





作为机器学习中的一大类模型,树模型一直以来都颇受学界和业界的重视。目前无论是各大比赛各种大杀器的XGBoost、lightgbm还是像随机森林、Adaboost等典型集成学习模型,都是以决策树模型为基础的。传统的经典决策树算法包括ID3算法、C4.5算法以及GBDT的基分类器CART算法。
三大经典决策树算法最主要的区别在于其特征选择准则的不同。ID3算法选择特征的依据是信息增益、C4.5是信息增益比,而CART则是Gini指数。作为一种基础的分类和回归方法,决策树可以有如下两种理解方式。一种是我们可以将决策树看作是一组if-then规则的集合,另一种则是给定特征条件下类的条件概率分布。关于这两种理解方式,读者朋友可深入阅读相关教材进行理解,笔者这里补详细展开。
根据上述两种理解方式,我们既可以将决策树的本质视作从训练数据集中归纳出一组分类规则,也可以将其看作是根据训练数据集估计条件概率模型。整个决策树的学习过程就是一个递归地选择最优特征,并根据该特征对数据集进行划分,使得各个样本都得到一个最好的分类的过程。
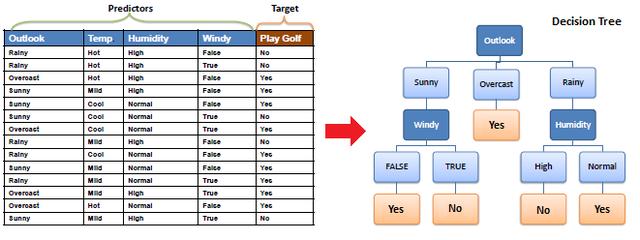
ID3算法理论
所以这里的关键在于如何选择最优特征对数据集进行划分。答案就是前面提到的信息增益、信息增益比和Gini指数。因为本篇针对的是ID3算法,所以这里笔者仅对信息增益进行详细的表述。
在讲信息增益之前,这里我们必须先介绍下熵的概念。在信息论里面,熵是一种表示随机变量不确定性的度量方式。若离散随机变量X的概率分布为:
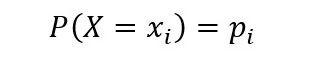
则随机变量X的熵定义为:
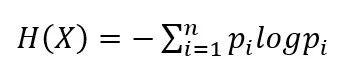
同理,对于连续型随机变量Y,其熵可定义为:
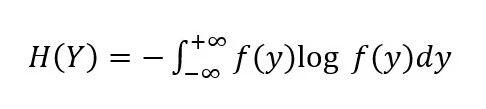
当给定随机变量X的条件下随机变量Y的熵可定义为条件熵H(Y|X):
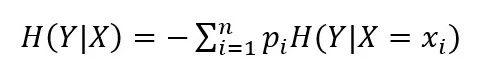
所谓信息增益就是数据在得到特征X的信息时使得类Y的信息不确定性减少的程度。假设数据集D的信息熵为H(D),给定特征A之后的条件熵为H(D|A),则特征A对于数据集的信息增益g(D,A)可表示为:
g(D,A) = H(D) - H(D|A)
信息增益越大,则该特征对数据集确定性贡献越大,表示该特征对数据有较强的分类能力。信息增益的计算示例如下:
1)计算目标特征的信息熵

2)计算加入某个特征之后的条件熵
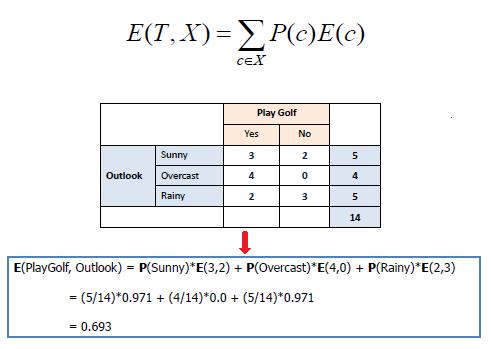
3)计算信息增益
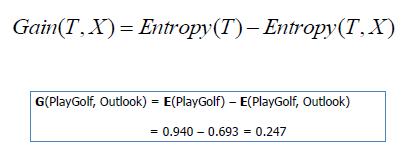
以上就是ID3算法的核心理论部分,至于如何基于ID3构造决策树,我们在代码实例中来看。

ID3算法实现
先读入示例数据集:
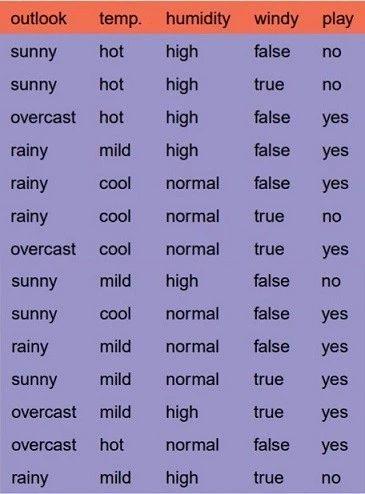
1import numpy as np2import pandas as pd3from math import log45df = pd.read_csv('./example_data.csv')6df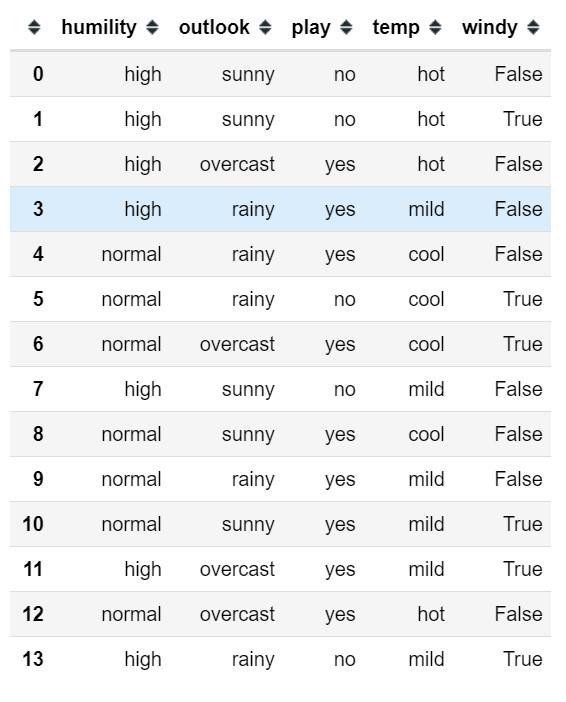
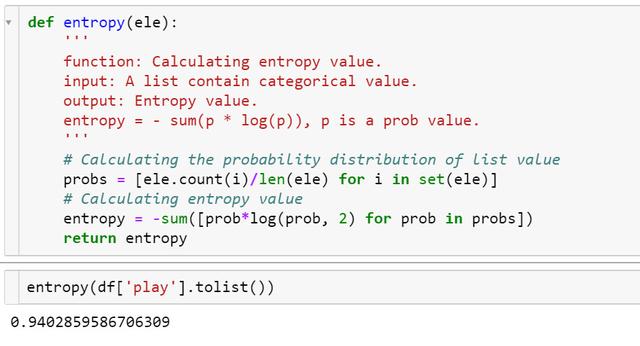
定义熵的计算函数:
1def entropy(ele): 2 ''' 3 function: Calculating entropy value. 4 input: A list contain categorical value. 5 output: Entropy value. 6 entropy = - sum(p * log(p)), p is a prob value. 7 ''' 8 # Calculating the probability distribution of list value 9 probs = [ele.count(i)/len(ele) for i in set(ele)] 10 # Calculating entropy value11 entropy = -sum([prob*log(prob, 2) for prob in probs]) 12 return entropy计算示例:
然后我们需要定义根据特征和特征值进行数据划分的方法:
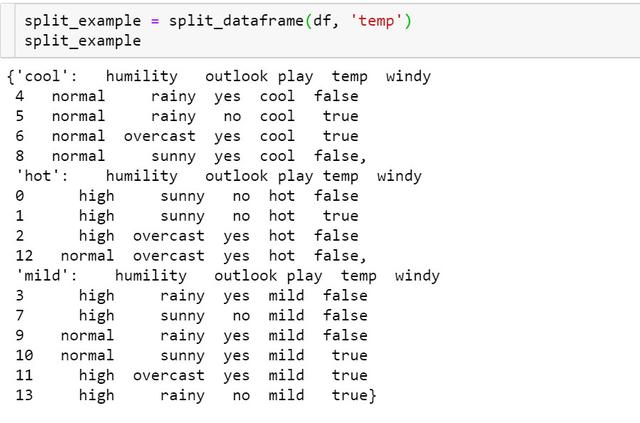
1def split_dataframe(data, col): 2 ''' 3 function: split pandas dataframe to sub-df based on data and column. 4 input: dataframe, column name. 5 output: a dict of splited dataframe. 6 ''' 7 # unique value of column 8 unique_values = data[col].unique() 9 # empty dict of dataframe10 result_dict = {elem : pd.DataFrame for elem in unique_values} 11 # split dataframe based on column value12 for key in result_dict.keys():13 result_dict[key] = data[:][data[col] == key] 14 return result_dict根据temp和其三个特征值的数据集划分示例:
然后就是根据熵计算公式和数据集划分方法计算信息增益来选择最佳特征的过程:
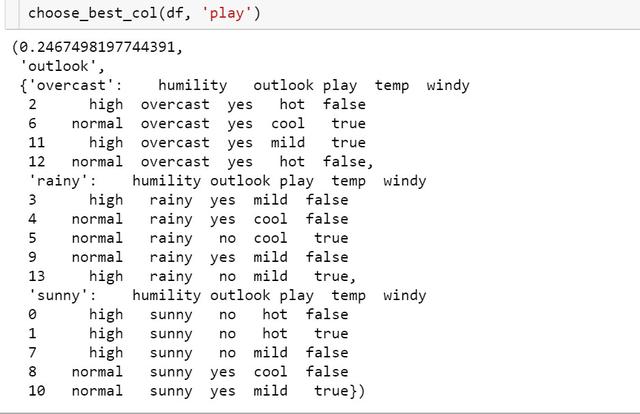
1def choose_best_col(df, label): 2 ''' 3 funtion: choose the best column based on infomation gain. 4 input: datafram, label 5 output: max infomation gain, best column, 6 splited dataframe dict based on best column. 7 ''' 8 # Calculating label's entropy 9 entropy_D = entropy(df[label].tolist()) 10 # columns list except label11 cols = [col for col in df.columns if col not in [label]] 12 # initialize the max infomation gain, best column and best splited dict13 max_value, best_col = -999, None14 max_splited = None15 # split data based on different column16 for col in cols:17 splited_set = split_dataframe(df, col)18 entropy_DA = 019 for subset_col, subset in splited_set.items(): 20 # calculating splited dataframe label's entropy21 entropy_Di = entropy(subset[label].tolist()) 22 # calculating entropy of current feature23 entropy_DA += len(subset)/len(df) * entropy_Di 24 # calculating infomation gain of current feature25 info_gain = entropy_D - entropy_DA 26 if info_gain > max_value:27 max_value, best_col = info_gain, col28 max_splited = splited_set 29 return max_value, best_col, max_splited最先选到的信息增益最大的特征是outlook:
决策树基本要素定义好后,我们即可根据以上函数来定义一个ID3算法类,在类里面定义构造ID3决策树的方法:
1class ID3Tree: 2 # define a Node class 3 class Node: 4 def __init__(self, name): 5 self.name = name 6 self.connections = {} 7 8 def connect(self, label, node): 9 self.connections[label] = node 1011 def __init__(self, data, label):12 self.columns = data.columns13 self.data = data14 self.label = label15 self.root = self.Node("Root") 1617 # print tree method18 def print_tree(self, node, tabs):19 print(tabs + node.name) 20 for connection, child_node in node.connections.items():21 print(tabs + "" + "(" + connection + ")")22 self.print_tree(child_node, tabs + "") 2324 def construct_tree(self):25 self.construct(self.root, 













 459
459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









