





监督学习比较好的一点就是输入输出都是确定的,我们进行学习,其本质就是猜权重。
如下图,设输入为1,2,真实结果为10,随机生成的权重为wa=2,wb=3:

预测值为1*2+2*3=8,与真实值误差10-8=2。接着我们要调整权重值,减少输出的预测值与真实值的误差。
因为两个权重大小不一,对结果的影响自然也不同,所以应该按比例调整。
wa占比2/(2+3)=0.4wb占比3/(2+3)=0.6相比之前将输入的值计算后输出的正向传播来说,这次是通过结果误差反推权重,即为反向传播。
接着扩充一下神经网络:
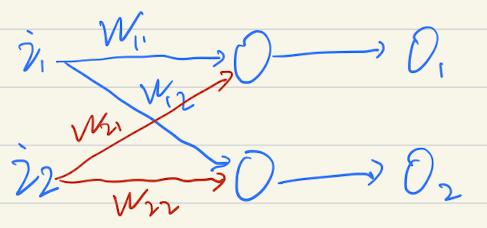
设输入

权重值

输出
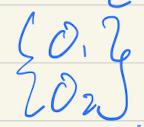
误差值

真实值

e1=t1-o1e2=t2-o2那么调整的w11权重值应该就是 e1*w11/(w11+w21),其他权重值同理。用矩阵表示就是:

简化为:
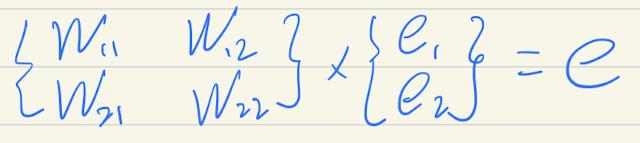
虽然去除了分母,但反馈效果也是有效的,且更加简单,便于理解和计算。
我们对比一下之前的计算矩阵:
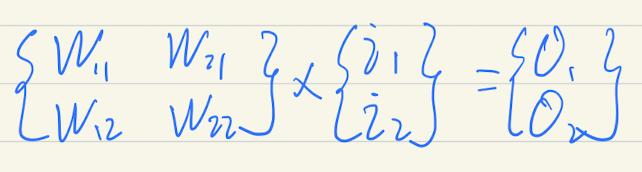
简化为

我们可以注意到反向传播中的权重矩阵恰好是正向传播中的权重矩阵的转置矩阵,则反向传播的公式可以简化为:

接着说误差。前面说了,我们训练的目的就是尽可能地缩小误差,设真实值为t1,t2,预测值为o1,o2,误差为e1,e2,总误差为e。直觉告诉我们,误差应为:
e=e1+e2=(t1-o1)+(t2-o2)但这里有一个问题,假设e1=100,e2=-100,两个预测值的误差极大,但二者相加,总误差=0,说明整体没有误差。显然是不合适的。
实际工作中,常用的误差函数有交叉熵,均方差等。本文简单说一下均方差(MSE)。
设输出值数量为n,t为真实值,o为预测值,公式如下:

MSE越接近0,说明预测效果越好。
也有资料给的是和方差SSE:

其实就是MSE没有除n。
MSE、SSE以及均方根RMSE其实同属一宗,效果一样的。
最后说说梯度下降。设有函数y=wx+1,我们知道当x=1时,y=4;x=2,y=7。
当函数很简单的时候,我们可以解出w=3,但如果函数很复杂,很难求出解的适合,可以采用步进的方式去接近解。例如我们可以先随机猜w=5,则:
y=5*1+1=6>4由此可知,w=5应该比真实权重值大一些,那么我们就再选个<5的。
猜w=-2
y=-2*1+1=-1<4由此可知,w=-2应该比真实权重值小一些,那么我们就在(-2,5)这个范围内选值。
这就是梯度下降,每更新一次权重,都希望误差下降一些,直到逼近精确解。
刚才我们选了5为权重值,误差值为(4-6)²/2=2,-2为权重值时,误差值为(4+1)²/2=12.5
误差值反而变大了,这就是超调。避免超调,调整权重值的时候,步子不能迈得太大,否则容易......
所以我们采用小步长,比如5-->4-->3.5-->3.2--3.02......
这就是学习率lr,这个是超参数,由人来指定。每训练一次后,lr都要进行衰减,目的是使算法尽快收敛。
梯度下降有:
批量梯度下降(Batch Gradient Descent)BGD,计算所有样本,得到结果,取得误差值,以此再训练。
时间长,但能收敛到全局最优解,非凸函数可以收敛到局部最优解。
随机梯度下降(Stochastic Gradient Descent)SGD,随机取一个样本进行训练。
时间短,容易局部最优,固定在鞍点。
小批量梯度下降(Mini-Batch Gradient Descent)MBGD,每次取N个(一般=10)进行训练。














 6097
6097











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









