







一、 Solr 介绍
1.全文检索
- 什么叫做全文检索呢?这要从我们生活中的数据说起。
- 我们生活中的数据总体分为两种:结构化数据和非结构化数据。
1)结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
2)非结构化数据:指不定长或无固定格式的数据,如邮件,word 文档等。
非结构化数据又一种叫法叫全文数据。 按照数据的分类,搜索也分为两种:
1)对结构化数据的搜索:如对数据库的搜索,用 SQL 语句。
2)对非结构化数据的搜索:如利用 windows 的搜索也可以搜索文件内容,Linux
下的 grep 命令,再如用 Google 和百度可以搜索大量内容数据。 2.Lucene
Lucene 是一个高效的,基于 Java 的全文检索库。
Lucene 是 apache 软件基金会 4 jakarta 项目组的一个子项目,是一个开放源代码的全 文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,
Lucene 的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现,全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene 是一套用于全文
检索和搜寻的开源程序库,由 Apache 软件基金会支持和提供。Lucene 提供了一个简单却强大的应用程序接口,能够做全文索引和搜寻。在 Java 开发环境里 Lucene 是一个成熟的
免费开源工具。就其本身而言,Lucene 是当前以及最近几年最受欢迎的免费 Java 信息检索程序库。 3.Solr 简介
Solr 是基于 Lucene 的面向企业搜索的 web 应用。
Solr 是一个独立的企业级搜索应用服务器,它对外提供类似于 Web-service 的 API 接口。用户可以通过 http 请求,向搜索引擎服务器提交一定格式的 XML 文件,生成索引,也
可以通过 Http Get 操作提出查找请求,并得到 xml/json 格式的返回结果。
Solr 是一个高性能,采用 Java5 开发,基于 Lucene 的全文搜索服务器。同时对其进行了扩展,提供了比 Lucene 更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能
进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文检索引擎。
文档通过 Http 利用 XML 加到一个搜索集合中。查询该集合也是通过 http 收到一个XML/JSON 响应来实现。它的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,高
亮显示搜索结果,通过索引复制来提高可用性,提供一套强大 Data Schema 来定义字段,类型和设置文本分析,提供基于 Web 的管理界面等。访问 Solr 服务

Solr 索引库:
solr home 目录结构。
solr.xml 配置 solr 集群。
collection1(索引库:solr core)。
core.properties 设置索引库的名称。
data 存放索引。
conf 索引库的配置目录。
schema.xml:配置字段以及字段类型。索引库配置 :
schema.xml 是用来定义索引数据中的域的,包括域名称,域类型,域是否索引,是否分词,是否存储等等。 如何定义索引库中的 Field :
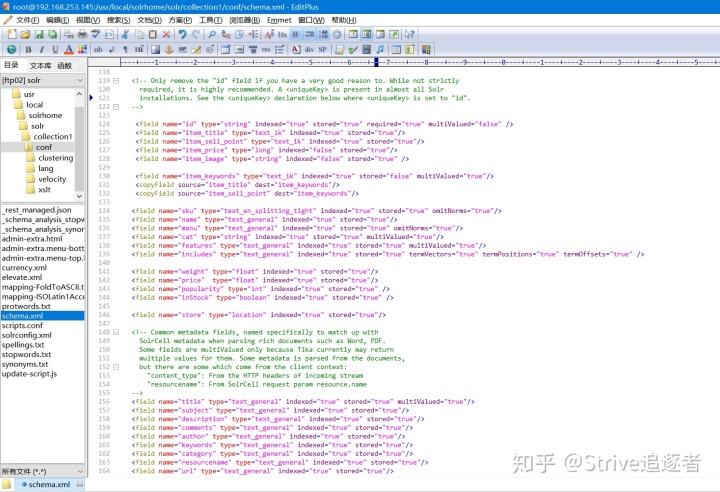
filed:定义域
name:表示域的名称,是强制必须有的属性
type:域类型的名称,与 fieldType 元素的 name 属性值对应,是强制必须有的属性 。
indexed:是否参与检索,true 即表示需要对该域进行索引,默认值为 false 。
stored:是否将 field 域中的内容存储到文档域,简单通俗的来说,就是你这一个field 需不需要被当作查询结果返回。
required:表示这个域是否是必须要在 document 中存在,默认值为 false,如果此配置项设为 true,则你的 document 中必须要添加此域,否则你创建索引时会抛异常。如何定义索引库中的 FieldType :

filedType:定义域的类型
Name:域类型的名称,作为域类型标识符存在,在定义域(Field)时使用的类型(FieldType)属性就是域类型的名称。
Class:域类型的数据类型,该属性指向的是 solr 中的已定义的类型,或者是用户定义的类型,域类型中的数据会被初始化成 class 执行类类的对象。
sortMissingFirst/sortMissingLast:控制当排序域的值不存在时该文档(Document)所在队列的位置,true 是则在队头/队尾。如何定义索引库中的 CopyField :
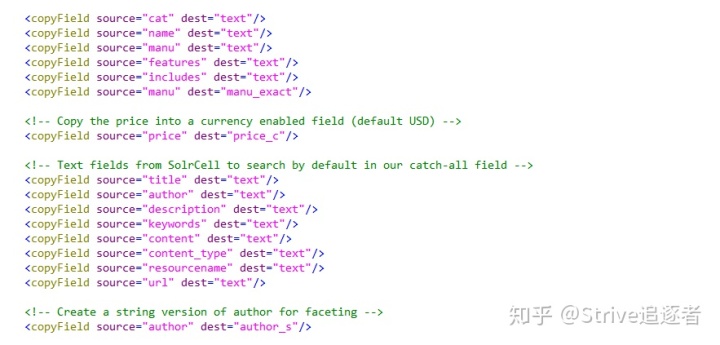
<copyFiled>:复制域。可实现更新与查询分离
Source:源域
Dest:目标域 Solr 的索引机制 :
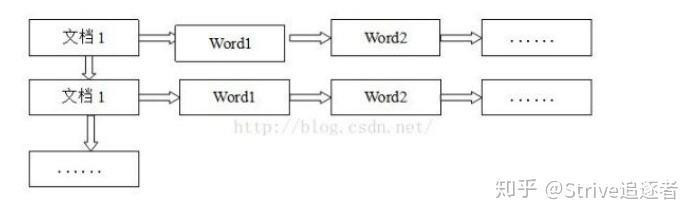
正排索引(正向索引)
正排索引是以文档的 ID 为关键字,索引文档中每个字的位置信息,查找时扫描索引中每个文档中字的信息直到找出所有包含查询关键字的文档。
但是在查询的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下。
尽管正排索引的工作原理非常的简单,但是由于其检索效率太低,除非在特定情况下,否则实用性价值不大。 正排索引从文档编号找词 :
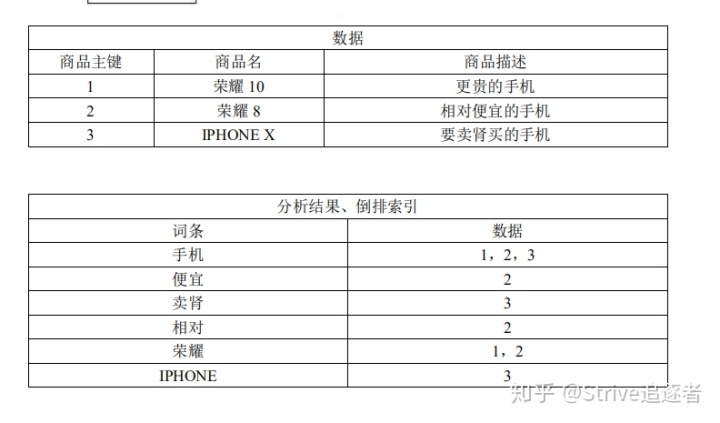
倒排索引(反向索引)
对数据进行分析,抽取出数据中的词条,以词条作为 key,对应数据的存储位置作为value,实现索引的存储。这种索引称为倒排索引。
当 solr 存储文档时,solr 会首先对文档数据进行分词,创建索引库和文档数据库。
所谓的分词是指:
将一段字符文本按照一定的规则分成若干个单词。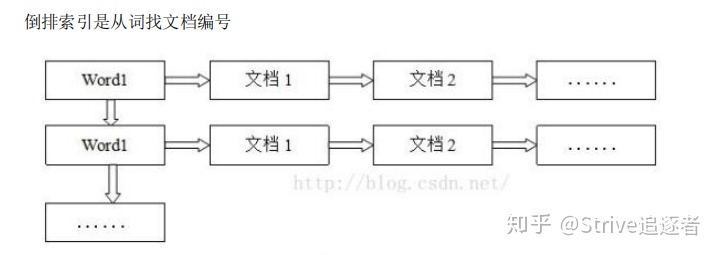
Solr 管理页面操作 :
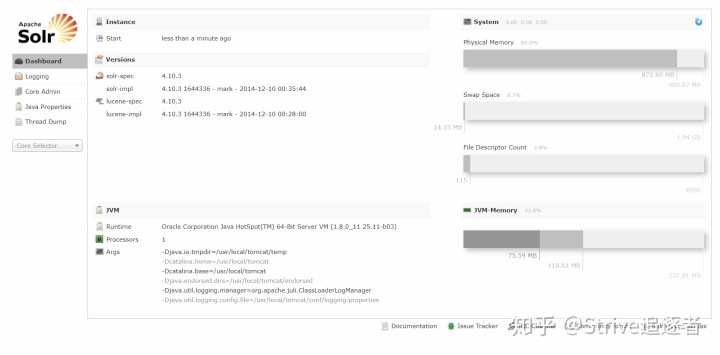
Dashboard(仪表盘)
访问 http://localhost:8080/solr 时,出现该主页面,可查看到 solr 运行时间、solr 版本,系统内存、虚拟机内存的使用情况Logging(日志)
显示 solr 运行出现的异常或错误Core Admin (core 管理)
主要有 Add Core(添加核心),Unload(卸载核心),Rename(重命名核心),Reload(重新加载核心),Optimize(优化索引库)
Add Core 是添加 core : 主 要 是 在 instanceDir 对 应 的 文 件 夹 里 生 成 一 个core.properties 文件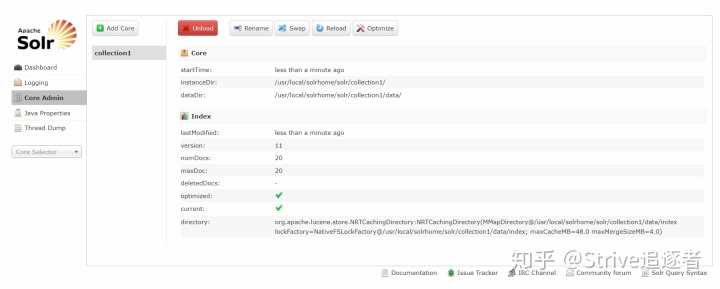
name:给 core 起的名字;
instanceDir:与我们在配置 solr 到 tomcat 里时的 solr_home 里新建的 core文件夹名一致;
dataDir:确认 Add Core 时,会在 new_core 目录下生成名为 data 的文件夹
config:new_core 下的 conf 下的 config 配置文件(solrconfig.xml)
schema: new_core 下的 conf 下的 schema 文件(schema.xml) 













 275
275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









