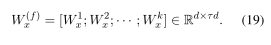
类似于x,我们还可以根据句子y获得动态滤波器。
4 将CIN整合到用于NLI任务的深度网络架构中
我们针对NLI的整体网络架构基于Chen等人提出的成功模型(2017a)。主要区别在于我们使用CIN来捕获交互,而不是双向注意力模型。
该网络体系结构由三个组件组成:(1)编码层; (2)卷积交互层;(3)预测层。图2给出了一个说明。
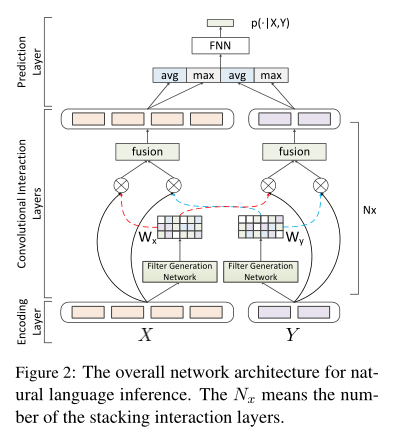
4.1编码层
自然语言推理任务的输入是一对句子x和y。由于句子中的每个单词都是神经网络无法直接处理的符号,因此我们需要首先将每个单词映射到d维嵌入向量。
因此,这两个句子分别映射到两个矩阵∈R和∈。我们还使用语法和词汇信息,例如部分语音标记信息,精确匹配特征和字符表示。如果相关单词与对应句子中的任何单词具有相同的词干,则将每个单词的精确匹配值设置为1(默认为0)。单词的字符表示是使用卷积神经网络沿着序列长度维度进行最大池化获得的,方法与Kim(2014)相同。单词的最终表示形式是词嵌入,字符编码向量,POS标注(词性标注)嵌入和精确匹配特征的连接(concatenation)。字符嵌入和POS标签嵌入都是随机初始化的。在训练期间,所有嵌入都将在训练过程中更新。
我们使用双向LSTM(BiLSTM)Hochreiter和Schmidhuber(1997)来合并序列的前向和后向上下文信息。因此,我们可以得到两个输入句子的短语级别编码,
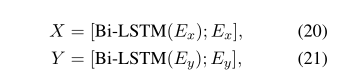
其中and Y∈分别是句子x和y的短语级编码表示。
4.2 卷积交互层
在交互层中,我们使用提出的CIN来建模两个句子之间的交互。我们首先分别基于句子编码X和Y动态生成上下文感知过滤器和,这些过滤器还用于句子内和句子间交互。
「句内交互」 句内卷积交互作用是通过其自身生成的过滤器对自身进行卷积。
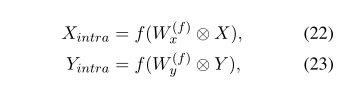
句子内卷积交互作用的作用与自注意力作用相同,这在NLI中也非常有用。
「句间交互」 句间交互的公式如下:
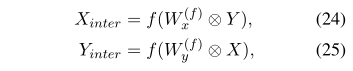
句间卷积交互的作用类似于两个句子之间的交叉注意力。
「融合层」 在CIN之后,我们可以融合每个句子的两种上下文感知表示。对于句子x,和分别代表考虑其自身和句子y信息的提取的特征。
为了有效利用和 ,我们使用了融合层。我们使用Chen等人(2017a)提出的比较操作。 融合了两种表示形式。令和等于句子x中第i个单词的内部和内部关注向量,使用启发式有效组合运算符来组合两个向量。
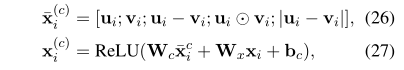
因此,我们可以获得两个句子的两个融合表示()和(),它们被进一步馈送到预测层或另一个堆叠的交互层中。可以将交互层堆叠次以捕获复杂的匹配信息。
4.3 预测层
在交互层之后,使用聚合层将融合向量()和()的两个序列聚合为固定长度的匹配向量。聚合组件通常由另一个BiLSTM层和随后的合并层组成。然后,我们对()和()进行最大池化,以得到两个句子和的两个固定表示向量:
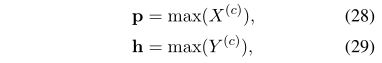
其中max函数是max pooling over times操作
最后,将池化后的向量组合为一个关系向量,并馈入前馈网络以预测两个句子之间的关系。特别是,两层前馈网络具有一个使用tanh激活函数的隐藏层,输出层采用softmax。
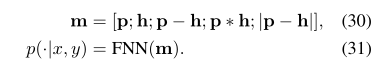
5 训练
给定一个训练集(,,),目标是最小化交叉熵损失θ,其中θ表示所有连接权重:
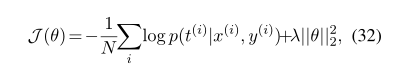
我们使用Adam优化器Kingma和Ba(2014)的初始学习率为0.0004。默认的L2正则化λ设置为。为了避免过度拟合,在每个完全连接的循环层或卷积层之后都应用了dropout。
「初始化」 我们利用诸如Glove Pennington等人的经过预训练的单词嵌入(2014)从大量未标记的数据中转移更多的知识。对于未出现在Glove中的单词,我们从均值为0.0,标准差为0.1的正态分布中随机初始化其嵌入。
网络权重的初始化,使用Glorot和Bengio(2010)的Xavier标准化(normalization),以在整个前向和后向传递中保持激活的方差。构建网络时,偏差始终设置为零。
5.1 数据集
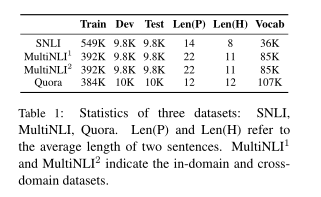
了进行定量评估,我们的模型在三个众所周知的数据集上进行了评估:斯坦福自然语言推理数据集(SNLI),MultiNLI数据集和Quora问题对数据集(Quora)。这些数据集的详细统计信息如表1所示。
5.2 总体结果
我们使用准确性来评估卷积交互网络(CIN)和其他模型在SNLI,MultiNLI和Quora上的性能。
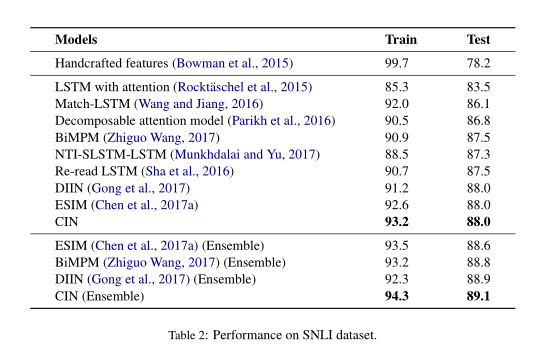
「SNLI」 表2显示了SNLI的训练集和测试集上不同模型的结果。第一行给出了由Bowman等人提出的具有手工特征的基线模型(2015)。所有其他模型都是基于注意力的神经网络。Wang and Jiang(2016)利用了LSTM来解决NLI问题,Parikh等(2016)使用注意力将问题分解为可以单独解决的子问题。Chen等(2017a)将链LSTM和树LSTM结合在一起。yZhiguo Wang (2017)提出了针对NLI的双边多视角匹配模型。
在表2中,第二部分给出了单模型效果。如我们所见,我们提出的模型CIN在SNLI测试集上的准确度达到88.0%。与以前的工作相比,CIN获得了竞争优势。
为了进一步提高NLI系统的性能,研究人员建立了集成模型。集成系统在SNLI上获得了最佳性能。我们的集成模型获得了89.1%的准确度,并且优于当前的最新模型。
总体而言,CIN的单个模型在竞争中表现出色,并且在自然语言推理任务的整体场景中优于以前的模型。
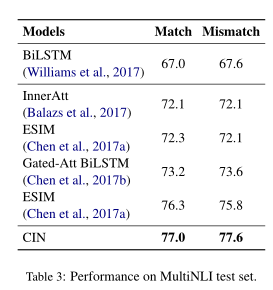
「MultiNLI」 表3显示了不同模型在MultiNLI上的性能。该数据集的最初目的是评估句子表示的质量。最近,该数据集还用于评估涉及注意力机制的交互模型。表3的第一行给出了没有交互作用的基线模型。表3的第二部分给出了基于注意力的模型。我们提出的模型CIN在匹配和不匹配测试集上分别达到77.0%和77.6%的准确性。结果表明,我们的模型优于其他模型。
5.3 消融实验
为了更好地了解我们模型的性能,我们分析了所提出模型的每个关键组成部分的影响。如表5所示,第一行是完整的CIN模型。通过删除卷积交互层,测试集上的性能下降到85.1%,这表明交互信息对于NLI至关重要。通过丢弃落句子内注意力交互,测试集上的性能将降低到87.7%。根据结果,所有组件均对最终性能产生积极影响。
5.4 案例学习
为了直观地了解我们的模型是如何工作的,我们对以下测试案例进行了分析:

可视化结果是由具有两个堆叠CIN的模型产生的。X,Y是编码层的隐藏状态,(),()是第一CIN层的隐藏状态。对于隐藏状态的单词,我们可以计算它的梯度比例以显示其对最终预测的贡献。表6示出了编码层和第一CIN层中每个单词的隐藏状态的梯度标度。我们可以看到,在CIN层之后,某些短语(例如,playing a violin和playing an instrument)而不是孤立的单词(例如,violin和 instrument)变得更加集中。这意味着CIN可以捕获一些更高级别的模式。

图3直观地显示了两个句子的隐藏状态的相关性。(a)显示了编码层之后的相关性,相同的单词相关性最高。这是因为前提和假设之间共享嵌入层和编码层。 (b)显示了在第一CIN层之后的相关性,该相关性存在于短语{playing as violin vs playing an instrument}之间,而不是相同的词。交互层将“前提”中的演奏连接到“假设”乐器,并将“假设”中的演奏连接到“前提”小提琴。因此,假说中的乐器与前提中的小提琴之间的相关性得到了增强,因为我们知道这些对推理很重要。
6 相关工作
与我们相关的工作主要有两个部分。
一个部分是将基于注意力的模型用于自然语言推理(NLI)。NLI已被广泛研究多年。受益于深度学习的发展以及大规模带注释数据集的可用性,深度神经模型取得了巨大的成功。Rocktäschel等。 (2015年)首先使用LSTM进行文本匹配任务。Wang和Jiang(2016)使用逐词注意力来开发词级匹配。Parikh等(2016)提出了一个新的框架来使用交互比较比较聚合架构来模拟两个句子之间的关系。Chen等(2017a)将链LSTM和树LSTM结合在一起。Zhiguo Wang(2017)使用自注意力机制从整个句子中捕获上下文信息。
与上述模型不同,我们使用替代模型来捕获两个句子的复杂交互信息。
另一个部分是使用一个网络生成另一个网络的参数的想法。De Brabandere等(2016)提出了动态过滤器网络来隐式学习各种特征提取操作。Ha等(2016a)提出了模型超网络,该模型使用小型网络为大型网络生成权重。
与这些模型不同,我们使用动态过滤器进行交互。因此,提出了一种过滤器生成功能来捕获句子对间和内部相关信息。
7 总结
在本文中,我们提出了用于自然语言推理的替代交互模型卷积交互网络(CIN)。CIN利用动态卷积过滤器对两个句子之间的交互进行建模。具体而言,每个句子都由基于另一个句子生成的动态过滤器进行卷积。CIN更通用,更灵活,因为过滤器可以具有各种数量和大小,从而捕获更复杂的交互模式。在三个非常大的数据集上进行的实验证明了我们提出的模型的有效性。
在未来的工作中,我们希望改善CIN的可扩展性并将其应用于其他NLP任务,例如机器理解。















 2186
2186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









