






项目上微服务,由于日志会散落在各个microservice,多主机甚至多数据中心,发现debug是非常地痛苦,同时新鲜血液的培训和沟通成本也会随之增加。因此,在思考引入分布式的trace,一方面能够更好提供debug手段,另一方面由于可以可视化调用链,因此相信新人更加能够快速入手。
我在网上google了一些分布式的trace解决方案,包括twitter的Zipkin, Uber的Jaeger以及sourcegraph的Appdash. 发现所有的工具背后原理都是参考dapper--google关于分布式trace的一篇技术报告。因此有必要对原文进行研究。
1.Dapper的原理
1.1 Trace的数据结构
Dapper的目标是提供可扩展,低开销,透明的分布式trace系统,其原理实际上非常直观和简单:Dapper引入了Span这个概念,每一次API的调用,都需要传递调用者的Span ID, 同时将当前的Span ID传给调用的API,作为调用方的SpanID会写入调用者的上下文,作为其父Span ID。我用文字描述可能比较绕,直接上官方原图,就可以看明白了:
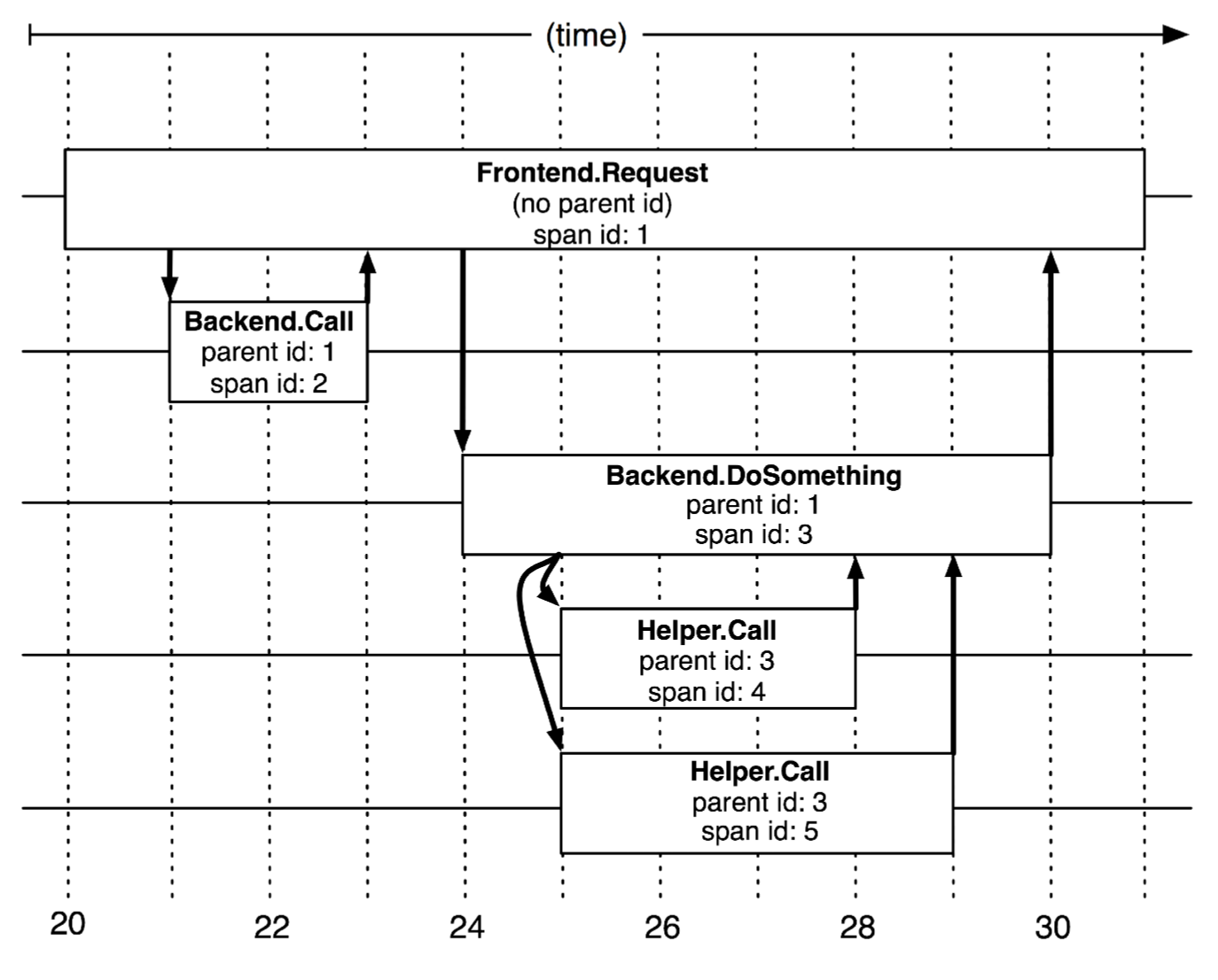
trace-tree
上面图里Span的长度可以认为是调用过程的执行时间,这样一方面我们就可以分析系统中的所有模块执行时间。另一方面,因为trace上下文中带有父Span ID和Span ID,我们可以很容易由上图生成一颗调用栈。
所以我们可以给每条trace的上下文中加入如下的首部,应该就能实现Dapper的trace结构:
type traceHead struct{
traceID int //标识每条trace
parentSpanID int //调用者ID
SpanID int //被调用者ID
timestamp int //被调用的时刻
name string //被调用的API name
}
1.2 Trace的收集
而如何收集trace,google论文也给出了简单的framework:
所有的trace都保存在log文件中;
collector通过运行在各个主机上的daemon程序读取log文件中的trace;
最终将trace保存在bigtable中,每一行的数据代表一条trace。
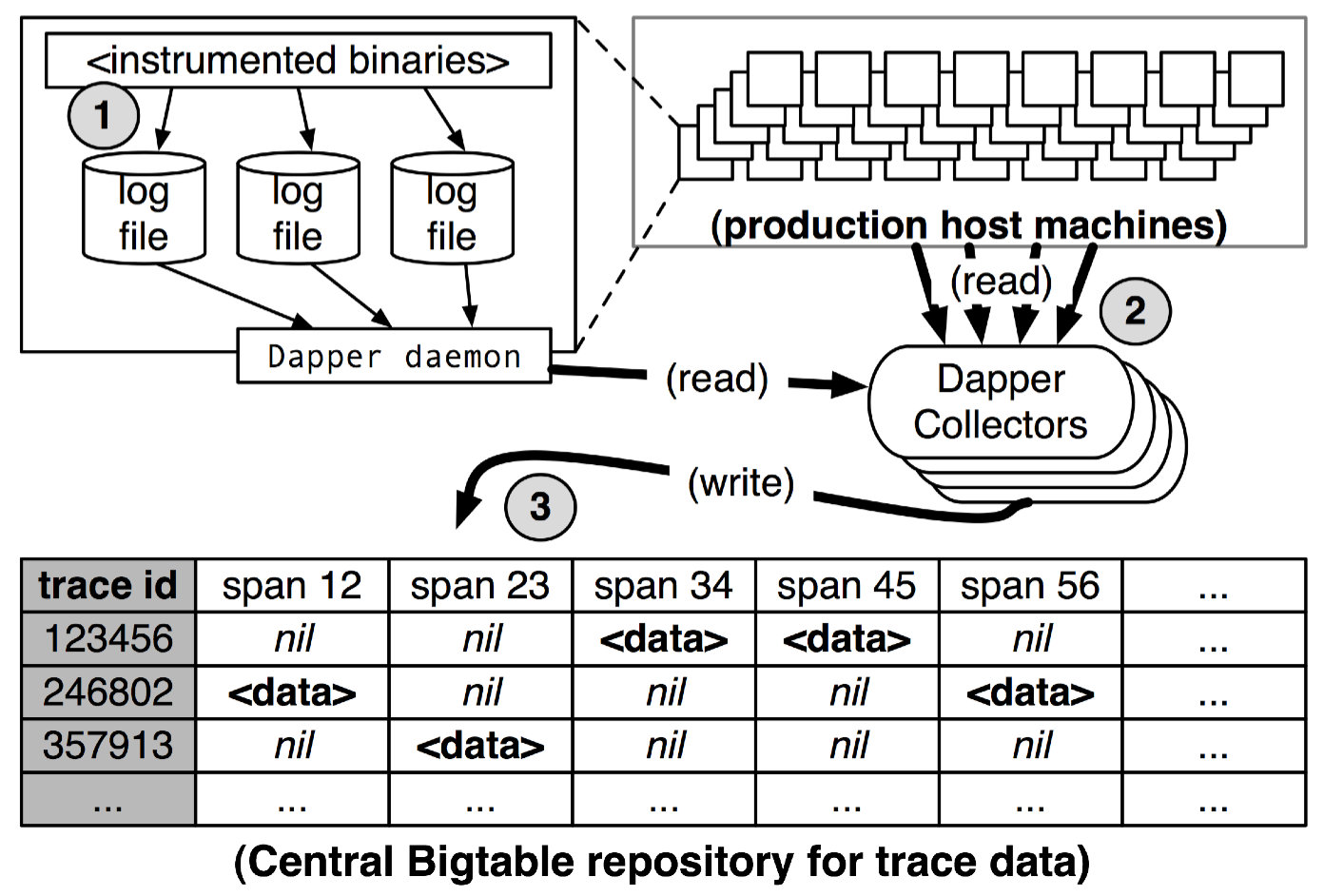
collection.png
总结
Dapper的原理实在是很简单,市面上的分布式trace系统基本上都是基于Dapper。后面我可能会采用Jaeger作为项目中的Trace工具,因为它支持istio,并且相对于Zipkin(Java), 我可能更愿意debug golang,有时间可以写一篇Jaeger的使用。















 1231
1231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









