






第一部分:写作动机
以往总想写点什么东西来记录自己的学习历程,记录自己遇到的难题。但是当自己真正把难题解决了之后,又总是心想着反正都知道怎么解决了,还记录下来有什么用呢,再加上懒惰等因素,每次都难以提笔。现在打算逐渐克服这些因素,随着学习的历程,将自己的所思所感都记录下来,便于自己查阅,更便于大家一起交流。
第二部分:本文内容
相信不少搞深度学习的小伙伴都有使用tensorflow的习惯。Tensorflow的流行度以及其优势我自然不必多说。大多数搞计算机视觉(CV)的小伙伴都有使用卷积神经网络(CNN)的经历,一般地,都是将图像resize成长和宽都一样的批量数据,格式为(batch_size, height, width, channel),分别表示为:mini_batch大小、图像的高(图像的行数)、图像的宽(图像的列数)和通道数。使用tensorflow的数据读取机制,比如实用tensorflow内置队列机制,或者Dataset类,如果要批量读取图像,首先就一定要把图像的height和width都resize成统一的数字,不然不可能将一个batch的图像一次性送入网络。如下图2-1,是小伙伴们一般性的做法。
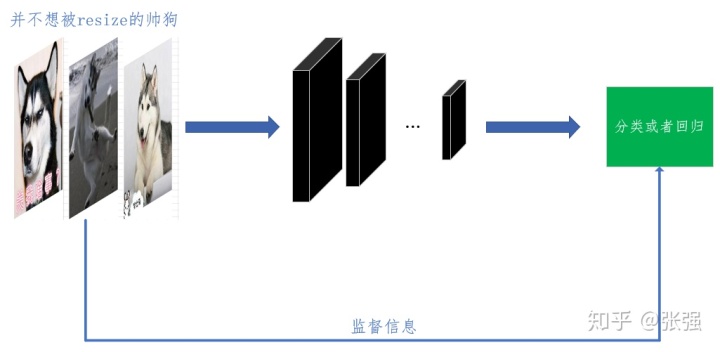
图2-1 一般性的网络分类
但是如果我们要面临一种情况:要将不同尺度的图像塞进网络进行训练,该怎么办?
最简单的方法当然是每次仅仅读取一张图像,当然也有不少方法是这样做的,比如最初使用的caffe版本的faster rcnn等。可是具有强迫症的小伙伴肯定不愿意就此停住追求自己想法的脚步,一定要让长和夸不同的图像进行批量训练当然不是不可能,以下来详解我自己得出的一个想法(已验证可正常训练)
第三部分:长和夸不一致的图像批量训练(不用resize)
实际可行的方法较多,由于个人精力有限(主要还是懒惰),本文仅以一种想法进行说明,本文想法比较简单,整个过程如图3-1所示。首先就是开启多个输入通道,每个通道每次仅读取一张图像,图像读取通道的数目即为batch_size的数目。如图3-1所示,表示开启了两个通道,每个通道相互独立,各自读取图像。上面一个分支和下面一个分支网络结构相同且参数共享(这是关键,不然就不是一个模型而是两个模型了,是不是想到了Siamese?)。两个分支,由于不同卷积层或者全连接层参数共享,所以在tensorflow中,实际上为两个Graph,却表示一个网络模型,两个Graph各自接受来自不同图像输入通道的图像,表示这一个网络模型同时接受两个图像的输入(batch_size为2)。上面的一个Graph分支可计算出

图3-1 不同尺度图像的批量训练的思路
一个Loss,下面一个Graph也可以计算出来一个Loss,最后将两个Loss求平均,得到batch_size为2的情况得到的最终损失Loss,根据这个最终Loss,进行网络参数的优化,最终以实现不同尺度图像的批量训练。
第四部分:代码实现
本文以cifar10分类为例,进行说明。首先提取cifar10的图像,在[32,64,128]这个列表中随机选择两个数字,对原始的图像进行resize,形成大小不同的训练图像。这一部分涉及到简单图像的处理,就不用多说了。Python就几行代码罢了。
1)接下来实现网络模型(代码没有认证整理,稍乱),如下所示:
- #coding:utf-8
- import tensorflow as tf
- import numpy as np
- from functools import reduce
- from tensorflow.python.ops import control_flow_ops
- from tensorflow.python.training import moving_averages
- UPDATE_OPS_COLLECTION = 'resnet_update_ops'
- VGG_MEAN = [103.939, 116.779, 123.68]
- class vgg16:
- def __init__(self, vgg16_npy_path=None, trainable=True, dropout=0.5,count=1):
- if vgg16_npy_path is not None:
- self.data_dict = np.load(vgg16_npy_path, encoding='latin1').item()
- else:
- self.data_dict = None
- self.names = globals()
- self.var_dict = {}
- self.trainable = trainable
- self.dropout = dropout
- self.NUM_CLASSES = 10
- self.count = count
- def build(self, rgb, train_mode=None):
- print('nbuild network...')
- rgb_scaled = rgb * 1.0
- red, green, blue = tf.split(axis=3, num_or_size_splits=3, value=rgb_scaled)
- '''
- assert red.get_shape().as_list()[1:] == [224, 224, 1]
- assert green.get_shape().as_list()[1:] == [224, 224, 1]
- assert blue.get_shape().as_list()[1:] == [224, 224, 1]
- '''
- bgr = tf.concat(axis=3, values=[blue - VGG_MEAN[0],green - VGG_MEAN[1],red - VGG_MEAN[2]])
- '''
- assert bgr.get_shape().as_list()[1:] == [224, 224, 3]
- '''
- self.conv1_1 = self.conv_layer(bgr, 3,64,"conv1_1")
- self.conv1_2 = self.conv_layer(self.conv1_1, 64,64,"conv1_2")
- self.pool1 = self.max_pool(self.conv1_2, 'pool1')
- self.conv2_1 = self.conv_layer(self.pool1, 64,128,"conv2_1")
- self.conv2_2 = self.conv_layer(self.conv2_1,128 ,128,"conv2_2")
- self.pool2 = self.max_pool(self.conv2_2, 'pool2')
- self.conv3_1 = self.conv_layer(self.pool2, 128,256,"conv3_1")
- self.conv3_2 = self.conv_layer(self.conv3_1,256,256,"conv3_2")
- self.conv3_3 = self.conv_layer(self.conv3_2, 256,256,"conv3_3")
- self.pool3 = self.max_pool(self.conv3_3, 'pool3')
- self.conv4_1 = self.conv_layer(self.pool3, 256,512, "conv4_1")
- self.conv4_2 = self.conv_layer(self.conv4_1,512,512,"conv4_2")
- self.conv4_3 = self.conv_layer(self.conv4_2,512,512, "conv4_3")
- self.pool4 = self.max_pool(self.conv4_3, 'pool4')
- self.conv5_1 = self.conv_layer(self.pool4,512,512, "conv5_1")
- self.conv5_2 = self.conv_layer(self.conv5_1,512,512, "conv5_2")
- self.conv5_3 = self.conv_layer(self.conv5_2,512,512, "conv5_3")
- self.pool5 = self.max_pool(self.conv5_3, 'pool5')
- self.pool5 = tf.reduce_mean(self.pool5,[1,2])
- self.fc6 = self.fc_layer(self.pool5, 512, 512, "fc_6")
- self.relu6 = tf.nn.relu(self.fc6)
- if train_mode is not None:
- self.relu6 = tf.cond(train_mode, lambda: tf.nn.dropout(self.relu6, self.dropout),lambda: self.relu6)
- elif self.trainable:
- self.relu6 = tf.nn.dropout(self.relu6, self.dropout)
- self.fc7 = self.fc_layer(self.relu6, 512, 512, "fc_7")
- self.relu7 = tf.nn.relu(self.fc7)
- if train_mode is not None:
- self.relu7 = tf.cond(train_mode, lambda: tf.nn.dropout(self.relu7, self.dropout), lambda: self.relu7)
- elif self.trainable:
- self.relu7 = tf.nn.dropout(self.relu7, self.dropout)
- self.fc8 = self.fc_layer(self.relu7, 512, self.NUM_CLASSES, 'fc8_pred')
- self.pred = tf.nn.softmax(self.fc8,name='pred')
- def avg_pool(self, bottom, name):
- return tf.nn.avg_pool(bottom, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name=name)
- def max_pool(self, bottom, name):
- return tf.nn.max_pool(bottom, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name=name)
- def conv_layer(self, bottom, in_channels, out_channels, name):
- if self.count == 1:
- with tf.variable_scope(name):
- filt, conv_biases = self.get_conv_var(3, in_channels, out_channels, name)
- conv = tf.nn.conv2d(bottom, filt, [1, 1, 1, 1], padding='SAME')
- bias = tf.nn.bias_add(conv, conv_biases)
- relu = tf.nn.relu(bias)
- return relu
- else:
- filt = tf.get_default_graph().get_tensor_by_name(name+'/'+name+'_filters:0')
- conv_biases = tf.get_default_graph().get_tensor_by_name(name+'/'+name+'_biases:0')
- conv = tf.nn.conv2d(bottom, filt, [1, 1, 1, 1], padding='SAME')
- bias = tf.nn.bias_add(conv, conv_biases)
- relu = tf.nn.relu(bias)
- return relu
- def fc_layer(self, bottom, in_size, out_size, name):
- if self.count == 1:
- with tf.variable_scope(name):
- weights, biases = self.get_fc_var(in_size, out_size, name)
- x = tf.reshape(bottom, [-1, in_size])
- fc = tf.nn.bias_add(tf.matmul(x, weights), biases)
- return fc
- else:
- weights = tf.get_default_graph().get_tensor_by_name(name+'/'+name+'_weights:0')
- biases = tf.get_default_graph().get_tensor_by_name(name+'/'+name+'_biases:0')
- x = tf.reshape(bottom, [-1, in_size])
- fc = tf.nn.bias_add(tf.matmul(x, weights), biases)
- return fc
- def get_conv_var(self, filter_size, in_channels, out_channels, name):
- initial_value = tf.truncated_normal([filter_size, filter_size, in_channels, out_channels], 0.0, 0.001)
- filters = self.get_var(initial_value, name, 0, name + "_filters")
- initial_value = tf.truncated_normal([out_channels], .0, .001)
- biases = self.get_var(initial_value, name, 1, name + "_biases")
- return filters, biases
- def get_fc_var(self, in_size, out_size, name):
- initial_value = tf.truncated_normal([in_size, out_size], 0.0, 0.001)
- weights = self.get_var(initial_value, name, 0, name + "_weights")
- initial_value = tf.truncated_normal([out_size], .0, .001)
- biases = self.get_var(initial_value, name, 1, name + "_biases")
- return weights, biases
- def get_var(self, initial_value, name, idx, var_name):
- if self.data_dict is not None and name in self.data_dict:
- value = self.data_dict[name][idx]
- else:
- value = initial_value
- if self.trainable:
- var = tf.Variable(value, name=var_name)
- else:
- var = tf.constant(value, dtype=tf.float32, name=var_name)
- self.var_dict[(name, idx)] = var
- assert var.get_shape() == initial_value.get_shape()
- return var
- def save_npy(self, sess, npy_path="./vgg16-save.npy"):
- assert isinstance(sess, tf.Session)
- data_dict = {}
- for (name, idx), var in list(self.var_dict.items()):
- var_out = sess.run(var)
- if name not in data_dict:
- data_dict[name] = {}
- data_dict[name][idx] = var_out
- np.save(npy_path, data_dict)
- print(("file saved", npy_path))
- return npy_path
- def get_var_count(self):
- count = 0
- for v in list(self.var_dict.values()):
- count += reduce(lambda x, y: x * y, v.get_shape().as_list())
- return count
2)数据读取代码:
- #coding:utf-8
- import tensorflow as tf
- import numpy as np
- import cv2
- def mydataset(image_root,filename,batch_size,hight,width):
- def get_batches(filename,label):
- '''
- image_string = tf.read_file(filename)
- image_decoded = tf.image.decode_png(image_string)
- '''
- image_resized = tf.image.resize_images(filename, [hight,width])
- image_resized = tf.cast(image_resized,tf.float32)
- return image_resized, label
- def get_files(image_root,filename):
- image_name = []
- labels0 = []
- image_root = image_root + '/'
- for line in open(filename):
- items = line.strip().split(' ')
- image_name.append(image_root+items[0])
- labels0.append(int(items[1]))
- temp = np.array([image_name,labels0])
- temp = temp.transpose()
- np.random.shuffle(temp)
- name_list = list(temp[:,0])
- labels = list(temp[:,1])
- labels_list = [int(i) for i in labels]
- return name_list,labels_list
- def _read_py_function(filename, label):
- filename = filename.decode(encoding='utf-8')
- image_decoded = cv2.imread(filename)
- return image_decoded.astype('float32'), label
- filenames , labels = get_files(image_root,filename)
- dataset = tf.data.Dataset.from_tensor_slices((filenames, labels))
- dataset = dataset.map(lambda filename, label: tf.py_func(_read_py_function, [filename, label], [tf.float32, tf.int32]))
- dataset = dataset.shuffle(buffer_size=1000).batch(batch_size).repeat()
- return dataset
3)训练代码
- # -*- coding: utf-8 -*-
- import tensorflow as tf
- import os
- from datagenerator_dataset import mydataset
- import vgg16_trainable_dataset as vgg16
- BATCH_SIZE_TRAIN = 1
- BATCH_SIZE_VAL = 1
- TRAINING_STEPS = 25001
- IMAGE_SIZE_HEIGHT = 224
- IMAGE_SIZE_WIDTH = 224
- NUM_CHANNELS = 3
- save_model_interval = 4000
- val_interval = 20005
- the_num_of_train_images = 50000
- the_num_of_val_images = 10000
- image_root = 'data_different_size'
- filename = 'train_labels.txt'
- valtxt = 'test_labels.txt'
- inf_log = './log'
- save_model_path = './trainedmodel'
- lr_steps = [ 4000, 8000 ,12000 ,16000 ,20000 ]
- lr_value = [0.01, 0.001, 0.001, 0.0005, 0.0002 ,0.00004]
- def training(loss,lr,global_step):
- train_op = tf.train.GradientDescentOptimizer(lr).minimize(loss, global_step=global_step)
- return train_op
- def Loss(true_labels,pred):
- return tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels = true_labels,logits = pred))
- def get_accuracy(true_labels,pred):
- correct_prediction = tf.equal(true_labels, tf.argmax(pred,1))
- return tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
- def train():
- os.environ["CUDA_VISIBLE_DEVICES"] = "0"
- global_step = tf.get_variable('global_step', [], dtype=tf.int32,initializer=tf.constant_initializer(0), trainable=False)
- learning_rate = tf.train.piecewise_constant(global_step, boundaries=lr_steps, values=lr_value, name='lr_schedule')
- dataset1 = mydataset(image_root,filename,BATCH_SIZE_TRAIN,IMAGE_SIZE_HEIGHT,IMAGE_SIZE_WIDTH)
- iterator1 = dataset1.make_one_shot_iterator()
- batch_data1 = iterator1.get_next()
- dataset2 = mydataset(image_root,filename,BATCH_SIZE_TRAIN,IMAGE_SIZE_HEIGHT,IMAGE_SIZE_WIDTH)
- iterator2 = dataset2.make_one_shot_iterator()
- batch_data2 = iterator2.get_next()
- images1 = tf.placeholder(tf.float32, [None,None,None,NUM_CHANNELS],name='x-input1')
- images2 = tf.placeholder(tf.float32, [None,None,None,NUM_CHANNELS],name='x-input2')
- labels1 = tf.placeholder(tf.int64, [None,], name = 'y-output1')
- labels2 = tf.placeholder(tf.int64, [None,], name = 'y-output2')
- train_mode1 = tf.placeholder(tf.bool,name = 'trainmode1')
- train_mode2 = tf.placeholder(tf.bool,name = 'trainmode2')
- model1 = vgg16.vgg16('vgg16.npy',count=1)
- model2 = vgg16.vgg16('vgg16.npy',count=2)
- model1.build(images1, train_mode1)
- model2.build(images2, train_mode2)
- acc1 = get_accuracy(labels1,model1.pred)
- loss1 = Loss(labels1,model1.pred)
- acc2 = get_accuracy(labels2,model2.pred)
- loss2 = Loss(labels2,model2.pred)
- loss = (loss1+loss2)/2
- acc = (acc1+acc2)/2
- train_op = training((loss1+loss2)/2, learning_rate, global_step)
- config = tf.ConfigProto()
- config.gpu_options.allow_growth = True
- with tf.Session(config=config) as sess:
- tf.global_variables_initializer().run()
- print("begin training...")
- for i in range(TRAINING_STEPS):
- name_list_bathch_train1,labels_list_bathch_train1 = sess.run(batch_data1)
- name_list_bathch_train2,labels_list_bathch_train2 = sess.run(batch_data2)
- my_feed_dict = {}
- my_feed_dict[train_mode1]= True
- my_feed_dict[train_mode2]= True
- my_feed_dict[images1] = name_list_bathch_train1
- my_feed_dict[labels1] = labels_list_bathch_train1
- my_feed_dict[images2] = name_list_bathch_train2
- my_feed_dict[labels2] = labels_list_bathch_train2
- _,LOSS,ACC,num_step,lr = sess.run([train_op,loss,acc,global_step,learning_rate], feed_dict = my_feed_dict)
- print("After %dth training step(s), loss is %f, acc is %f, lr is %f." % (num_step, LOSS,ACC,lr))
- def main(argv=None):
- train()
- if __name__ == '__main__':
- tf.app.run()
特别说明:本文没有理会训练的好不好,搞机器学习的你们都知道,数据加上模型能不能得到好的结果需要好好实验并作分析,本文目的在于使得网络能够批量读取尺度不同的图像进行训练,实验证明,本代码可以正常运行。如果有问题,欢迎共同交流。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









