







原标题:单人或多人的人体姿态骨架估计算法概述
如何在大片中实现人物的特效,最终应用人体姿态估计。本博客介绍了使用深度学习技术及其应用的多人姿势估计方法。
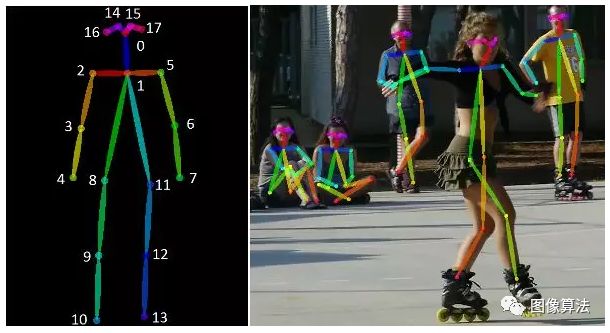
人体骨骼骨架以图形格式表达人体运动。基本上,它是一组坐标,用于描述一个人的姿势。骨架中的每个坐标称为此图的零件(或关节,关键点)。我们将两个组件之间的有效连接称为一对(对或肢)。但是,应该注意,并非所有组件组合都产生有效对。下图是人体骨架图的示例。
左图:人体骨骼骨架的COCO关键点格式; 右图:渲染后的人体姿势图
该图来源:https://github.com/CMU-Perceptual-Computing-Lab/openpose
获取人体姿势信息为多个真实世界的应用程序开辟了道路,其中一些应用程序将在本博客的最后讨论。近年来,研究人员提出了各种人体姿势估计方法,最早(也是最慢)的方法通常是在一个人的图像中估计一个人的姿势。这些方法通常识别各个组件,然后通过在它们之间形成连接来创建姿势。
当然,如果您处于多人的真实场景中,这些方法并不是非常有用。
多人姿势估计
由于图像中的人的位置和总人数未知,因此多人姿势估计比单人姿势估计更困难。一般来说,我们可以通过以下方法解决上述问题:
简单的方法是首先添加人体检测器,然后分别估计每个组件,最后计算每个人的姿势。这种方法称为“自上而下”的方法。
另一种方法是检测图像中的所有组件(即所有者的组件),然后关联/分组属于不同人的组件。这种方法称为“自下而上”的方法。

上部:传统的自上而下方法; 下部:传统的自下而上的方法。
通常,自上而下的方法比自下而上的方法更容易实现ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 808
808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









