







这是万物可述的第14篇原创文章
什么是实例?操作系统中一系列的进程以及为这些进程所分配的内存块,Oracle Instance = SGA + Background Process。如图:11G数据库体系结构
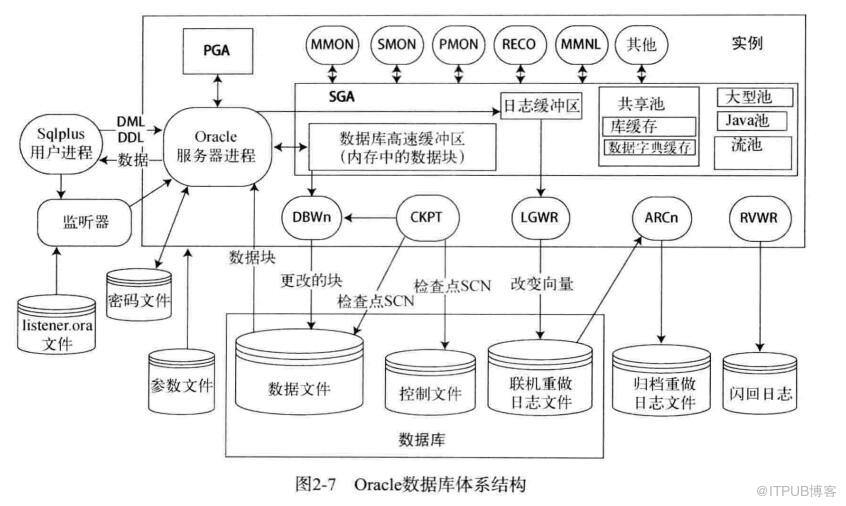 12C数据库体系结构-简版
12C数据库体系结构-简版
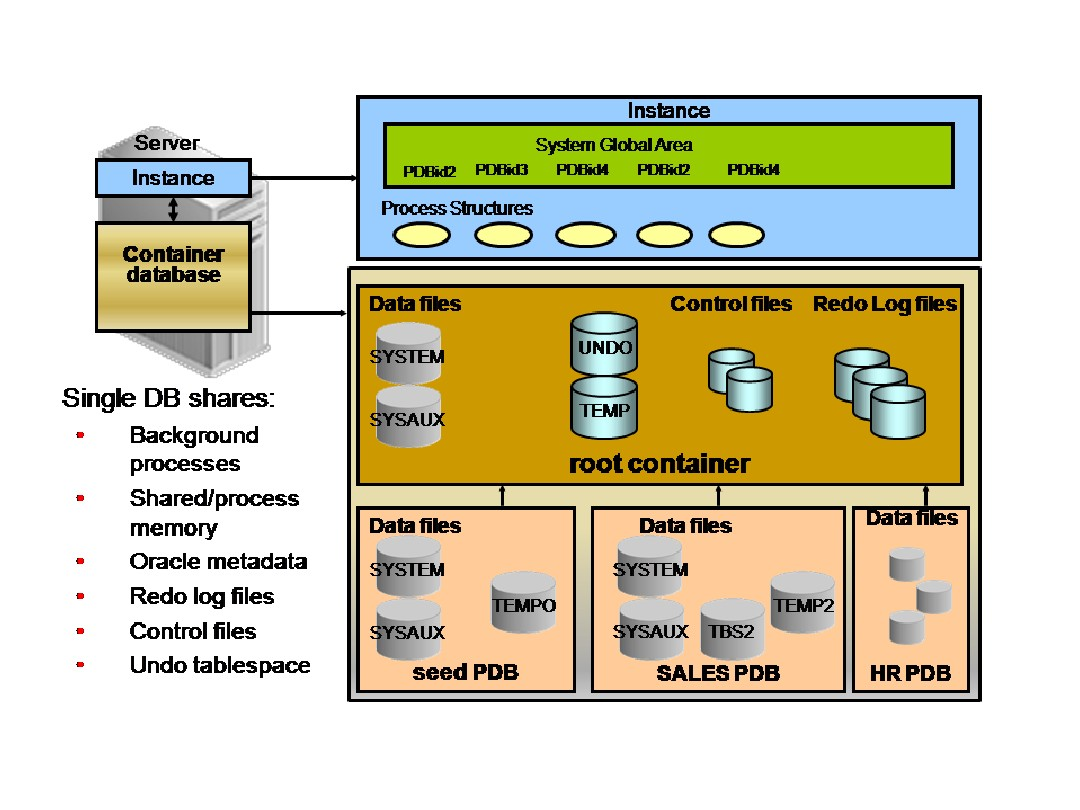
12C数据库体系结构-形象版
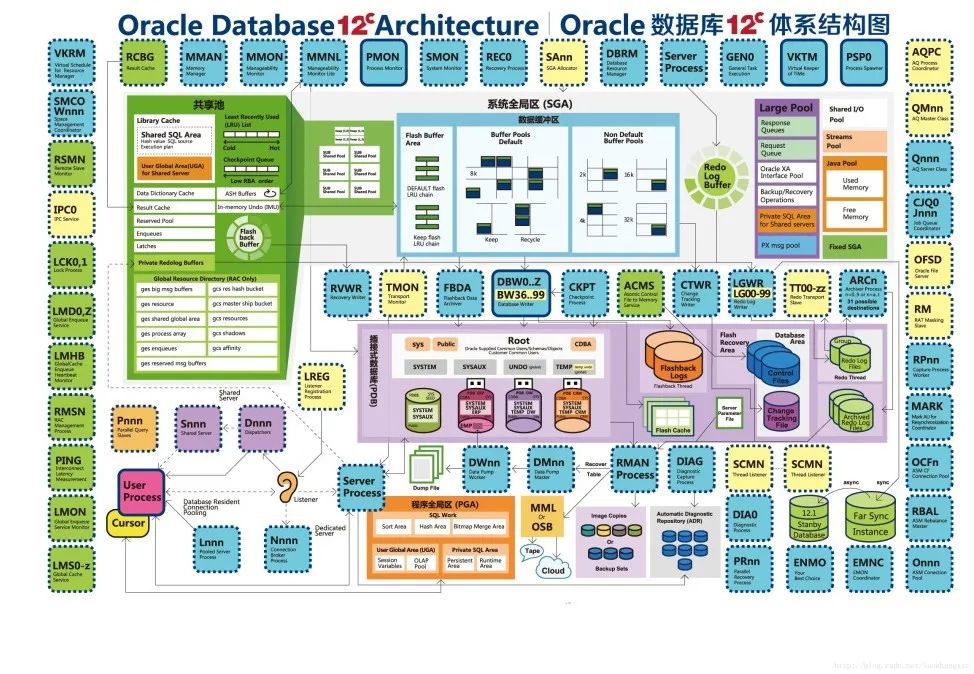
 12C数据库体系结构-完整版
12C数据库体系结构-完整版
Oracle内存结构是什么?
1、含系统全局区(SGA)和程序全局区(PGA),即Oracle Memory Structures = SGA + PGA。
2、SGA由服务器和后台进程共享。
3、PGA包含单个服务器进程或单个后台进程的数据和控制信息,与几个进程共享的SGA 正相反,PGA是只被一个进程使用的区域,PGA 在创建进程时分配在终止进程时回收。即由服务器进程产生。PGA = 排序区+游标状态区+会话信息区+堆栈区。
SGA 系统全局区SGA,SGA = 数据缓冲区+ 重做日志缓冲区+ 共享池+ 大池+ Java 池+ 流池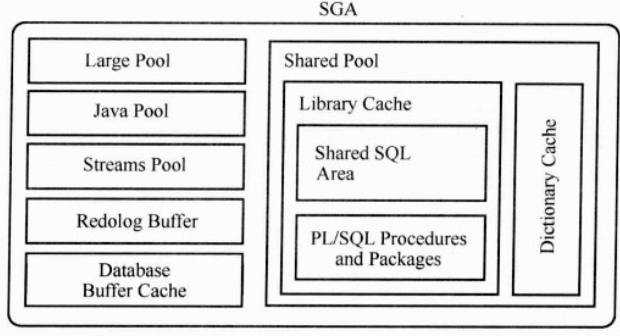
后台进程
DBWn(数据库写进程):
负责将修改过的数据块从数据库缓冲区高速缓存写入磁盘上的数据文件中。
写入条件:发生检查点、脏缓存达到限制、没有自由的缓存、超时发生、表空间离线、表空间只读、表被删除或者截断、开始备份表空间。
SMON(系统监控进程):
检查数据库的一致性,当启动失败时完成灾难恢复等。
PMON(程序监控进程):
清除失效的用户进程,释放用户进程所用的资源。
释放资源:清除失败的进程、回滚事务、释放锁、释放其他资源
CKPT(检查点进程):
DBWr/LGWr的工作原理,造成了数据文件,日志文件,控制文件的不一致,CKPT进程负责同步数据文件,日志文件和控制文件,CKPT会更新数据文件/控制文件的头信息。
条件:
在日志切换的时候;数据库用immediate ,transaction ,normal选项shutdown数据库的时候;根据初始话文件LOG_CHECKPOINT_INTERVAL、LOG_CHECKPOINT_TIMEOUT、FAST_START_IO_TARGET 的设置的数值来确定。用户触发。
LGWr(日志写进程):
将重做日志缓冲区中的更改写入在线重做日志文件。
条件:写满1/3;每隔3秒;DBWr需要写入的数据的SCN号大于LGWr记录的SCN号,DBWr触发LGWr写入SMON(系统监控进程)
在服务器上如何查找参数文件位置?
find / -name init.ora快速定位位置
查看全局环境变量cat /etc/profile
如果全局环境变量没有,则查看oracle用户的环境变量,切换到oracle用户,命令:su oraclecd ~cat .bash_profilesource.bash_profilecd $ORACLE_HOME/product/12.2.0/dbhome_1/dbs环境变量也没有的话,只能找万能的DBA了。一般不会出现这种情况!!!
spfileorcl.oraorcl.__db_cache_size=7482638336orcl.__java_pool_size=33554432orcl.__large_pool_size=67108864orcl.__oracle_base='/data/orc/app/oracle'#ORACLE_BASE set from environmentorcl.__pga_aggregate_target=3388997632orcl.__sga_target=10099884032orcl.__shared_io_pool_size=536870912orcl.__shared_pool_size=1946157056orcl.__streams_pool_size=0*.audit_file_dest='/data/orc/app/oracle/admin/orcl/adump'CC"]*.audit_trail='db'*.control_files='/data/orc/app/oracle/oradata/orcl/control01.ctl','/data/orc/app/oracle/fast_recovery_area/orcl/control02.ctl'*.db_block_size=8192*.db_name='orcl'*.db_recovery_file_dest='/data/orc/app/oracle/fast_recovery_area/orcl'*.db_recovery_file_dest_size=12780m*.diagnostic_dest='/data/orc/app/oracle'*.dispatchers='(PROTOCOL=TCP) (SERVICE=orclXDB)'*.enable_pluggable_database=true*.local_listener='LISTENER_ORCL'*.pga_aggregate_target=3201m*.processes=320*.remote_login_passwordfile='EXCLUSIVE'*.sga_target=9603m*.undo_tablespace='UNDOTBS1实例启动流程
用startup(默认)启动的顺序1、直接在默认路径下查找spfileSID.ora --(spfile)
2、直接在默认路径下查找spfile.ora
3、直接在默认路径下查找initSID.ora --(pfile)
顺序查找,有一个就可以,如果都没有找到,就会报错……
问题:加载参数文件就是启动数据库了么?
Oracle启动模式
1、Startup nomount (nomount模式)启动实例不加载数据库。
2、Startup mount (mount模式)启动实例加载数据库但不打开数据库。
3、Startup (open 模式)启动实例加载并打开数据库。
Startup
[oracle@localhost ~]$ sqlplus / as sysdba;bash: sqlplus: command not found[oracle@localhost ~]$ source .bash_profile[oracle@localhost ~]$ echo $ORACLE_SIDstandby[oracle@localhost ~]$ echo $ORACLE_HOME/u01/app/oracle/product/11.2.0.4[oracle@localhost ~]$ sqlplus / as sysdba;SQL*Plus: Release 11.2.0.4.0 Production on Wed May 27 09:21:12 2020Copyright (c) 1982, 2013, Oracle. All rights reserved.Connected to an idle instance.SQL> startup;ORACLE instance started.Total System Global Area 534462464 bytesFixed Size 2254952 bytesVariable Size 213911448 bytesDatabase Buffers 314572800 bytesRedo Buffers 3723264 bytesDatabase mounted.Database opened.SQL>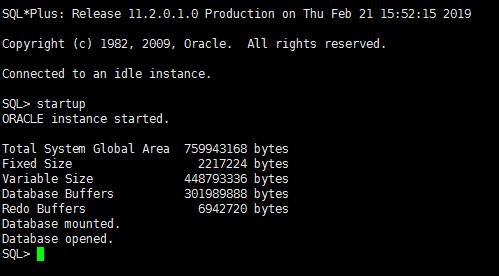
lsnrctl status;
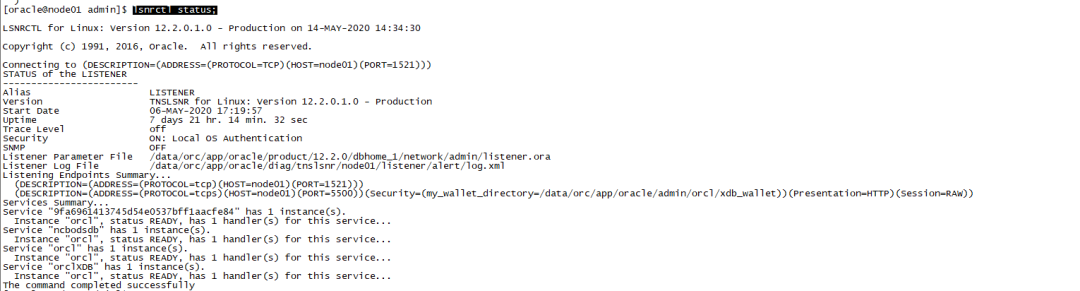
Service "9fa6961413745d54e0537bff1aacfe84" has 1 instance(s).Instance "orcl", status READY, has 1 handler(s) for this service...Service "ncbodsdb" has 1 instance(s).Instance "orcl", status READY, has 1 handler(s) for this service...Service "orcl" has 1 instance(s).Instance "orcl", status READY, has 1 handler(s) for this service...Service "orclXDB" has 1 instance(s).Instance "orcl", status READY, has 1 handler(s) for this service...The command completed successfullylistener.ora与tnsnames.ora
istener.ora文件内容示例:
#这是一个名为 LISTENER1 的监听器
#监听的协议是TCP协议
#监听的主机IP是127.0.0.1
#监听的端口是1521端口
LISTENER1 =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 127.0.0.1)(PORT = 1521))
)
#如下是监听配置,监听名为ORCL
#记录了监听器LISTENER1服务的全局数据库名、数据库路径和数据库实例名
SID_LIST_LISTENER1 =(SID_LIST =(SID_DESC =(GLOBAL_DBNAME = ORCL)(ORACLE_HOME = /data/orc/app/oracle/product/12.2.0/dbhome_1)(SID_NAME = ORCL)))listener.ora配置文件没有配置监听,但是有多个监听服务,为什么?
listener.ora文件配置的是静态的监听服务,数据库在启动的时候会跟随数据库一起启动,并且监听服务状态为
Service "orcl" has 1 instance(s).
Instance "orcl", status UNKNOWN, has 1 handler(s) for this service...
数据库启动的过程中,会启动监服务
Service "orcl" has 1 instance(s).
Instance "orcl", status READY, has 1 handler(s) for this service...
验证命令:
show parameter service_names;
结果:
NAME TYPE VALUE
----------------------------------- ----------- ------------------------------
service_names string orcl
Service “ncbodsdb” has 1 instance(s). 中的ncbodsdb监听哪里配置的?
切换实例
show pdbs
alter session set container= NCBODSDB;
启动PDB数据库
alter pluggable database NCBODSDB open; 将PDBORCL打开(自己起的PDB数据库的名字) 查看监听
开启PDB数据库的时候,会启动监听服务
验证命令:
select name, pdb from v$services;
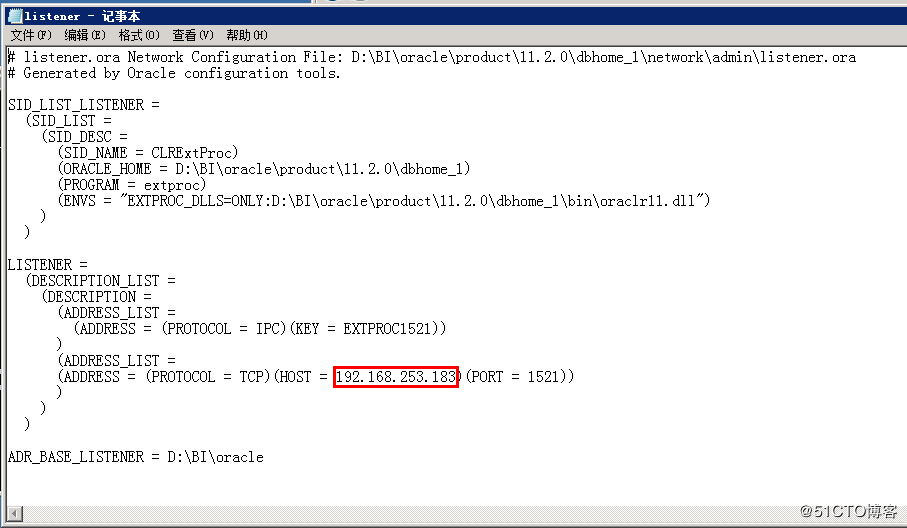
tnsnames.ora文件内容示例:
#ORCL是个别名
#这条信息记录了我们使用TCP协议,去连接IP地址为127.0.0.1,端口号为1521的数据库主机上服务名为orcl的数据库
LISTENER_ORCL =(ADDRESS = (PROTOCOL = TCP)(HOST = node01)(PORT = 1521))ORCL =(DESCRIPTION =(ADDRESS = (PROTOCOL = TCP)(HOST = node01)(PORT = 1521))(CONNECT_DATA =(SERVER = DEDICATED)(SERVICE_NAME = orcl)))ncbodsdb =(DESCRIPTION =(ADDRESS = (PROTOCOL = TCP)(HOST = node01)(PORT = 1521))(CONNECT_DATA =(SERVER = DEDICATED)(SERVICE_NAME = ncbodsdb)))
主键
指的是一个列或多列的组合,其值能唯一地标识表中的每一行,通过它可强制表的实体完整性。
用途
1. 惟一地标识一行。
2. 作为一个可以被外键有效引用的对象。
原则
1. 主键应当是对用户没有意义的。
2. 主键应该是单列的,以便提高连接和筛选操作的效率。
3. 永远也不要更新主键。
4. 主键不应包含动态变化的数据,如时间戳、创建时间列、修改时间列等。
5. 主键应当有计算机自动生成。
索引
索引是为了加速对表中数据行的检索而创建的一种分散的存储结构。
分类
普通索引
唯一索引(请自行区别唯一索引与唯一约束)
主键索引
位图索引
用途
快速取数据
索引与表的关系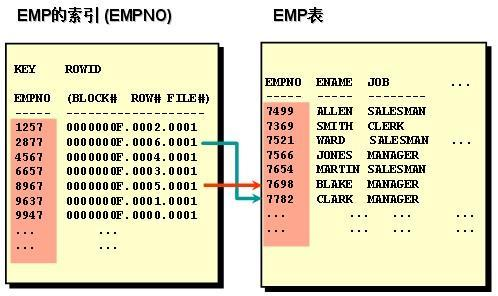 普通索引
普通索引
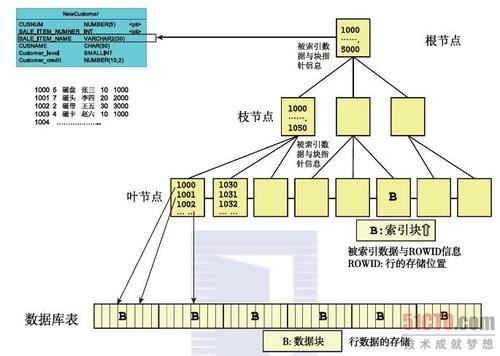 位图索引
位图索引
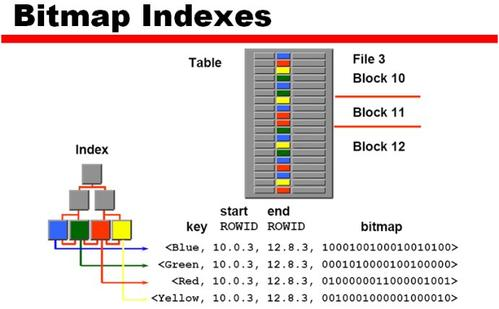 删除索引
删除索引
操作索引
创建索引
CREATE[UNIQUE][CLUSTERED| NONCLUSTERED] INDEX ON ([ASC|DESC] [, [ASC|DESC]...])
1、UNIQUE——建立唯一索引。
2、CLUSTERED——建立聚集索引。
3、NONCLUSTERED——建立非聚集索引。
4、ASC——索引升序排序。
5、DESC——索引降序排序。
更新索引
DROP INDEX
语句执行慢的原因及解决思路分类:
1、热点块(写写、写读)
2、有索引(写)
3、全表扫描(读)
4、回表查询(读)
http://blog.itpub.net/8410760/viewspace-732117/
5、行连接、行迁移(读、写)
https://www.cnblogs.com/Richardzhu/p/3449243.html
思考:热点块与行连接/迁移解决思路有冲突,为什么?
索引
SQL执行过程:执行sql开启事务插入/删除数据->更新索引->提交事务->返回结果延伸:是不是只要建表就需要建主键索引?热点块
查看热点块
1、写写热点块,包括create\update\delete
2、当一个会话需要访问一个数据块,而这个数据块正在被另一个用户从磁盘读取到内存中或者这个数据块正在被另一个会话修改时,当前的会话就需要等待,就会产生一个buffer busy waits等待,也伴随着Latch争用。
3、 latch是数据库内部提供的一种维护内部结构的一种低级锁,latch的生存周期极短(微秒以下 级别),进程加latch后快速的进行某个访问或者修改动作然后释放latch。
select latch#,name,gets,misses,sleeps from v$latch where name like 'cache buffer%’;
LATCH# NAME GETS MISSES SLEEPS---------- ------------------------------ ---------- ---------- ----------93 cache buffers lru chain 54360446 21025 23898 cache buffers chains 6760354603 1680007 2708599 cache buffer handles 554532 6 0
在这个查询结果里我们可以看到记录了数据库启动以来的所有cahce buffer chains的latch的状况,gets表示总共有这么多次请求,misses表示请求失败的次数(加锁不成功),而sleeps 表示请求失败休眠的次数,通过sleeps我们可以大体知道数据库中latch的竞争是否严重,这也间接的表征了热点块的问题是否严重。由于 v$latch是一个聚合信息,我们并不能获得哪些块可能存在频繁访问。那我们要来看另一个view信息,那就是 v$latch_children,v$latch_children.addr记录的就是这个latch的地址
热点解决思路:
最有效的办法,是从优化sql入手,不良的 sql往往带来大量的不必要的访问,这是造成热点块的根源。
比如本该通过全表扫描的查询却走了索引的range scan,这样将带来大量的对块的重复访问。从而形成热点问题。再或者比如不当地走了nested loops的表连接,也可能对非驱动表造成大量的重复访问。
查看执行计划
一条查询语句在ORACLE中的执行过程或访问路径的描述。执行计划的查看
1、设置autotrace
autotrace命令如下
2、执行计划
SQL> Set autotrace traceonly;SQL> select table_id from ncb_ods.BRAIN_COLUMN t where table_id = 25;218 rows selected.Execution Plan----------------------------------------------------------Plan hash value: 3956012344----------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |----------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 218 | 654 | 5 (0)| 00:00:01 ||* 1 | TABLE ACCESS FULL| BRAIN_COLUMN | 218 | 654 | 5 (0)| 00:00:01 |----------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1 - filter(TO_NUMBER("TABLE_ID")=25)Statistics----------------------------------------------------------0 recursive calls0 db block gets31 consistent gets0 physical reads0 redo size4350 bytes sent via SQL*Net to client762 bytes received via SQL*Net from client16 SQL*Net roundtrips to/from client0 sorts (memory)0 sorts (disk)218 rows processed如何读懂执行计划。
1、执行顺序的原则
执行顺序的原则是:由上至下,从右向左 由上至下:在执行计划中一般含有多个节点,相同级别(或并列)的节点,靠上的优先执行,靠下的后执行 从右向左:在某个节点下还存在多个子节点,先从最靠右的子节点开始执行。
2、执行计划中字段解释
ID: 一个序号,但不是执行的先后顺序。执行的先后根据缩进来判断。
Operation:当前操作的内容。
Rows:当前操作的Cardinality,Oracle估计当前操作的返回结果集。
Cost(CPU):Oracle 计算出来的一个数值(代价),用于说明SQL执行的代价。
Time:Oracle 估计当前操作的时间
3、Statistics(统计信息)说明
表连接类型INNER JOIN(内连接)
Nature join(自然连接)
Cross join(交叉连接)
OUTER JOIN(外连接)
LEFT OUTER JOIN(可简写为 LEFT JOIN,左外连接)
RIGHT OUTER JOIN( RIGHT JOIN,右外连接)
FULL OUTER JOIN( FULL JOIN,全外连接)
SORT MERGE JOIN(排序-合并连接)
特点
排序-合并连接的表无驱动顺序,谁在前面都可以;
排序-合并连接适用的连接条件有: = ,不适用的连接条件有:like
NESTED LOOPS(嵌套循环)
特点:时间换空间(内存空间)
HASH JOIN(哈希连接)
特点:哈希连接只适用于等值连接(即连接条件为 = )
哈希连接的三种模式:
OPTIMAL HASH JOIN
ONEPASS HASH JOIN
MULTIPASS HASH JOIN
CARTESIAN PRODUCT(笛卡尔积)
表访问1.TABLE ACCESS FULL(全表扫描):
查询出该表所有数据,获取的数据执行where语句。
2. TABLE ACCESS BY INDEX ROWID BATCHED (通过ROWID的表存取):
通过ROWID获取表数据,回表查询
TABLE ACCESS BY INDEX ROWID BATCHED ,ROWID BATCHE是12C新特性
TABLE ACCESS BY INDEX ROWID ,11G
3.TABLE ACCESS BY INDEX SCAN(索引扫描)。
1.INDEX UNIQUE SCAN(索引唯一扫描)
2.INDEX RANGE SCAN(索引范围扫描)
3.INDEX FULL SCAN(索引全扫描)
4.INDEX FAST FULL SCAN(索引快速扫描)
5.INDEX SKIP SCAN(索引跳跃扫描)
延伸
1.索引数据结构:B+树;其他数据结构:B树、红黑树
2.java的list与数组,为什么数组遍历的快?
3.Redis、Hbase、mysql都会有热点块么?
4.为什么Redis读取快?只是因为数据在内存么?
作者:姚岺坤,一位永远走在学习的道路上的程序员
编辑:徐菲

据说中国有句古语叫「金无足赤,人无完人」,但是,如果谁真的想打起灯笼来到市面上寻找完人,最终令他感到的可能不是一种失望,而是一种意外:完人可能就是那些终日为「善」而奔走,而又在不知不觉中实现了「美」的「真」实不虚的普通人。
追求完美是正常而有缺憾的人性。
--尼采
















 352
352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









