






每一位好的设计师都收藏了很多国内国外素材网站,或提高工作效率,或提高审美。审美和色感是一个设计师所必须具备的职业素质,今天给大家分享几个免费商用设计网站。
1、 Pixabay
网址:http://www.bigbigwork.com/
Pixabay为每一位作者都提供了个人主页,使用者可以关注、点赞以及给作者打钱买咖啡。除了视频,Pixabay也提供数量众多的矢量图、插画、照片等无版权素材,均可免注册直接下载。
2、Videezy
网址:https://www.videezy.com/
3、pugimg
网址:http://pngimg.com/
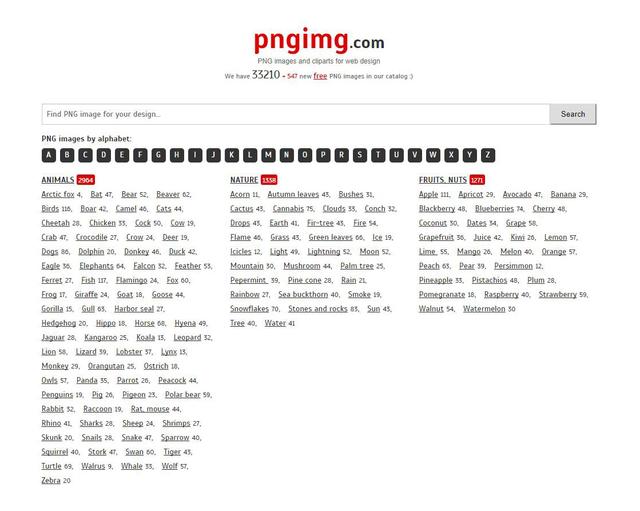
这是一个免费提供各种透明底PNG图片下载网站,网站首页有着大量的图片类型分类。
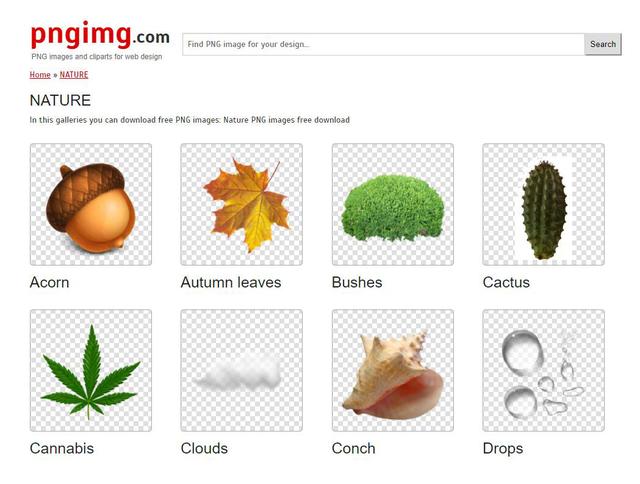
点开分类的大标签后,能够看到细分的各种类别。
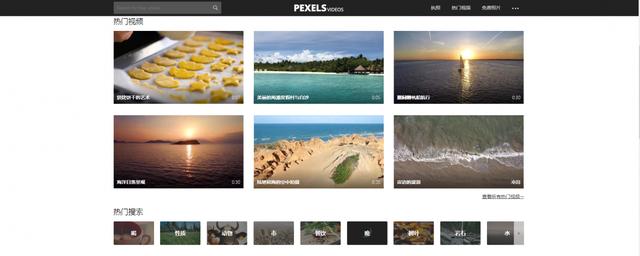
4、pexels
网址:https://videos.pexels.com/
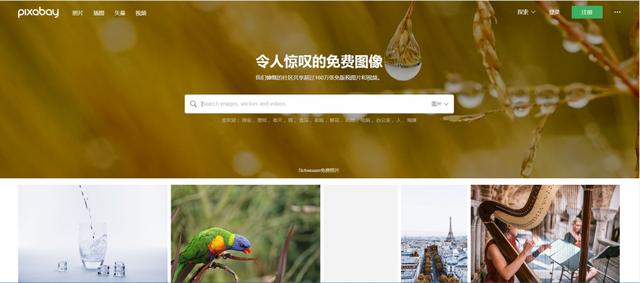
5、pixabay
网址:https://pixabay.com/
如果你觉得本文对你有帮助,就请关注我吧!欢迎点赞转发~














 4914
4914











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









