







摘要
摘要部分介绍了一下层次语义相关性在目前的细粒度识别研究中往往被忽视,这里举了一个例子:鸟类可以根据目、科、属和种的四个层次进行分类。这种层次结构编码了不同级别的不同类别之间的丰富相关性,可以有效地规范语义空间,从而减少预测的模糊性。
在这项工作中,通过开发一种新的层次语义嵌入(HSE)框架,研究同时预测层次结构中不同级别的类别,并将这种结构化的相关信息集成到深度神经网络中。具体而言,HSE框架按顺序预测层次结构中每个级别的类别得分向量,从最高到最低。在每一级,它都将更高级别的预测得分向量作为先验知识,以学习更细粒度的特征表示。在训练过程中,还使用较高级别的预测得分向量作为相应子类别的软目标,对标签预测进行正则化。
1 Introduction
在层次语义结构中,靠近层次结构根的节点指的是更抽象的概念,而靠近叶子的节点指的是更细粒度的概念。例如,鸟类的细粒度分类(鸟类)可以按照目、科、属和种的四级层次进行组织,其中一个目由几个科组成,而一个科由几个属组成,以此类推。这种类别层次结构在不同级别的类别之间提供了非常丰富的语义关联,可以有效地规范语义空间,并提供额外的指导,以关注更微妙的区域,以便更好地识别。
例如,要识别给定对象的细粒度类别(例如鸟的种类),我们可能首先识别其超类(例如属)。然后,我们更倾向于关注受这个超类约束的细粒度类别,并关注在这些细粒度类别中更容易区分的对象部分。
现有的细粒度图像识别(FGIR)方法主要侧重于对一个特定级别的类别进行分类,通常忽略了这种相关性信息。在这项工作中,我们同时预测层次结构中所有级别的类别,并将这种结构化的相关信息集成到深度神经网络中,以逐步正则化标签预测并指导表征学习。为此,我们提出了一个新的分层语义嵌入(HSE)框架,该框架从最高到最低顺序预测每个级别的得分向量。在每一级,它都将更高级别的预测得分向量作为先验知识,以学习更细粒度的特征表示。这是通过语义引导的注意机制实现的,该机制学习专注于更具辨别力的区域,以便更好地辨别。在训练过程中,我们还利用较高级别的预测得分向量作为软目标,对标签预测进行正则化,从而使该级别的预测结果与较高级别的预测结果非常吻合。
实验用到的数据集
Caltech-UCSD鸟类数据集,根据鸟类分类学,有200个鸟类类别,分为13个目,37个科,122个属和200个种四个级别。
创建了一个蝴蝶数据集,由200种常见蝴蝶组成,根据昆虫分类法分为116个属,23亚科和5个科,共25279张图片。
本文的主要贡献
- 提出了一种新的层次语义嵌入(HSE)框架,将类别层次的语义结构信息集成到FGIR的深层神经网络中。据我们所知,这是第一个明确整合这种结构化信息以帮助FGIR的工作。
- 我们为加州理工大学UCSD鸟类数据集[39]引入了一个四级分类层次结构,并构建了一个新的大规模蝴蝶数据集,该数据集还包括四级分类以供评估。据我们所知,这两个数据集是FGIR中第一个涉及四个级别类别的数据集,它们可能有助于多粒度图像识别的研究。
- 我们在这两个数据集和VegFru[14]数据集上进行了实验,并证明了我们提出的HSE框架在基线和现有最先进方法上的有效性。此外,我们还进行了消融研究,以仔细评估和分析框架的每个组成部分的贡献。
2 Related Work
图像分类的最新进展主要得益于深度卷积神经网络(CNN)的发展,该网络通过叠加多个非线性变换学习强大的特征表示。为了使深层CNN适应处理FGIR任务,提出了一个双线性模型[25]来计算高阶图像表示,该模型捕获了由两个独立子网络生成的特征之间的局部成对交互,但双线性特征是非常高维的,因此不适用于后续分析。为了减少特征维数,同时保持FGIR任务的可比性能,Gao等人[9]开发了一个紧凑的模型,用多项式核近似双线性特征。Kong等人[19]提出了分类器共分解,以进一步压缩双线性模型。
为了更好地捕捉子坐标类别之间细微的视觉差异,还提出了一系列工作[16,46,47],以利用对边界框和零件的额外监督来定位有区别的区域。然而,手工注释的大量使用阻碍了这些方法在大规模现实问题中的应用。最近,视觉注意模型[5,26,30,42]被广泛提出,用于自动搜索信息区域,各种工作成功地将该技术应用于FGIR[8,17,28,50]。Liu等人[28]制定了一个强化学习框架,以自适应地瞥见关于区分对象部分的局部区域,并使用带有图像级标签的贪婪奖励策略对该框架进行训练。Zheng等人[50]介绍了一种多注意卷积神经网络,该网络学习用于零件定位的通道分组,并聚合来自定位区域和全局对象的特征进行分类。这些作品学会了通过自我注意机制仅仅基于图像内容来定位信息区域。相比之下,一些作品还引入了额外的指导,学习更有意义和语义相关的区域,以帮助FGIR。例如,Liu等人[2,27]引入了基于部分的属性,以指导学习更具辨别力的特征,从而实现细粒度的鸟类识别。类似地,He等人[12]进一步利用更详细的语言描述来帮助挖掘有区别的部分或特征。
我们的框架还与一些利用类别层次结构的现有作品相关。例如,Srivastava等人[37]在将知识转移到类似较低级别的班级之前,利用了类别层次结构进行转移学习。Jia等人[6]提出了一种基于层次和排除图的概率分类模型,用于捕捉对象分类中互斥、重叠和包容的标签关系。Works[5,41]利用RNN为多标签识别的标签共现依赖性建模。与这些仅对标签空间的依赖关系建模的方法不同,我们的HSE框架引入了层次信息,以逐步规范化标签预测,同时指导学习更细粒度的特征表示。此外,利用高层预测结果作为软目标进行标签正则化,可以将高层学习到的知识提取到较低的层次,这与这些方法相比也是新颖的。
3 HSE Framework
在本节中,我们将详细描述提出的HSE框架。给定一幅图像,该框架首先利用主干网络提取图像特征图,其中
表示特征图的宽度、高度和通道数。然后,它有序地利用一个小的分支网络来预测各个级别的得分向量,从最高到最低。在每个层次上,分支网络将更高层次的预测得分向量作为先验指导,通过软注意机制学习更细粒度的表征,并将该表征与在没有指导的情况下学习的特征聚合,以预测该层次的得分向量。在训练过程中,我们进一步使用更高级别的预测得分向量作为软目标,对标签预测进行正则化,使该级别的预测结果与更高级别的预测结果趋于一致。由于第一级没有指导,我们只使用在没有指导的情况下学习的表示来进行预测,也不涉及标签正则化。图1给出了HSE框架的总体说明。
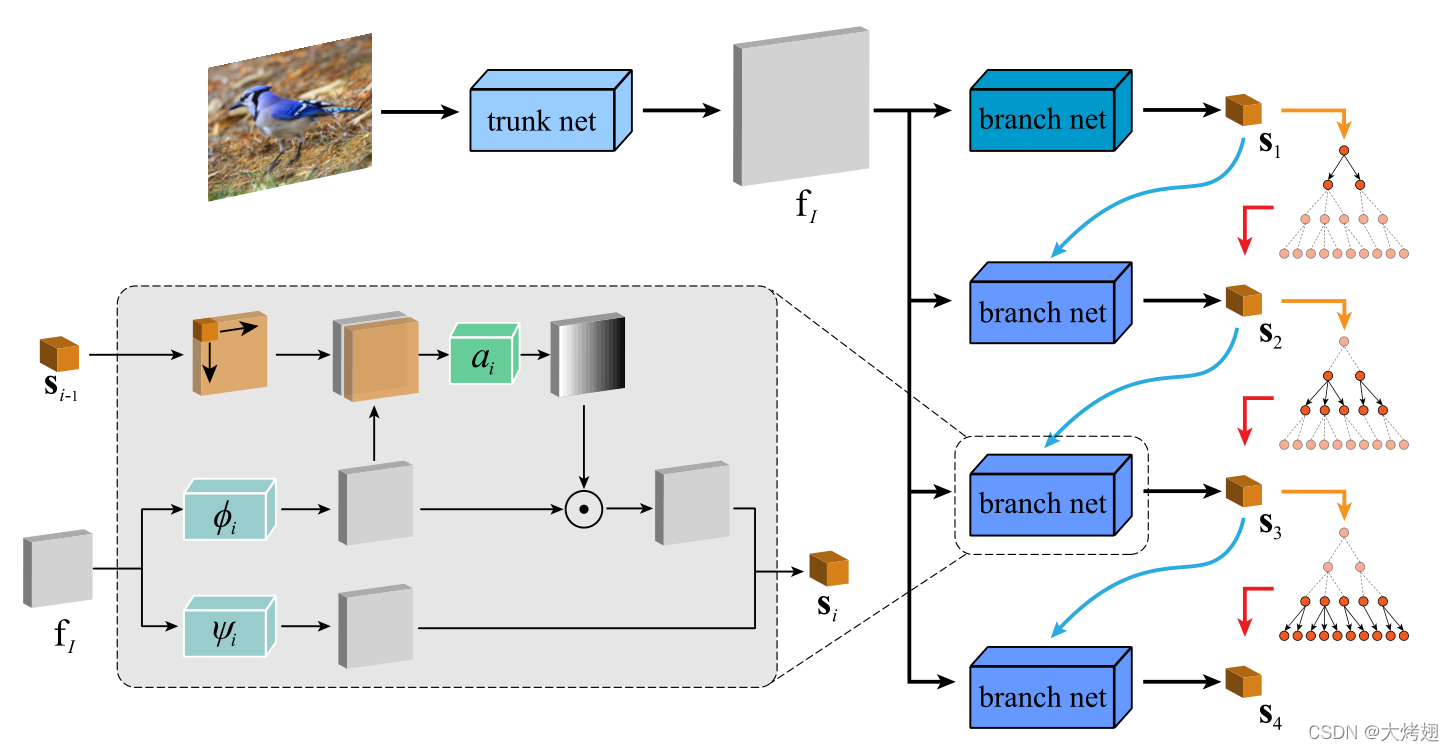
图1.我们提出的分层语义嵌入框架的pipeline。它使用主干网络提取图像特征,然后使用分支网络预测每个级别的类别。在每一个层次上,它结合预测的得分向量来指导学习更细粒度的特征,同时在训练期间对标签预测进行正则化。
在深入研究公式之前,我们首先介绍一些与我们的任务相关的符号,这些符号将在本文中使用。在不损失一般性的情况下,我们考虑了具有L个级别的FGIR任务。我们利用表示每个级别和
表示相应的预测得分向量。
分别用于表示每个级别的类别编号。
3.1 Semantic embedding representation learning
当我们有序地预测每个级别的得分向量时,在层进行预测时
是已知的。概括来说,
对给定图像的对象所属的类别进行编码,这个类别在层级
上概率很高,并在层级
上做出预测,可能倾向于区分该类别的子类别。如上所述,某些特定部分在区分超类的子类别方面起着关键作用。在这项工作中,我们通过合并
来充分利用这些信息指导学习在
级更细粒度的特征表示。
当然,这可以通过一个软机制来实现,该机制在的指导下学习关注具有区分度的区域。
在层,我们首先将特征图
通过以下公式映射到高级特征
:
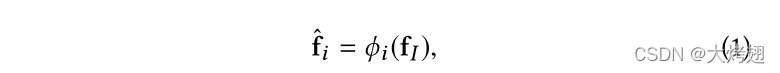
其中是由小型网络实现的转换。然后,在每个位置(w,h),我们引入共享注意机制
,在
的指导下计算注意系数向量:
![]() 其中,
其中,表示特征向量
的每个神经元的重要性。在方程中,
是一个线性变换,它可以变换
到语义特征向量。为了使系数在不同通道之间易于比较,我们使用softmax函数对每个通道c的所有位置的系数进行归一化
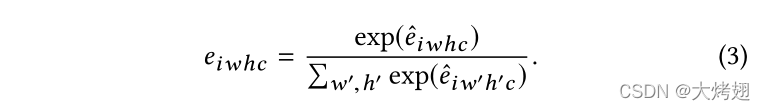
通过这种方式,我们可以得到,表示特征向量
中每个神经元的归一化权重。最后,我们对每个通道的所有位置进行加权平均,以生成最终的细粒度特征.
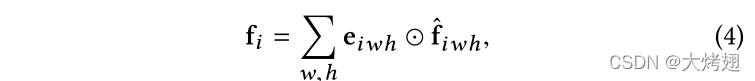
其中表示元素的乘法运算。
由于特征向量非常关注局部具有区分度的区域,这些区域可能倾向于捕捉细微差异以区分超类的子类别。它可能会忽略对象的整体描述和一些可能提供上下文线索的背景信息。因此,我们进一步直接从图像特征图
中提取特征向量,而无需指导互补。同样,我们也采用了
上的一个简单变换
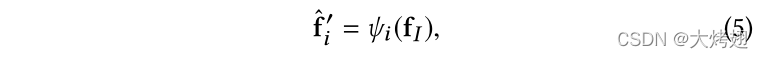
其中,与[11]类似,我们只需执行平均池化来获得特征向量。
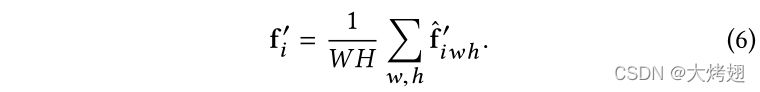
将获得的特征向量,
及其级联
馈送到三个分类器,以独立预测得分向量,然后对其进行平均以产生最终得分向量
。
网络细节
与最近的FGIR工作[27,28]类似,我们基于广泛使用的ResNet-50[11]实现了我们的框架。具体地说,我们用ResNet-50的前41个卷积层实现主干网络,并用ResNet-50剩下的9个层实现,
的变换。为了更好地平衡预测精度和计算效率,我们使主干网络在不同级别上共享参数。
是由一个全连接层实现,该层将c维得分向量映射到1024个维度特征,注意机制
由两个堆叠的全连接层实现,其中第一个层是c+1024到1024,后面是tanh非线性函数,第二个层是1024到c。由于我们使用与ResNet-50相同的架构,在本文中,c是2048。
3.2 Semantic guided label regularization
层次结构编码了不同级别的类别之间丰富的语义关联。例如,级的真实类别是
级的真实类别的子类。这种相关信息可以有效地规范语义空间,从而减少预测的模糊性。在不同级别的预测类别之间也应保持这些相关性。为此,我们加入了
作为软目标,在
水平上规范标签预测。
给定预测得分向量,一个较高值的
表示给定图像中的对象在
级属于c类的高度置信度,并且在
级别对应的子类别的预测分数也应分配比较高的值。为此,我们首先根据结构相关性扩展
至
,因此
的维度与
相同,并将
拉近
,如图2所示。
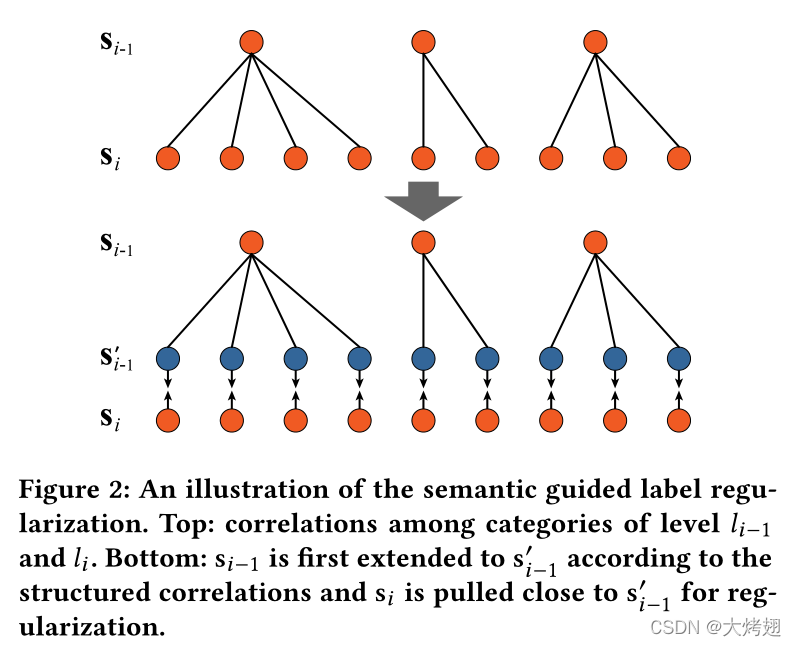
图2.语义引导标签正则化的说明。顶部:层级和
类别之间的相关性。底部:
首先根据结构相关性扩展到
,
接近
用于正则化。
具体地说,如果在层级的类别c在
层有k个子类别,我们将分数
复制k次。然后我们有序地将这些重复的分数集合起来,重新排列它们的下标,以获得扩展的分数向量
。为了使这两个向量易于比较,我们使用温度为T的softmax函数将它们归一化为概率分布。
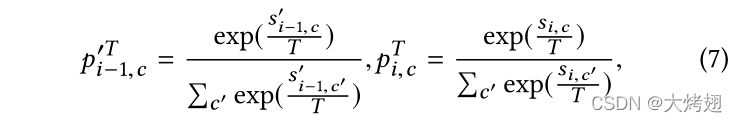
其中T通常设置为1,在我们的实验中,我们使用高温来产生更柔和的概率分布。通过这种方法,我们可以得到两个归一化的概率分布,即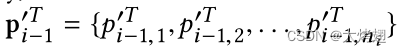
和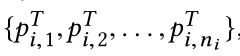 ,并定义一个正则化项,从
,并定义一个正则化项,从到
。
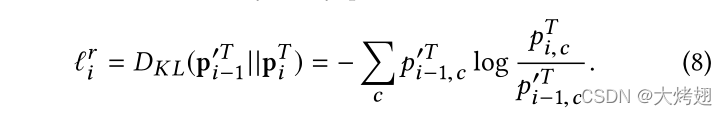
由于是在单个样本上定义的,我们简单地将
在训练集上求和,以定义正则化损失项
。如[13]所述,当使用具有高熵的软目标时,每个训练样本可以提供比硬目标更多的信息,并且训练样本之间的梯度具有更小的方差。因此,它可以更稳定地训练,并且使用更少的训练样本。在我们的实验中,T设置为4,以产生足够软的目标。
3.3 Optimization
除了正则化项外,我们还采用了带有正确标签的交叉熵损失作为目标函数。我们首先使用softmax函数中完全相同的Logit对预测得分向量进行归一化,但在正常温度为1时,表示为\
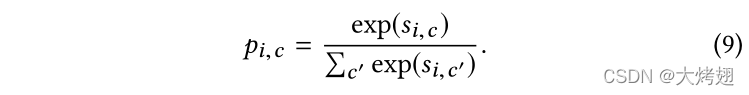 然后假设
然后假设层的ground truth标签是
,其损失可以定义为
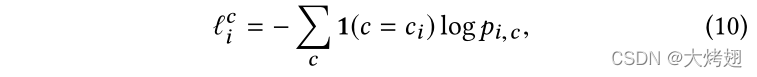
其中1(·)是指示函数,如果表达式为真,则指定为1,否则指定为0。我们分别为三个分类器预测的得分向量定义了相同的损失。因此,每个样本有四个损失,我们将训练集中的四个损失相加,以定义分类损失。该框架由主干网络和L个分支网络组成,并使用分类和正则化损失的加权组合进行训练。根据经验,训练过程分为两个阶段,即层次范围训练,然后进行联合微调。
Stage 1:Level-wise Training
在训练水平li的分支网络时,需要水平li的预测得分向量−1定义正则化损失。因此,我们首先以分层的方式训练分支网络,从l1层到lL层。由于我们的框架是基于ResNet-50[11]实现的,因此我们使用在ImageNet数据集[7]上预训练的相应ResNet-50层的参数初始化参数。具体地说,主干网络的参数由相应的41个卷积层的参数初始化,而转换φi(·)和ψi(·)的参数由相应的9个层的参数初始化。其他模块的参数,包括注意机制ai(·)、语义映射器φi(·)和三个分类器,都是用Xavier算法自动初始化的[10]。由于主干网络由所有分支网络共享,因此在这一阶段其参数保持不变。我们用分类和正则化损失的加权组合来训练李层的分支网络。
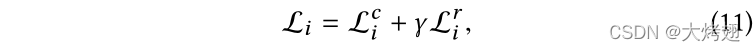
其中γ是一个平衡参数。如[13]所述,Lri产生的梯度大小按1 T 2进行缩放,因此将其乘以T 2非常重要。因此,我们在实验中将γ设为t2,即16。请注意,我们仅使用分类损失Lc1来训练l1级的分支网络,因为没有在该级别定义正则化损失项的指南。与之前关于FGIR任务的工作[25,28]类似,我们将输入图像的大小调整为512×512,并执行448×448大小的随机裁剪及其水平反射,以增强数据。然后,我们使用随机梯度下降(SGD)算法训练分支网络,批量大小为8,动量为0.9,权重衰减为0.00005。初始学习率设置为0.001,误差稳定时除以10。
Stage 2:Joint Fine Tuning
在所有分支网络都经过训练之后,我们通过组合所有粒度上的损失项来联合微调整个框架
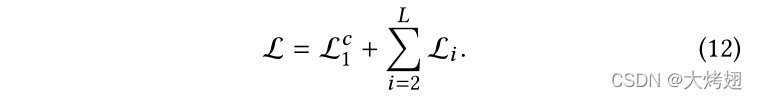 除了使用较小的初始学习率0.0001外,我们采用了与第一阶段相同的数据扩充和超参数设置策略。
除了使用较小的初始学习率0.0001外,我们采用了与第一阶段相同的数据扩充和超参数设置策略。

















 1657
1657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









