






我们在之前发布多篇文章深入讲解了贝叶斯思想、贝叶斯定理,对于贝叶斯定理体现的哲学思想、数学思想以及推理过程深刻挖掘,从不同角度予以理解其中的精妙之处。本文通过分析贝叶斯在线性回归中的应用,来理解贝叶斯在实际中的应用。
在贝叶斯观点中,我们使用概率分布而不是点估计来表示线性回归。我们估计响应y不是估计单个值,而是估计概率分布,即它是从哪个分布中得出的。就是贝叶斯应用于线性回归的关键观点。
贝叶斯线性回归相比于一般线性回归到底有什么好处,它的本质到底是什么?本文通过引入复杂度例子开始,讲解最小二乘法、极大似然法算法的优劣,最后引入贝叶斯线性回归,探究其机理,阐述其优点,推演出其本质!
复杂度
线性回归多项形式如下:
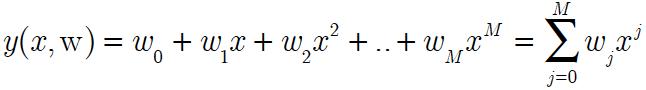
其模型复杂度为M,我们看看随着模型复杂度的增加,模型拟合sin(2pix)的效果。
下面就是当M=0,1,3,9时拟合数据的情况,当M=0时,是一条水平直线,M=1时一条斜的直线,当M=3时,接近拟合数据,但当M=9时,出现过拟合。
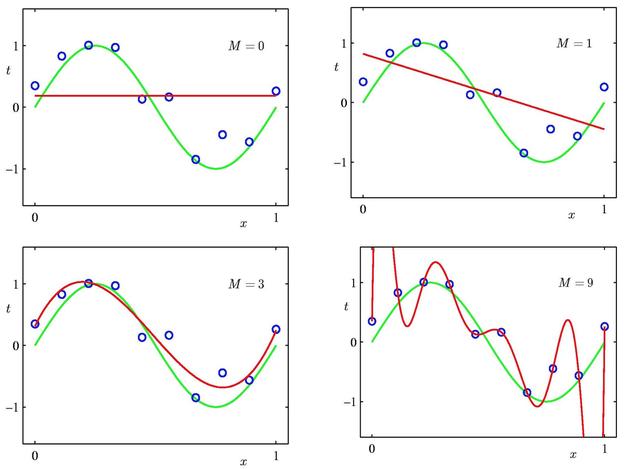
通过这个例子,对于线性回归,模型复杂度是很重要,与避免欠拟合和过拟合密切相关,而这个复杂度是不好把握的。
最小二乘法回归
Y= Xβ+ε
哪里Y是我们想要预测的输出(或因变量),X是我们的预测器(或自变量)和β是我们想要估计的模型的系数(或参数)。ε是一个误差项,假设是正态分布的。
然后我们可以使用普通最小二乘来找到最佳拟合β,那么其损失函数为:
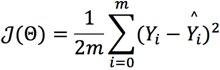
最小化这个函数有封闭形式的解:
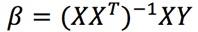
最小二乘法没有考虑模型复杂度。
极大似然回归
仍然假设:
Y= XW+ε
ϵ是随机误差,服从高斯分布ϵ∼N(0,σ2)。 我们要求的 P(Yi|Xi,W),这是先验概率,也就是在给定Xi、W条件下,目标值Yi的概率。概率越大,误差就应该越小。换个表达方式,就是ϵ接近于中心值0的概率越大,这正好与ϵ∼N(0,σ2)高斯分布的意义不谋而合。所以:
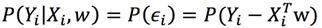
代入高斯分布概率密度函数中:
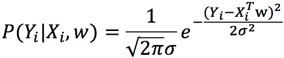
因为 Xi是相互独立的,所以:
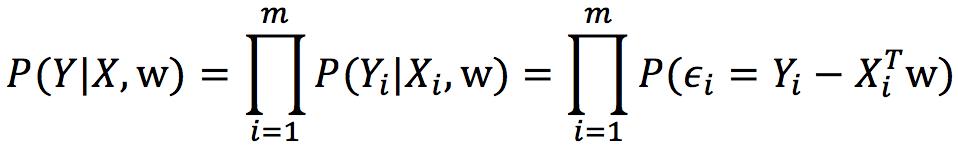
化简:
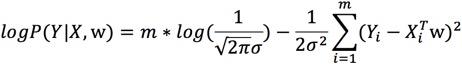
第一项是常数,最大化极大似然函数,就是最小化:

这个和最小二乘法的结果是一样的。
极大似然法仍然没有拷量模型复杂度。
MLE的缺点:
参数w的极大似然估计并不涉及模型复杂度,它完全由数据大小n控制。而使用贝叶斯方法可以更好地处理模型复杂度和过拟合。
使用贝叶斯规则,后验与Likelihood × Prior成正比:
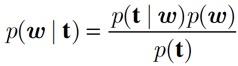
先验p(w)是高斯分布,似然p(t | w)是基于噪声模型的高斯
贝叶斯估计有两个关键优势:
第一、先验:我们可以通过在参数上放置先验来量化我们可能拥有的任何先验知识。例如,如果我们认为σ 可能很小,我们会选择一个先前的概率质量较低的值。
第二、量化不确定性:我们不是得到参数W的的单一估计,而是完全后验分布,关于W的不同值的可能性。例如,数据点很少,我们的W不确定性将是非常高,这样我们会充分利用数据,并且,会得到非常广泛的后验,解释面更宽。
贝叶斯线性回归
先验参数分布是高斯分布
假设w的多元高斯先验(其具有分量w0,..,wM-1)
p(w)=N (w|m0 , S0)
其平均值为m0和协方差矩阵S0
如果我们选择S0=α ^-1,则意味着权重的方差都等于α ^-1,协方差为零
数据的似然分布是高斯分布
假设噪声精度参数β,设线性回归实际函数t = y(x,w)+ε其中ε被概率地定义为高斯噪声p(t|x,w,β)=N(t|y(x,w),β^-1),输出t是标量
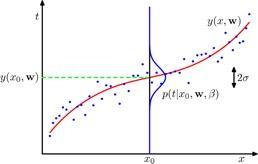
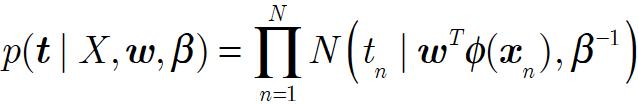
这是给定参数w和输入X = {x1,..,xN}的目标数据的概率,由于高斯噪声,似然p(t | w)也是高斯噪声
后验分布也是高斯分布
边缘分布p(w) 和条件分布p(t|w) 有高斯分布的形式,那么边缘分布p(t) and 条件分布p(w|t) 也是高斯。
后验分布的确切形式
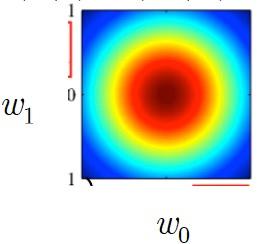
我们设定先验参数分布的均值为0,有相同的方差,协方差为零。
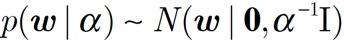
拿二维举例,如下:
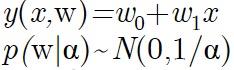
其概率密度分布图像为:
后验服从高斯分布,那么有以下形式:
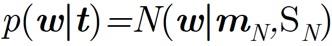
通过贝叶斯定理,由前边的先验、似然,可化简为高斯形式,可求得到:
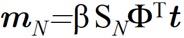
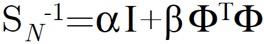
贝叶斯线性回归与正则化MLE的等价性
似然:
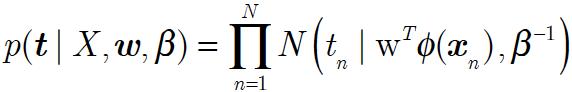
先验:
注意这里的α、β,是高斯分布的精确度
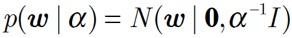
进而由贝叶斯定理求得:
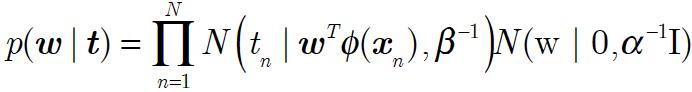
对数似然函数:

见证奇迹的时刻出现了,大家熟不熟悉这个形式啊?这不就是L2正则化形式的MLE么!
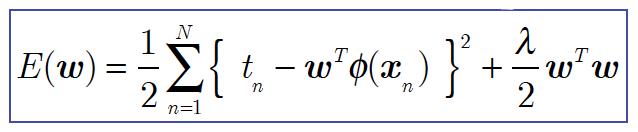
因此,后验的最大化等效于添加二次正则化项wTw(λ=α/β)的最小化平方和误差。
其中,似然函数部分对应于损失函数(经验风险),而先验概率部分对应于正则项。L2正则,等价于满足高斯分布的参数w的先验概率。














 473
473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









