





打算跟大家把Pandas相关的知识点跟大家汇总一起来讲一下,本期的Python基础教程一起来学习吧!
一.索引对象支持集合运算:联合、交叉、求差、对称差Demo1:
import pandas as pd import numpy as np college = pd.read_csv('data/college.csv')columns = college.columnsc1 = columns[:4]c2 = columns[2:5]print(c1.union(c2))print(c1 | c2)
Demo2:
import pandas as pd import numpy as np college = pd.read_csv('data/college.csv')columns = college.columnsc1 = columns[:4]c2 = columns[2:5]print("c1 : ",c1)print("c2 : ",c2)print(c1.symmetric_difference(c2))print(c1 ^ c2)
二.用copy()产生新的数据A is B:表明二者指向的同一个对象。这意味着,如果修改一个,另一个也会去改变。Demo1:
import pandas as pd import numpy as np employee = pd.read_csv('data/employee.csv', index_col='RACE')salary1 = employee['BASE_SALARY']salary2 = employee['BASE_SALARY']print(salary1 is salary2)salary1 = employee['BASE_SALARY'].copy()salary2 = employee['BASE_SALARY'].copy()print(salary1 is salary2)三.不等索引(索引的difference方法)Demo1:
用difference,找到哪些索引标签在baseball_14中,却不在baseball_15、baseball_16中
import pandas as pd import numpy as np baseball_14 = pd.read_csv('data/baseball14.csv', index_col='playerID') baseball_15 = pd.read_csv('data/baseball15.csv', index_col='playerID') baseball_16 = pd.read_csv('data/baseball16.csv', index_col='playerID')print(baseball_14.index.difference(baseball_15.index))print(baseball_14.index.difference(baseball_16.index))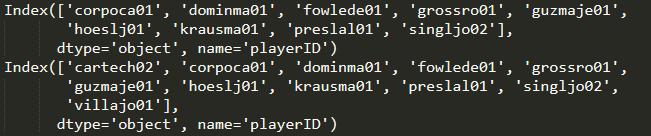
四.使用fill_value避免在算术运算时产生缺失值Demo1:
import pandas as pd import numpy as np baseball_14 = pd.read_csv('data/baseball14.csv', index_col='playerID') baseball_15 = pd.read_csv('data/baseball15.csv', index_col='playerID') #H列:每名球员的击球数hits_14 = baseball_14['H']hits_15 = baseball_15['H']print(hits_14.head())print(hits_15.head())print(hits_14.head() + hits_15.head())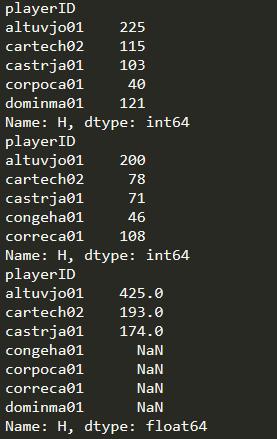
下面四条数据是有记录的,但是因为不同时存在14,15两张表中,所以相加会产生NaN,需要用fill_value
Demo2:
import pandas as pd import numpy as np baseball_14 = pd.read_csv('data/baseball14.csv', index_col='playerID') baseball_15 = pd.read_csv('data/baseball15.csv', index_col='playerID') baseball_16 = pd.read_csv('data/baseball16.csv', index_col='playerID')#H列:每名球员的击球数hits_14 = baseball_14['H']hits_15 = baseball_15['H']hits_16 = baseball_16['H']print(hits_14.head().add(hits_15.head(),fill_value=0))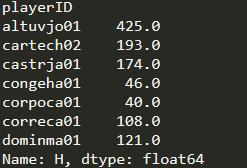
*如果一个元素在两个Series都是缺失值,即便使用了fill_value,相加的结果也仍是缺失值
五.从不同的DataFrame追加列
Demo:
import pandas as pd import numpy as np employee = pd.read_csv('data/employee.csv')d1 = employee[['DEPARTMENT', 'BASE_SALARY']]print("排序前:")print(d1.head())# 在每个部门内,对BASE_SALARY进行排序d2 = d1.sort_values(['DEPARTMENT', 'BASE_SALARY'],ascending = [True,False])print("排序后:")print(d2.head())#用drop_duplicates方法保留每个部门的第一行d3 = d2.drop_duplicates(subset = 'DEPARTMENT')print('去重后:')print(d3.head())#使用DEPARTMENT作为行索引d3 = d3.set_index('DEPARTMENT')employee = employee.set_index('DEPARTMENT')#向employee的DataFrame新增一列#新增时,对应缺项的为缺失值#存储每个Department的最高工资employee['MAX_SALARY'] = d3['BASE_SALARY']pd.options.display.max_columns = 3print('合并后:')print(employee.head())#用query查看是否有BASE_SALARY大于MAX_DEPT_SALARY的#输出应该为0print('query结果:')print(employee.query('BASE_SALARY > MAX_SALARY'))employee[‘MAX_SALARY’] = d3[‘BASE_SALARY’]这行语句能执行成功的条件是:d3中不含有重复索引,即执行过drop_duplicates
运行结果:
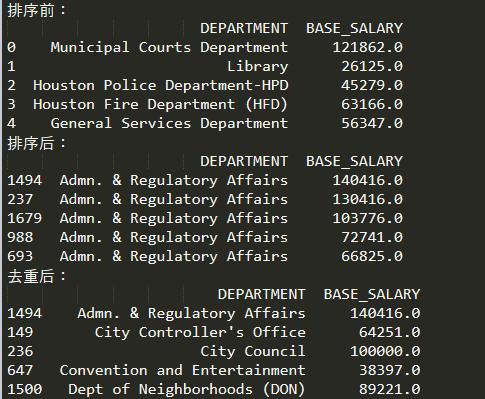
不知道伙伴们都看懂了么,不清楚的地方可以留言,下期的Python基础教程,我们接着讲!















 823
823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









