






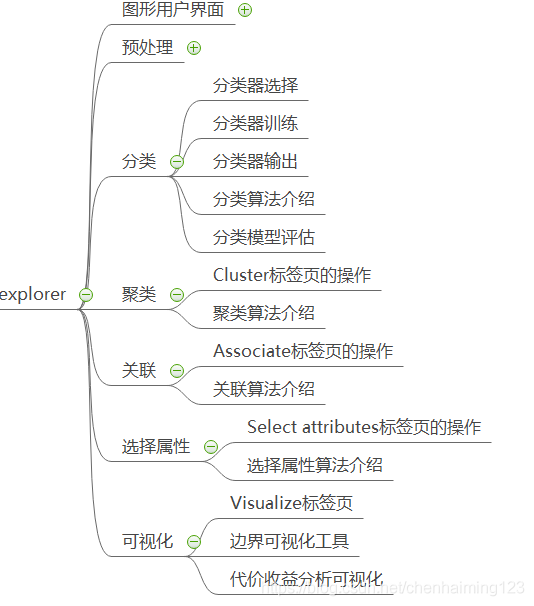
一、思维导图总结
二、过滤器的代码设计
package com.Sple;
import weka.core.Instances;
import weka.core.converters.ConverterUtils;
import weka.filters.Filter;
import weka.filters.unsupervised.attribute.Add;
import weka.filters.unsupervised.attribute.Standardize;
import java.util.Random;
//即时过滤361页---
//加载数据集,添加一个数值型属性和一个标称型属性,最后用随机值填充新增的两个属性并输出数据。
public class BatchAddFiltering {
public static void main(String[] args) throws Exception {
//预处理
try {
// load dataset
Instances instancestrain= ConverterUtils.DataSource.read("D://java-weka//Weka-3-8-5//data/segment-test.arff");
System.out.println("数据集内容:"+instancestrain);
Instances instancestest = ConverterUtils.DataSource.read("D://java-weka//Weka-3-8-5//data/segment-test.arff");
System.out.println("数据集内容instancestest:"+instancestest);
//使用标准化过滤器
Standardize filter=new Standardize();
//使用训练集一次初始化过滤器
filter.setInputFormat(instancestrain);
//基于训练配置过滤器,并返回过滤后的实例
Instances newTrain=Filter.useFilter(instancestrain,filter);
//过滤并创建新测试集
Instances newTest=Filter.useFilter(instancestest,filter);
//。。。。。。
//训练并输出模型,使其具有零均值和单位方差,如果设置了类别属性,则忽略之
System.out.println("新测试模型内容:"+newTest);
System.out.println("新训练模型内容:"+newTrain);
//新增了两个属性,NumericAttribute numeric和NominalAttribut
}catch (Exception e){
}
}
}
三、实验数据总结
该代码是使用源码进行测试的部分数据,根据数据特征信息,绘制散点图,计算数据的泊松分布和其他统计模型。其他模型的建立和线上使用方案还需进一步测试。
在统计模型中建立对映点时,需要认识数据内部逻辑和认识逻辑。在数学中,如果两个点完全相反,则它们是对映点(即,每个点都是另一个点的对映点)。示例包括线段的端点 或球体的极点。给定一个具有纬度和经度的球体上的点,对映点具有纬度和经度(采用符号以便结果介于和 之间)。 ![]()














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









