





对于网页数据的爬取,常用的软件有火车采集器与八爪鱼采集器,本文呢我们就以火车采集器(文末有安装包分享)分享链家网二手房的房源信息爬取。爬取过程可以大致分为两个部分:(一)寻找网页规则;(二)设置爬取规则;(1)采集网址规则;(2)采集内容规则;(3)发布内容设置。第一个部分是相对比较难的部分,那么话不多说,我们就直接开始吧...
第一部分 寻找网页规则
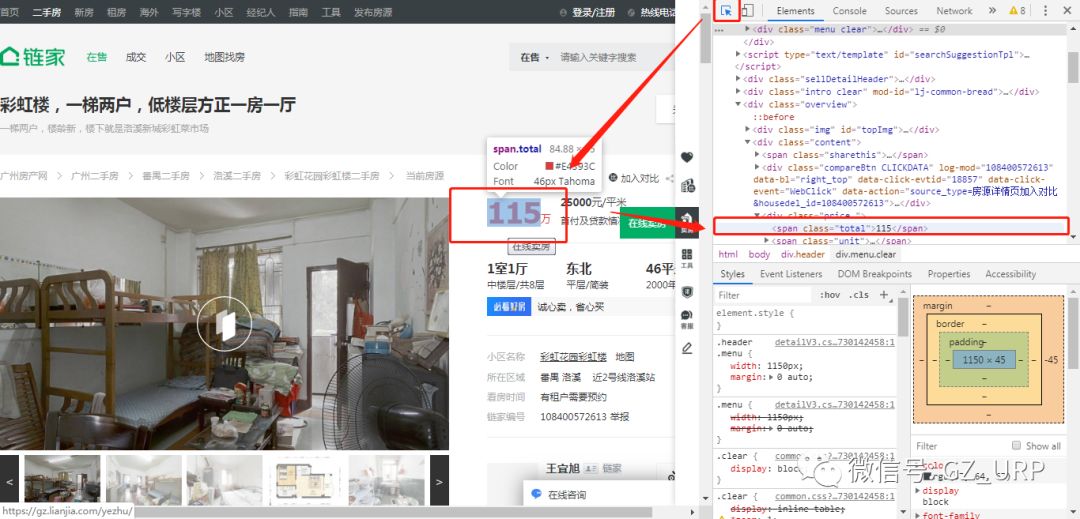 复制到网页源代码搜索,可以看到这个标签是唯一的(右上角1/1):
复制到网页源代码搜索,可以看到这个标签是唯一的(右上角1/1):
拓展阅读: 【胡说八道01】地理如何影响人类历史并决定当今世界? 【地理信息01】ArcMap中CAD数据 / 坐标数据(表格数据)的加载 【地理信息02】最最最纠结的基础知识——坐标系的认识与转换 【地理信息03】基于LSV地图+手机GPS定位的现状调研数据库构建 【地理信息04】选址基础分析——以简单数据为例分析租房选址 【地理信息05】城市土地变更以及规划实施评价 【地理信息06】基于GIS平台的城市多网点设施布局评估
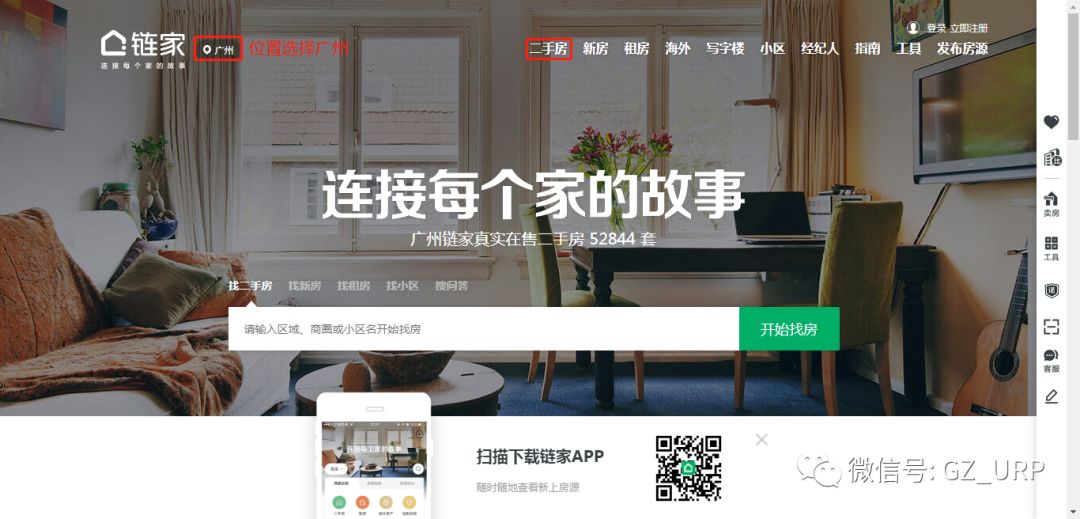
我们先打开链家网的网址:https://gz.lianjia.com/
地点选择广州(为例),点击上方【二手房】进入初级页面。
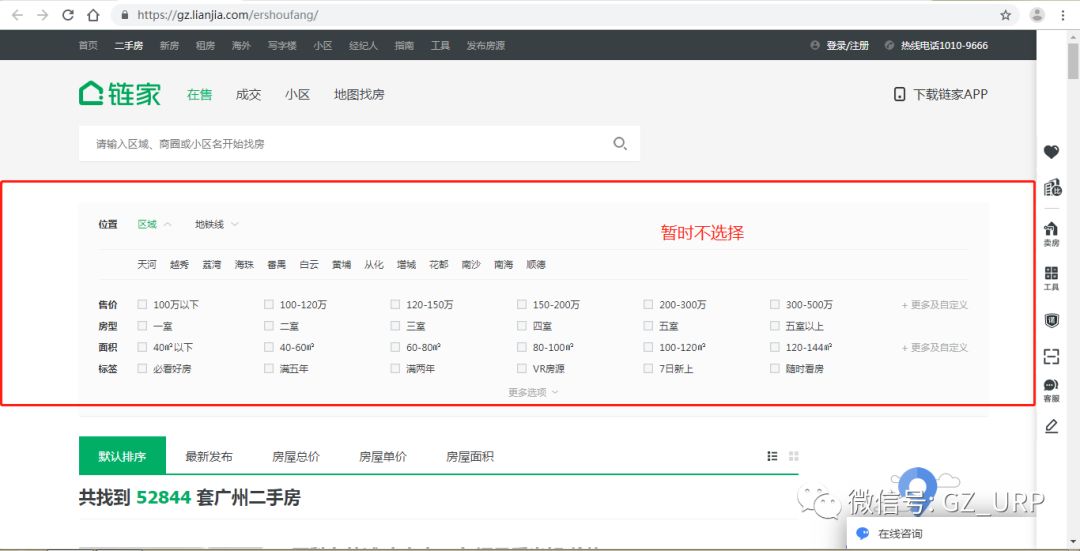
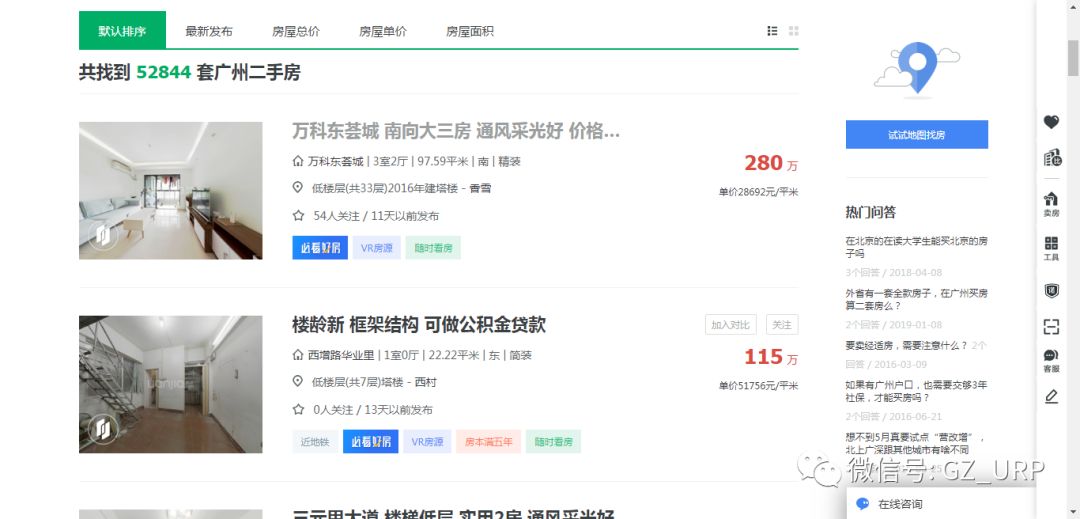
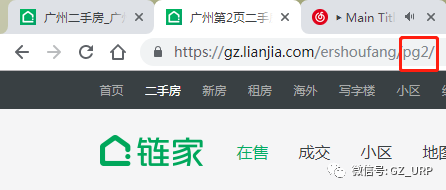
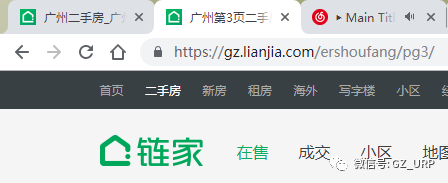
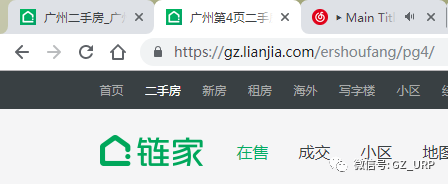
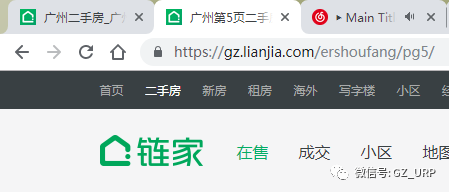
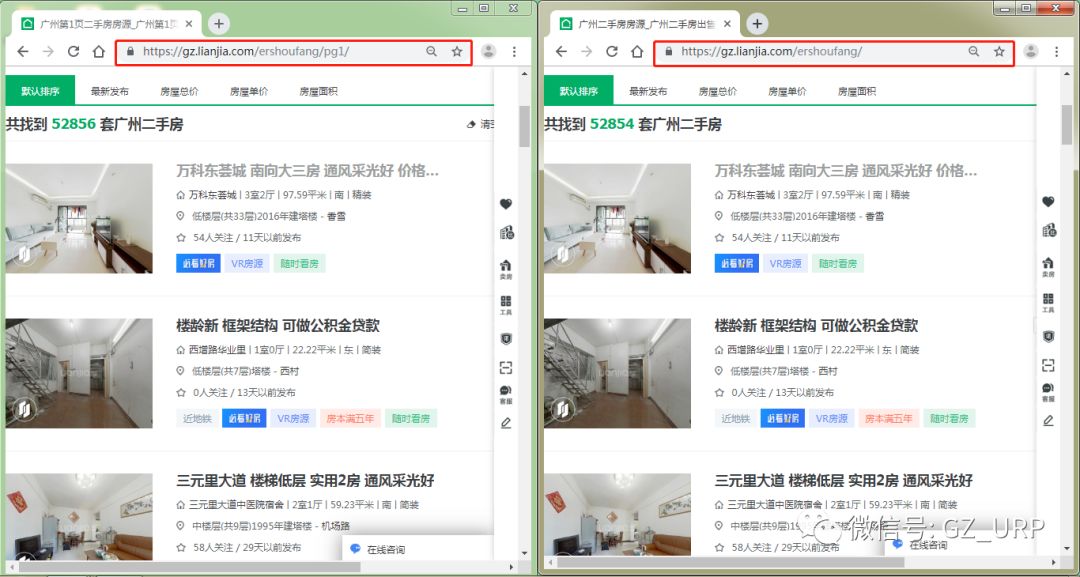
我们会发现每一页的网址其实有规律可循:
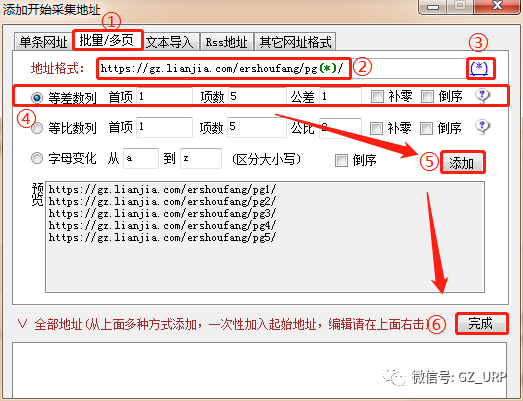
第2页:https://gz.lianjia.com/ershoufang/pg2/
第3页:https://gz.lianjia.com/ershoufang/pg3/
第4页:https://gz.lianjia.com/ershoufang/pg4/
第5页:https://gz.lianjia.com/ershoufang/pg5/
...
可是,我们又发现第1页的网址并不符合这样的规律,第1页的网址是https://gz.lianjia.com/ershoufang/。 按理来说,它应该是这样的:https://gz.lianjia.com/ershoufang/pg1/
我们要做的第二步,就是寻找房源规则:
我们先任意点开同一页的三个房源信息:
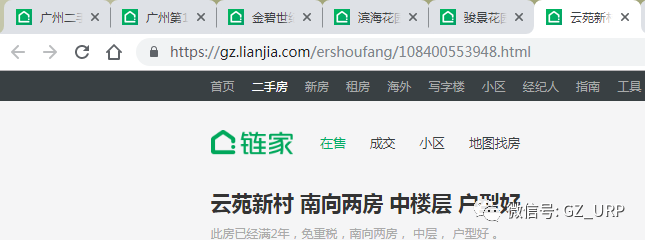
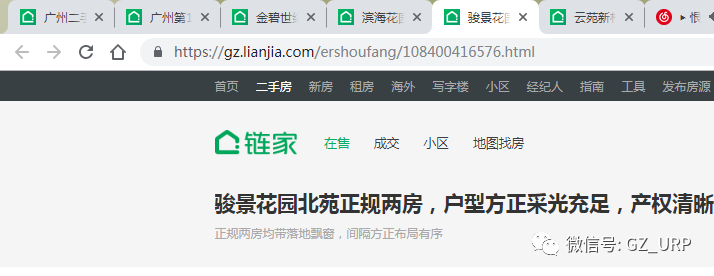
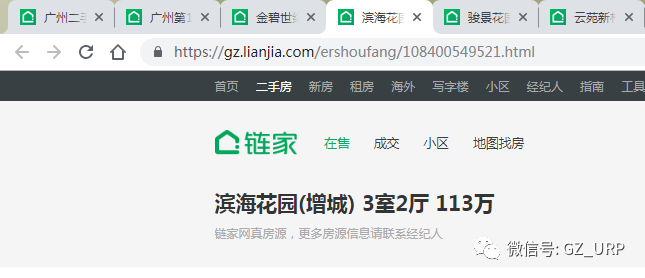
我们会发现它们的网址也有规律可循,就是后面这个数字不一样:
https://gz.lianjia.com/ershoufang/108400553948.html
https://gz.lianjia.com/ershoufang/108400416576.html
https://gz.lianjia.com/ershoufang/108400549521.html
那么我们就把这个房源规则找出来了。
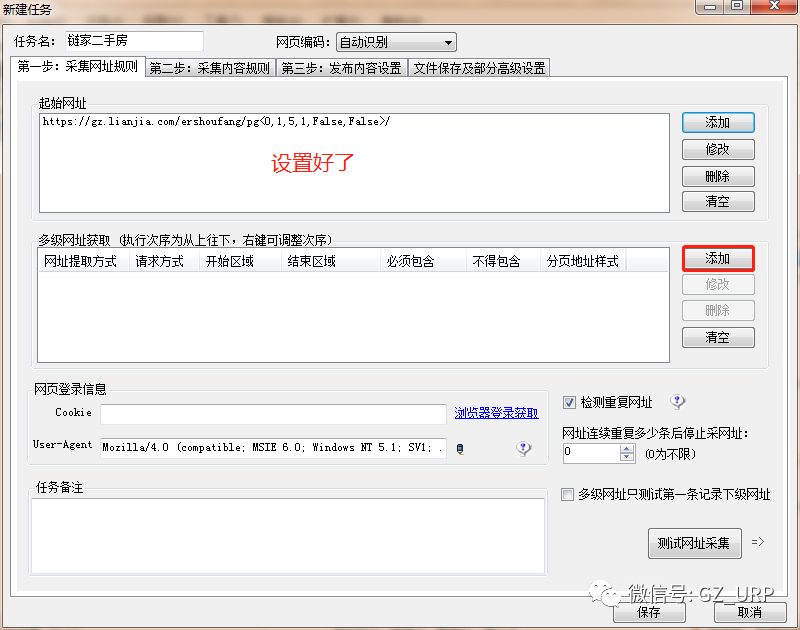
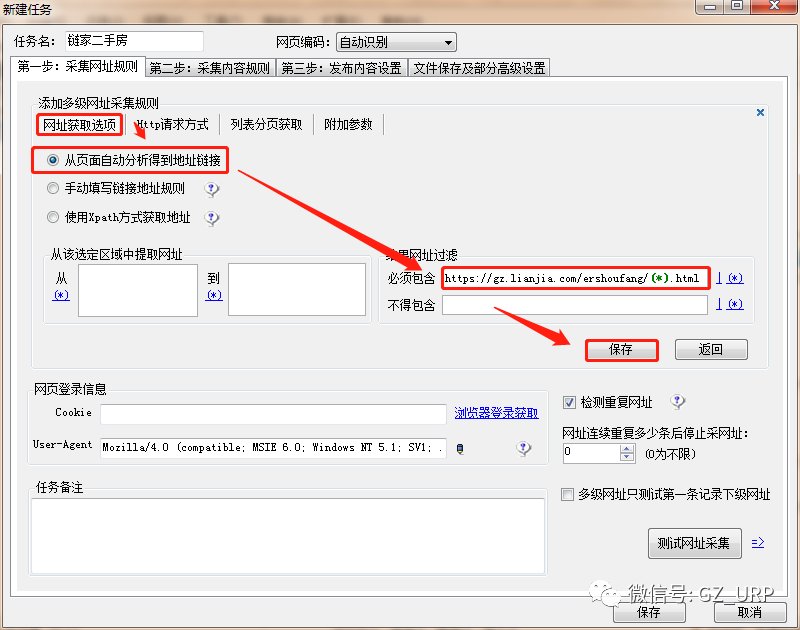
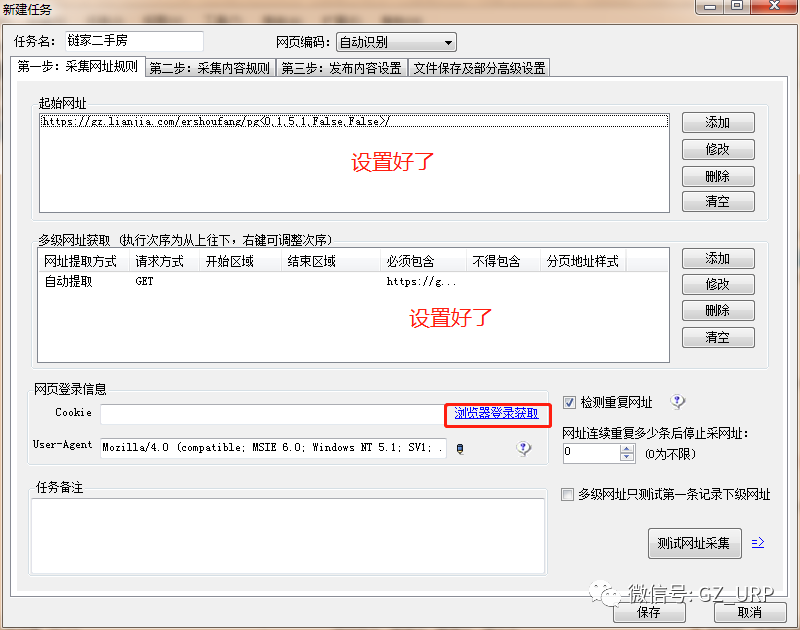
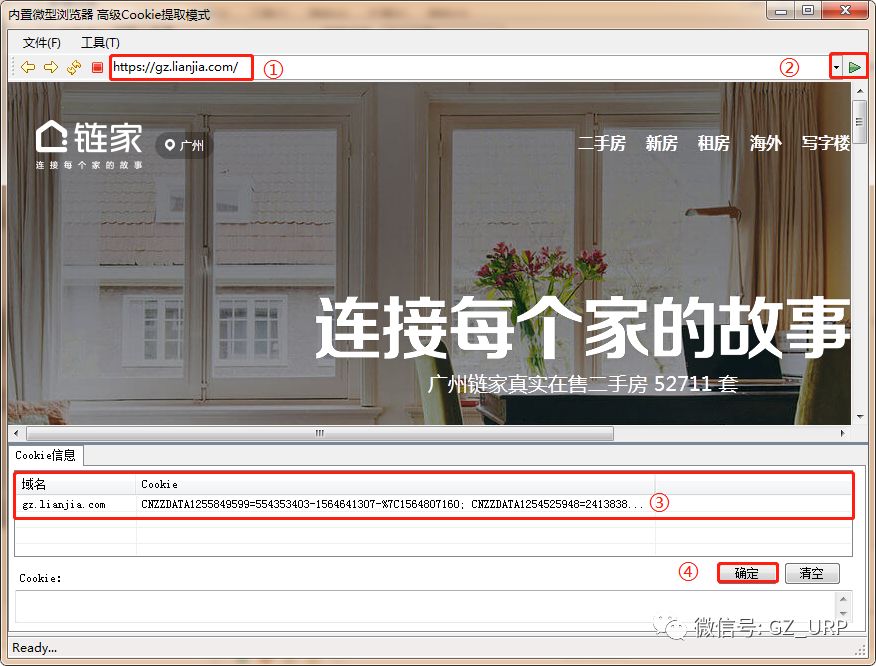
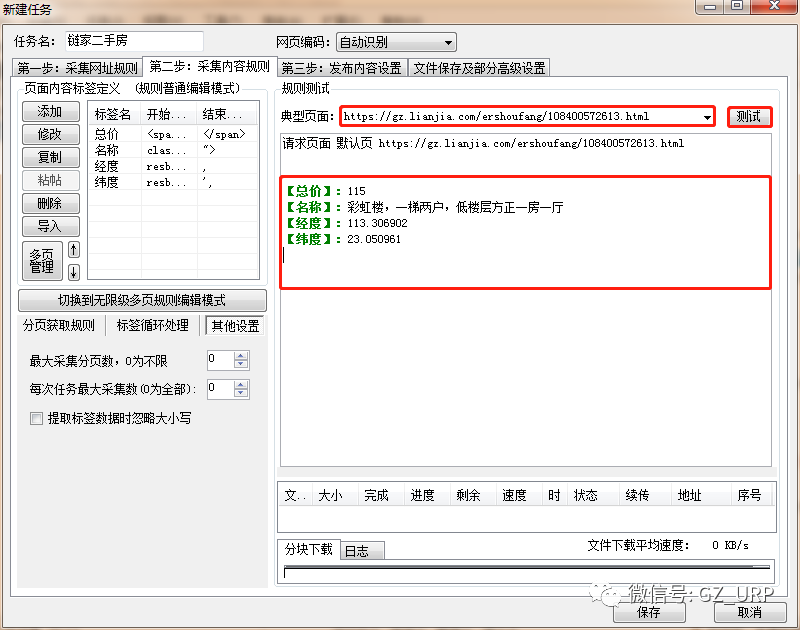
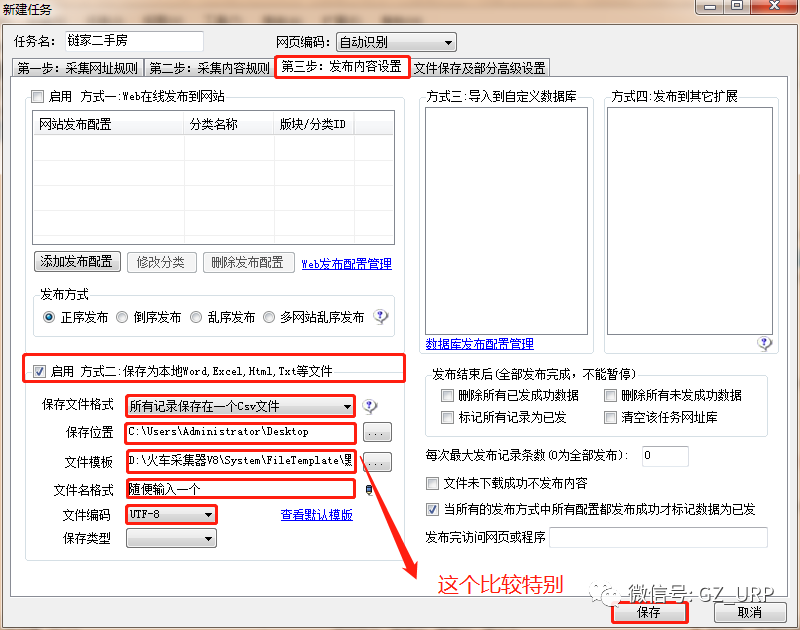
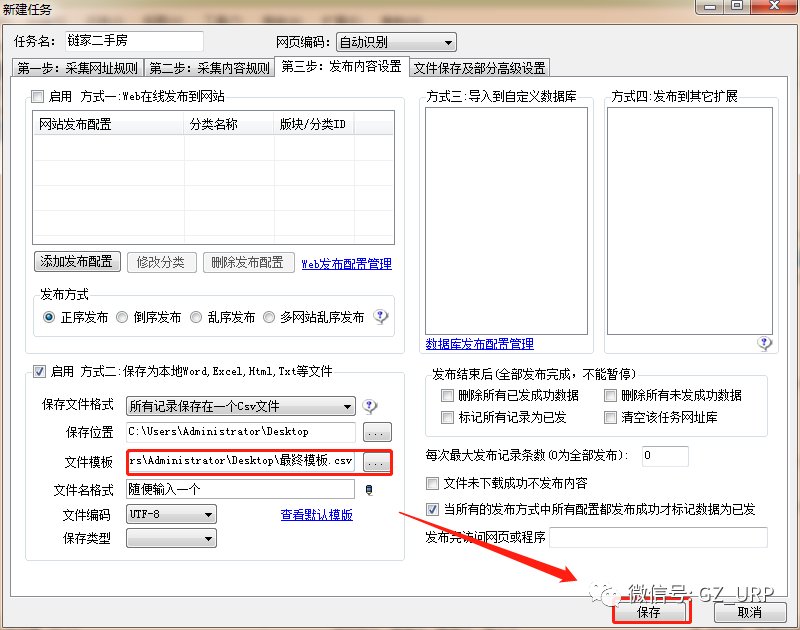
按照以上的规则,我们首先可以获取到链家网二手房每一页的网址,然后可以获取每一页网址上每个房源信息的网址,有了每个房源信息的网址,我们就可以爬取有关房源的相关信息了,这就是网页信息爬取的逻辑。 第二部分 设置爬取规则 第①步:采集网址规则 我们首先第一步打开火车采集器8.5版本,初试界面就是这样:
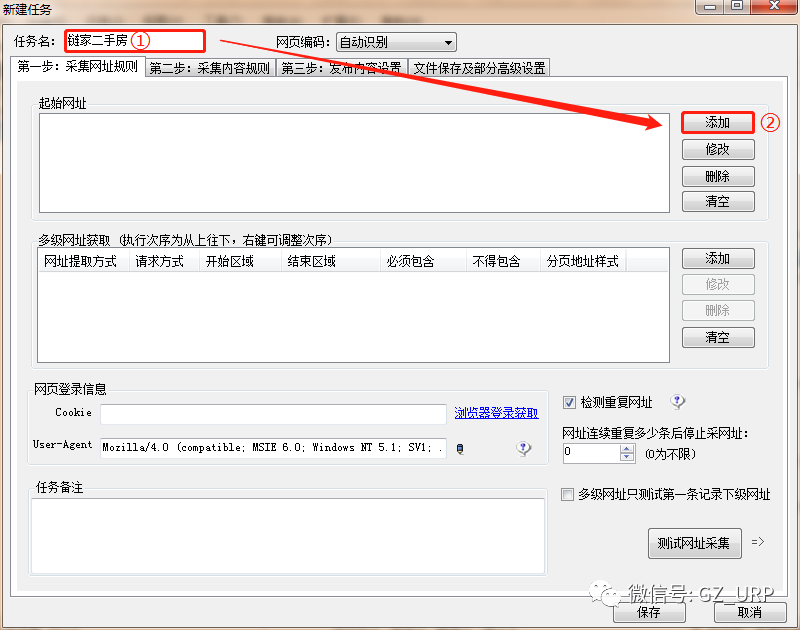

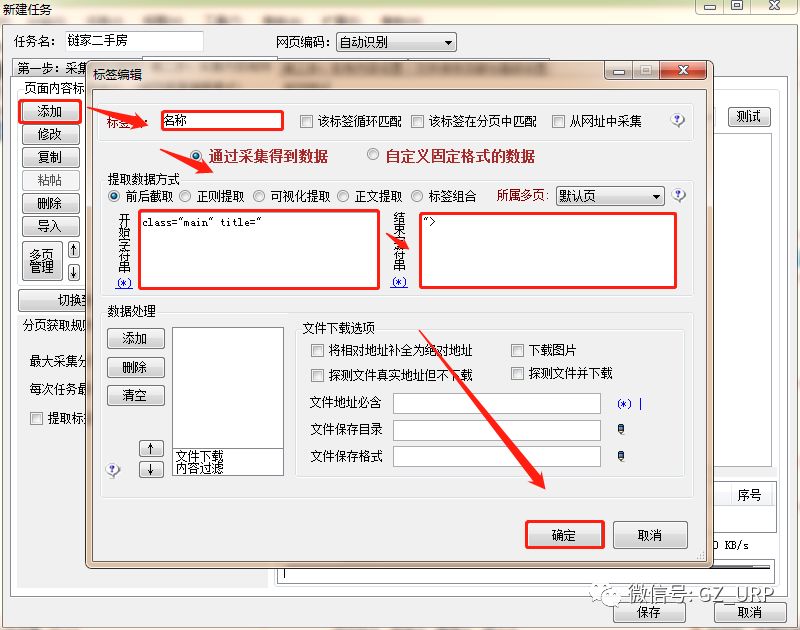
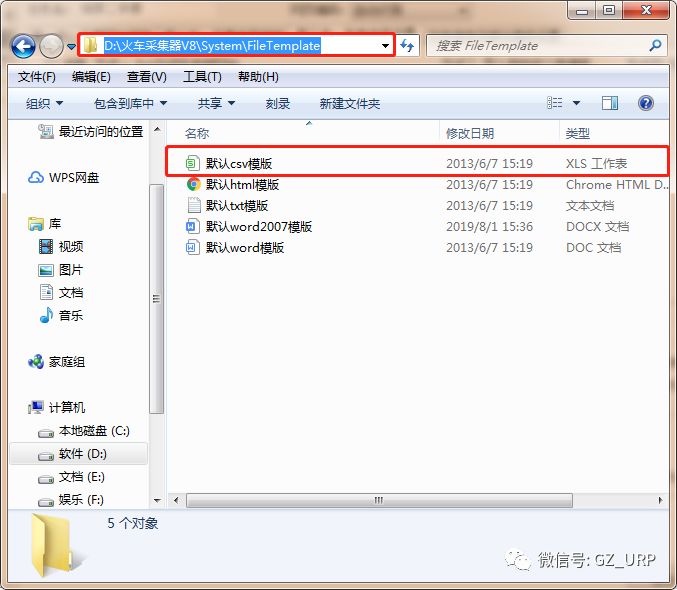
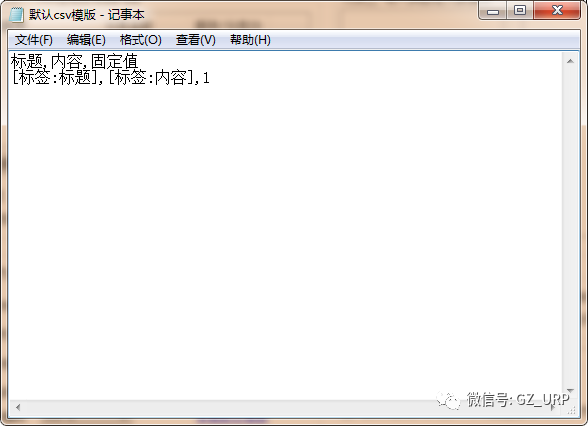
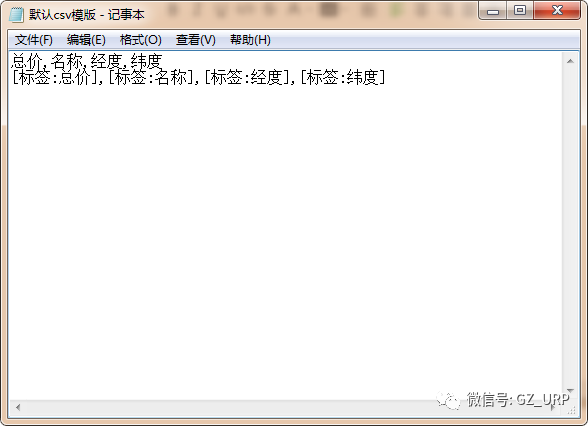
首先我们删除这些软件自带的默认标签(标题、内容、作者、时间、出处)
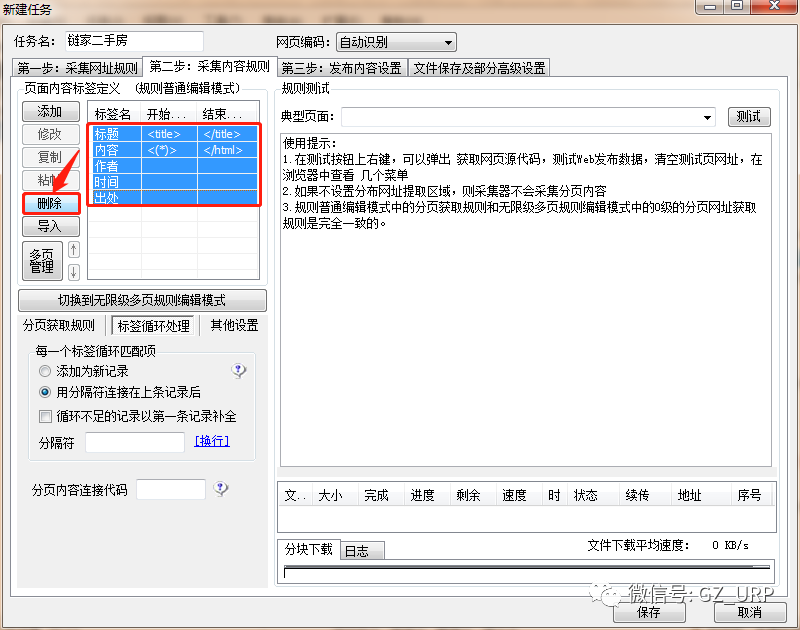
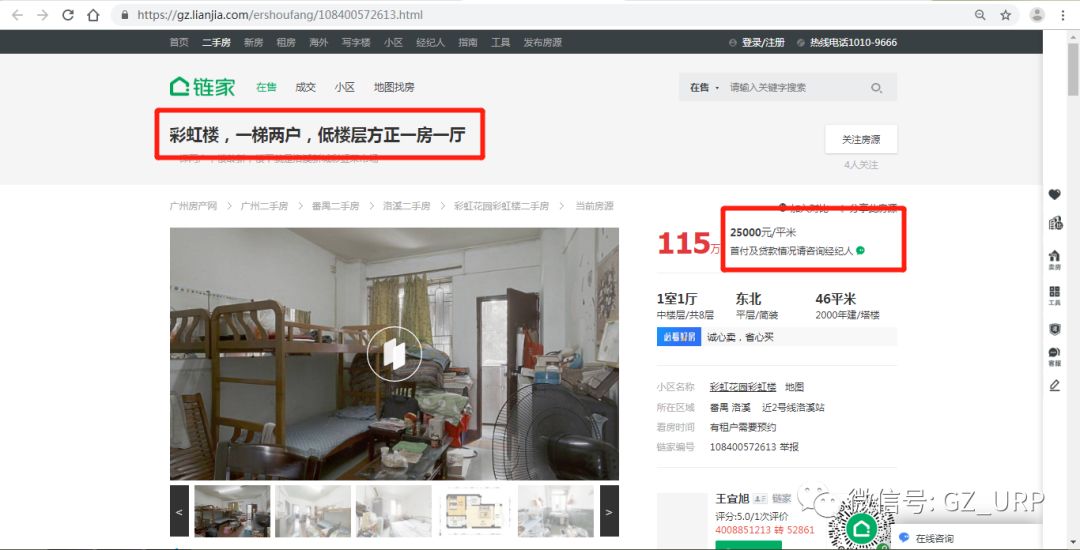

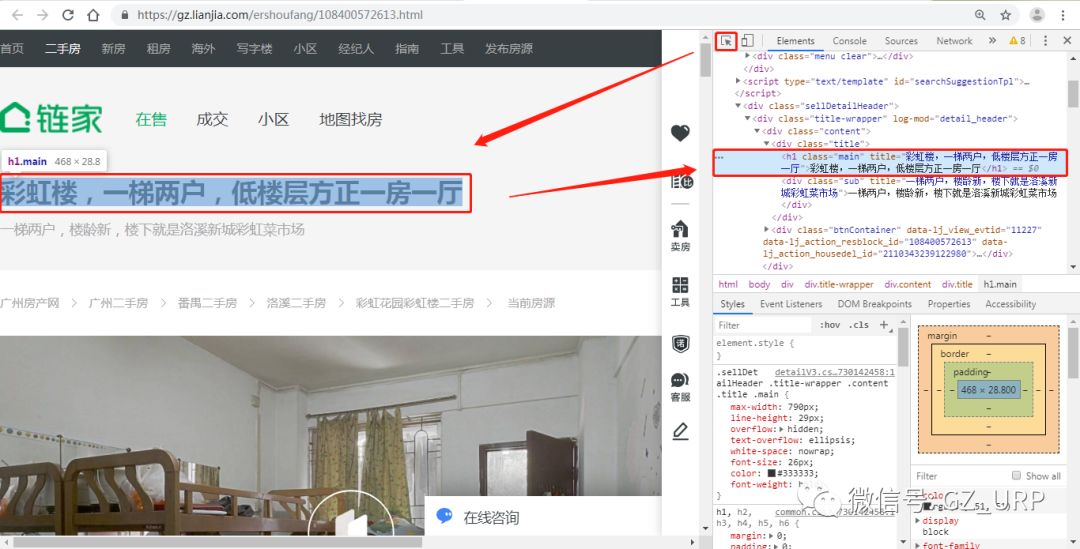
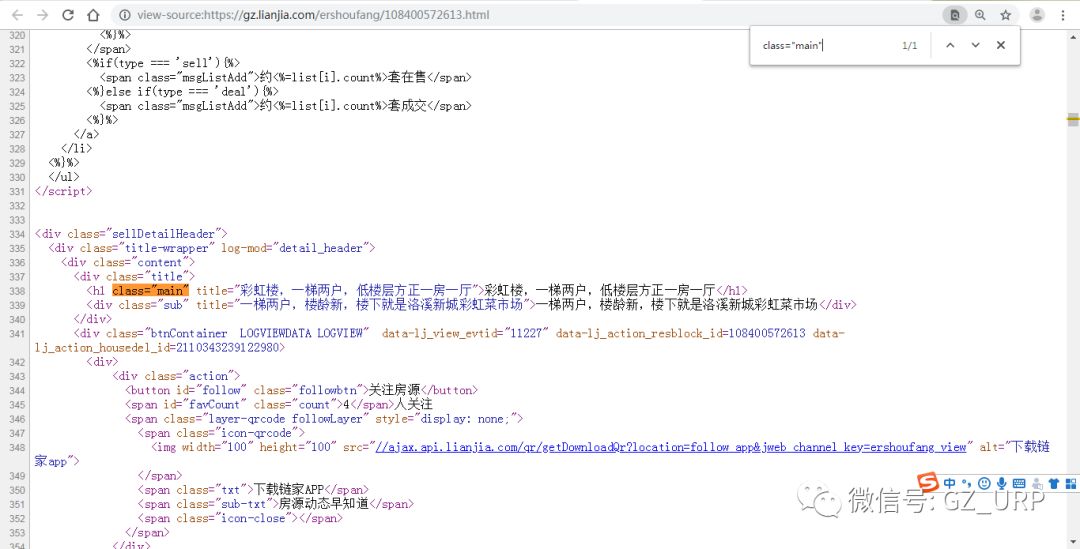
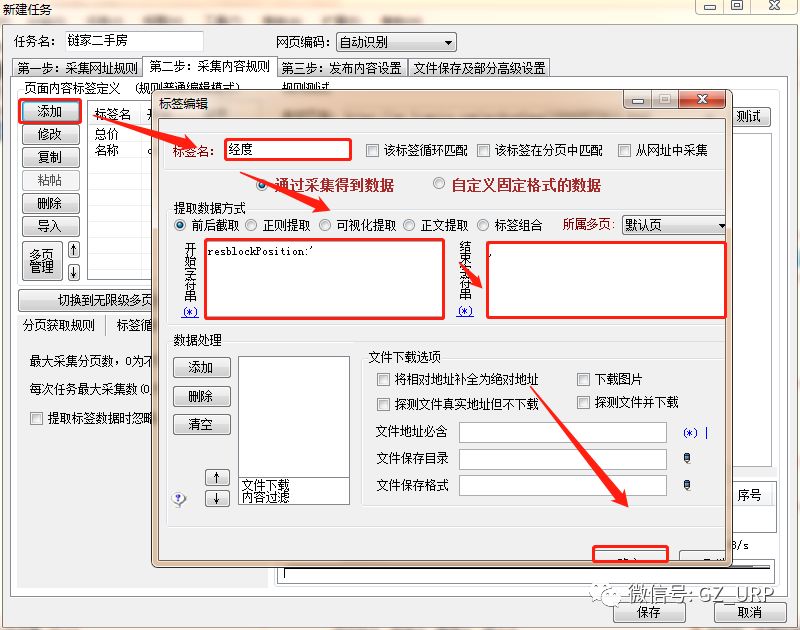
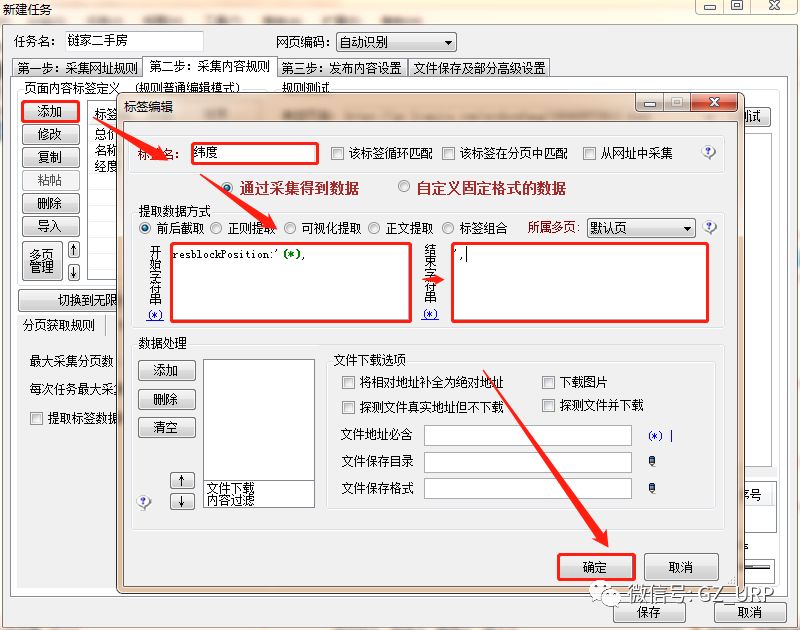
,我们可以通过前后截取获取房源名称。
点击【添加】一个标签,将标签名设置为【名称】,开始字段设置为【 title="】,结束字段就设置为【">】即可,点击确定。
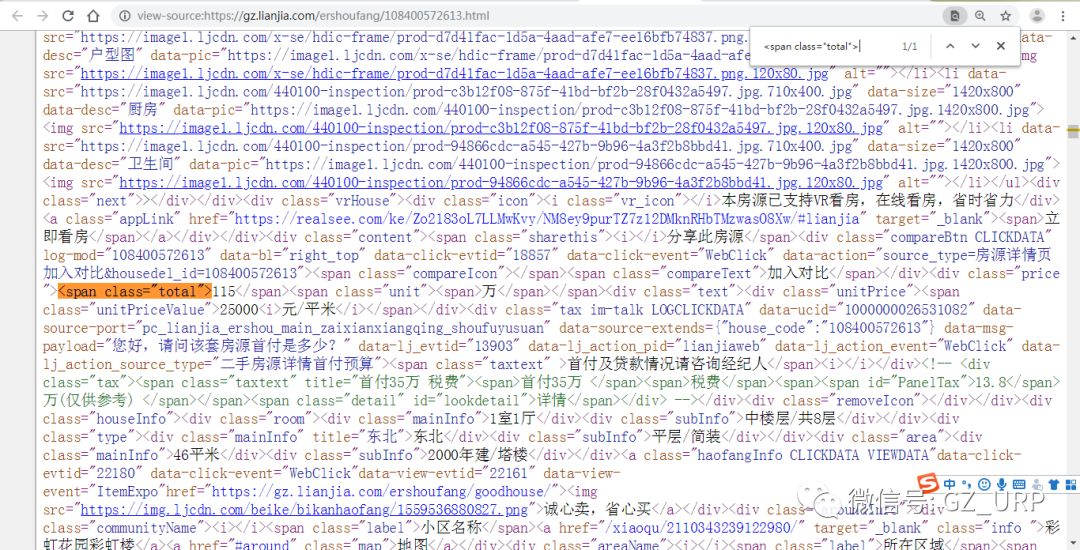
复制到网页源代码搜索,可以看到这个标签是唯一的(右上角1/1):
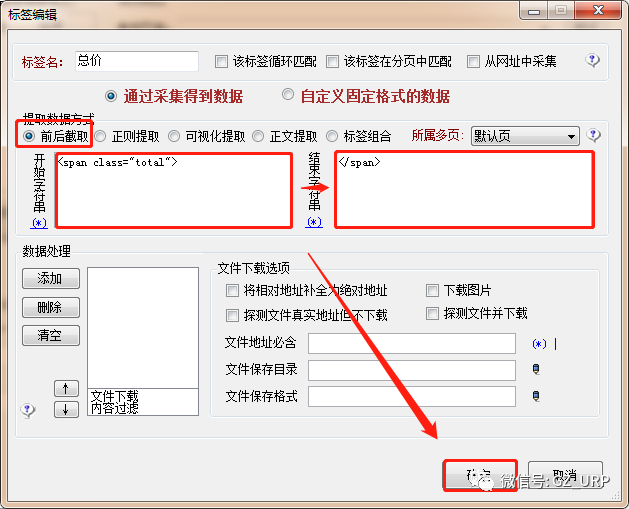
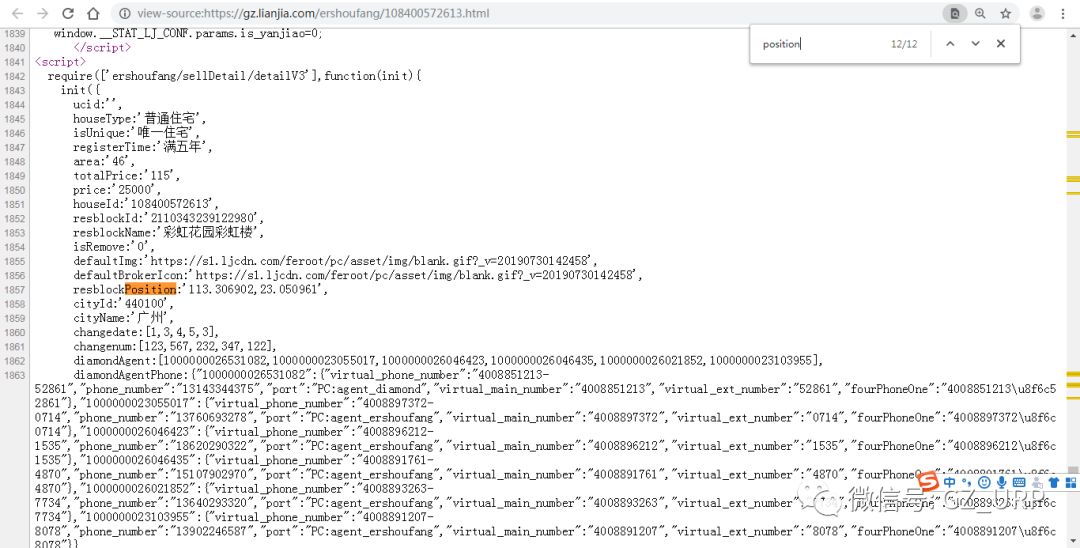
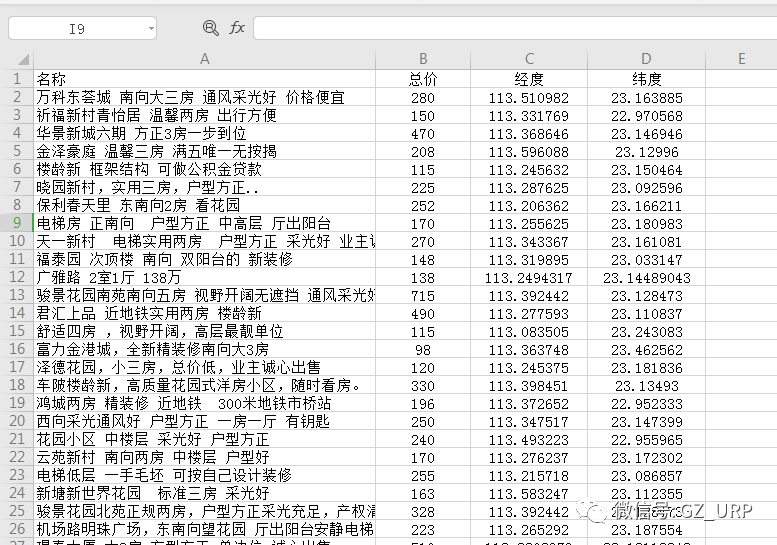
链接:https://pan.baidu.com/s/1flQC9TRhIli_lof5yfV17g
提取码:eu9k
拓展阅读: 【胡说八道01】地理如何影响人类历史并决定当今世界? 【地理信息01】ArcMap中CAD数据 / 坐标数据(表格数据)的加载 【地理信息02】最最最纠结的基础知识——坐标系的认识与转换 【地理信息03】基于LSV地图+手机GPS定位的现状调研数据库构建 【地理信息04】选址基础分析——以简单数据为例分析租房选址 【地理信息05】城市土地变更以及规划实施评价 【地理信息06】基于GIS平台的城市多网点设施布局评估
















 1603
1603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









