





点击上方蓝字,和我一起学技术。

今天是机器学习专题的第22篇文章,我们继续决策树的话题。
上一篇文章当中介绍了一种最简单构造决策树的方法——ID3算法,也就是每次选择一个特征进行拆分数据。这个特征有多少个取值那么就划分出多少个分叉,整个建树的过程非常简单。如果错过了上篇文章的同学可以从下方传送门去回顾一下:
如果你还不会决策树,那你一定要进来看看
既然我们已经有了ID3算法可以实现决策树,那么为什么还需要新的算法?显然一定是做出了一些优化或者是进行了一些改进,不然新算法显然是没有意义的。所以在我们学习新的算法之前,需要先搞明白,究竟做出了什么改进,为什么要做出这些改进。
一般来说,改进都是基于缺点和不足的,所以我们先来看看ID3算法的一些问题。
其中最大的问题很明显,就是它无法处理连续性的特征。不能处理的原因也很简单,因为ID3在每次在切分数据的时候,选择的不是一个特征的取值,而是一个具体的特征。这个特征下有多少种取值就会产生多少个分叉,如果使用连续性特征的话,比如说我们把西瓜的直径作为特征的话。那么理论上来说每个西瓜的直径都是不同的,这样的数据丢进ID3算法当中就会产生和样本数量相同的分叉,这显然是没有意义的。
其实还有一个问题,藏得会比较深一点,是关于信息增益的。我们用划分前后的信息熵的差作为信息增益,然后我们选择带来最大信息增益的划分。这里就有一个问题了,这会导致模型在选择的时候,倾向于选择分叉比较多的特征。极端情况下,就比如说是连续性特征好了,每个特征下都只有一个样本,那么这样算出来得到的信息熵就是0,这样得到的信息增益也就非常大。这是不合理的,因为分叉多的特征并不一定划分效果就好,整体来看并不一定是有利的。
针对这两个问题,提出了改进方案,也就是说C4.5算法。严格说起来它并不是独立的算法,只是ID3算法的改进版本。
下面我们依次来看看C4.5算法究竟怎么解决这两个问题。
信息增益比
首先,我们来看信息增益的问题。前面说了,如果我们单纯地用信息增益去筛选划分的特征,那么很容易陷入陷阱当中,选择了取值更多的特征。
针对这个问题,我们可以做一点调整,我们把信息增益改成信息增益比。所谓的信息增益比就是用信息增益除以我们这个划分本身的信息熵,从而得到一个比值。对于分叉很多的特征,它的自身的信息熵也会很大。因为分叉多,必然导致纯度很低。所以我们这样可以均衡一下特征分叉带来的偏差,从而让模型做出比较正确的选择。
我们来看下公式,真的非常简单:
这里的D就是我们的训练样本集,a是我们选择的特征,IV(a)就是这个特征分布的信息熵。 我们再来看下IV的公式: 解释一下这里的值,这里的V是特征a所有取值的集合。自然就是每一个v对应的占比,所以这就是一个特征a的信息熵公式。处理连续值
C4.5算法对于连续值同样进行了优化,支持了连续值,支持的方式也非常简单,对于特征a的取值集合V来说,我们选择一个阈值t进行划分,将它划分成小于t的和大于t的两个部分。 也就是说C4.5算法对于连续值的切分和离散值是不同的,对于离散值变量,我们是对每一种取值进行切分,而对于连续值我们只切成两份。其实这个设计非常合理,因为对于大多数情况而言,每一条数据的连续值特征往往都是不同的。而且我们也没有办法很好地确定对于连续值特征究竟分成几个部分比较合理,所以比较直观的就是固定切分成两份,总比无法用上好。 在极端情况下,连续值特征的取值数量等于样本条数,那么我们怎么选择这个阈值呢?即使我们遍历所有的切分情况,也有n-1种,这显然是非常庞大的,尤其在样本数量很大的情况下。 针对这个问题,也有解决的方法,就是按照特征值排序,选择真正意义上的切分点。什么意思呢,我们来看一份数据: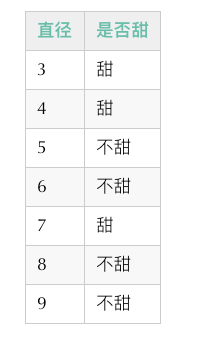
代码实现
光说不练假把式,我们既然搞明白了它的原理,就得自己亲自动手实现一下才算是真的理解,很多地方的坑也才算是真的懂。我们基本上可以沿用之前的代码,不过需要在之前的基础上做一些修改。 首先我们先来改造构造数据的部分,我们依然沿用上次的数据,学生的三门考试等级以及它是否通过达标的数据。我们认为三门成绩在150分以上算是达标,大于70分的课程是2等级,40-70分之间是1等级,40分以下是0等级。在此基础上我们增加了分数作为特征,我们在分数上增加了一个误差,避免模型直接得到结果。import numpy as npimport mathdef create_data():
X1 = np.random.rand(50, 1)*100
X2 = np.random.rand(50, 1)*100
X3 = np.random.rand(50, 1)*100def f(x):return 2 if x > 70 else 1 if x > 40 else 0# 学生的分数作为特征,为了公平,加上了一定噪音
X4 = X1 + X2 + X3 + np.random.rand(50, 1) * 20
y = X1 + X2 + X3
Y = y > 150
Y = Y + 0
r = map(f, X1)
X1 = list(r)
r = map(f, X2)
X2 = list(r)
r = map(f, X3)
X3 = list(r)
x = np.c_[X1, X2, X3, X4, Y]return x, ['courseA', 'courseB', 'courseC', 'score']def info_gain(dataset, idx):# 计算基本的信息熵
entropy = calculate_info_entropy(dataset)
m = len(dataset)# 根据特征拆分数据
split_data, _ = split_dataset(dataset, idx)
new_entropy = 0.0# 计算拆分之后的信息熵for data in split_data:
prob = len(data) / m# p * log(p)
new_entropy += prob * calculate_info_entropy(data)return entropy - new_entropydef info_gain_ratio(dataset, idx, thred=None):# 拆分数据,需要将阈值传入,如果阈值不为None直接根据阈值划分# 否则根据特征值划分
split_data, _ = split_dataset(dataset, idx, thred)
base_entropy = 1e-5
m = len(dataset)# 计算特征本身的信息熵for data in split_data:
prob = len(data) / m
base_entropy -= prob * math.log(prob, 2)return info_gain(dataset, idx) / base_entropy, threddef split_dataset(dataset, idx, thread=None):
splitData = defaultdict(list)# 如果阈值为None那么直接根据特征划分if thread is None:for data in dataset:
splitData[data[idx]].append(np.delete(data, idx))return list(splitData.values()), list(splitData.keys())else:# 否则根据阈值划分,分成两类大于和小于for data in dataset:
splitData[data[idx] return list(splitData.values()), list(splitData.keys())def get_thresholds(X, idx):# numpy多维索引用法
new_data = X[:, [idx, -1]].tolist()# 根据特征值排序
new_data = sorted(new_data, key=lambda x: x[0], reverse=True)
base = new_data[0][1]
threads = []for i in range(1, len(new_data)):
f, l = new_data[i]# 如果label变化则记录if l != base:
base = l
threads.append(f)return threadsdef choose_feature_to_split(dataset):
n = len(dataset[0])-1
m = len(dataset)# 记录最佳增益比、特征和阈值
bestGain = 0.0
feature = -1
thred = Nonefor i in range(n):# 判断是否是连续性特征,默认整数型特征不是连续性特征# 这里只是我个人的判断逻辑,可以自行diyif not dataset[0][i].is_integer():
threds = get_thresholds(dataset, i)for t in threds:# 遍历所有的阈值,计算每个阈值的信息增益比
ratio, th = info_gain_ratio(dataset, i, t)if ratio > bestGain:
bestGain, feature, thred = ratio, i, telse:# 否则就走正常特征拆分的逻辑,计算增益比
ratio, _ = info_gain_ratio(dataset, i) if ratio > bestGain:
bestGain = ratio
feature, thred = i, Nonereturn feature, threddef create_decision_tree(dataset, feature_names):
dataset = np.array(dataset)# 如果都是一类,那么直接返回类别
counter = Counter(dataset[:, -1])if len(counter) == 1:return dataset[0, -1]# 如果只有一个特征了,直接返回占比最多的类别if len(dataset[0]) == 1:return counter.most_common(1)[0][0]# 记录最佳拆分的特征和阈值
fidx, th = choose_feature_to_split(dataset)
fname = feature_names[fidx]
node = {fname: {'threshold': th}}
feature_names.remove(fname)
split_data, vals = split_dataset(dataset, fidx, th)for data, val in zip(split_data, vals):
node[fname][val] = create_decision_tree(data, feature_names[:])return nodedef classify(node, feature_names, data):
key = list(node.keys())[0]
node = node[key]
idx = feature_names.index(key)
pred = None
thred = node['threshold']# 如果阈值为None,那么直接遍历dictif thred is None:for key in node:if key != 'threshold' and data[idx] == key:if isinstance(node[key], dict):
pred = classify(node[key], feature_names, data)else:
pred = node[key]else:# 否则直接访问if isinstance(node[data[idx] pred = classify(node[data[idx] else:
pred = node[data[idx] # 放置pred为空,挑选一个叶子节点作为替补if pred is None:for key in node:if not isinstance(node[key], dict):
pred = node[key]breakreturn pred














 6377
6377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









