





前期文章链接:
霍夫变换——形状特征提取算法:车道线检测
开源自动驾驶汽车数据集
基于深度学习和神经网络的重要基础及方法概要
深度学习背后的数学思想
Tensorflow2实现YOLOv3目标检测
正文:
一、yolo环境搭建教程
本文只做一个简单的入门体验,对于YOLO的安装与配置可参考我的CSDN博客教程:
https://blog.csdn.net/weixin_41194129?spm=1010.2135.3001.5113

YOLO适用于Windows和Linux的Yolo v4,v3和v2请参考以下github文献介绍:https://github.com/AlexeyAB/darknet#how-to-compile-on-linux
二、模型转换
在给出以下测试结果之前,我们需要了解将darknet格式的yolov3的yolov3.cfg和yolov3.weights转换成keras(tensorflow)的h5格式的过程,之所以转化的原因是yolo的darknet是C++编译配置,由于每一次训练都有进行编译C++,为了方便,这里就将darknet转化为keras,并在TensorFlow2.x环境下训练。
转换源码:convert.py
# -*- coding: utf-8 -*-import osimport ioimport argparseimport configparserimport numpy as npfrom keras import backend as Kfrom keras.layers import (Conv2D, Input, ZeroPadding2D, Add, UpSampling2D, MaxPooling2D, Concatenate)from keras.layers.advanced_activations import LeakyReLUfrom keras.layers.normalization import BatchNormalizationfrom keras.models import Modelfrom keras.regularizers import l2from keras.utils.vis_utils import plot_model as plotdef parser(): parser = argparse.ArgumentParser(description="Darknet\'s yolov3.cfg and yolov3.weights \ converted into Keras\'s yolov3.h5!") parser.add_argument('-cfg_path', help='yolov3.cfg') parser.add_argument('-weights_path', help='yolov3.weights') parser.add_argument('-output_path', help='yolov3.h5') parser.add_argument('-weights_only', action='store_true',help='only save weights in yolov3.h5') return parser.parse_args()class WeightLoader(object): def __init__(self,weight_path): self.fhandle = open(weight_path,'rb') self.read_bytes = 0 def parser_buffer(self,shape,dtype='int32',buffer_size=None): self.read_bytes += buffer_size return np.ndarray(shape=shape, dtype=dtype, buffer=self.fhandle.read(buffer_size) ) def head(self): major, minor, revision = self.parser_buffer( shape=(3,), dtype='int32', buffer_size=12) if major*10+minor >= 2 and major < 1000 and minor < 1000: seen = self.parser_buffer( shape=(1,), dtype='int64', buffer_size=8) else: seen = self.parser_buffer( shape=(1,), dtype='int32', buffer_size=4) return major, minor, revision, seen def close(self): self.fhandle.close()class DarkNetParser(object): def __init__(self, cfg_path, weights_path): self.block_gen = self._get_block(cfg_path) self.weight_loader = WeightLoader(weights_path) major, minor, revision, seen = self.weight_loader.head() print('weights header: ',major, minor, revision, seen) self.input_layer = Input(shape=(None, None, 3)) self.out_index = [] self.prev_layer = self.input_layer self.all_layers = [] self.count = [0,0] def _get_block(self,cfg_path): block = {} with open(cfg_path,'r', encoding='utf-8') as fr: for line in fr: line = line.strip() if '[' in line and ']' in line: if block: yield block block = {} block['type'] = line.strip(' []') elif not line or '#' in line: continue else: key,val = line.strip().replace(' ','').split('=') key,val = key.strip(), val.strip() block[key] = val yield block def conv(self, block): '''在读取darknet的yolov3.weights文件时,顺序是 1 - bias; 2 - 如果有bn,则接着读取三个scale,mean,var 3 - 读取权重 ''' # Darknet serializes convolutional weights as: # [bias/beta, [gamma, mean, variance], conv_weights] self.count[0] += 1 # read conv block filters = int(block['filters']) size = int(block['size']) stride = int(block['stride']) pad = int(block['pad']) activation = block['activation'] padding = 'same' if pad == 1 and stride == 1 else 'valid' batch_normalize = 'batch_normalize' in block prev_layer_shape = K.int_shape(self.prev_layer) weights_shape = (size, size, prev_layer_shape[-1], filters) darknet_w_shape = (filters, weights_shape[2], size, size) weights_size = np.product(weights_shape) print('+',self.count[0],'conv2d', 'bn' if batch_normalize else ' ', activation, weights_shape) # 读取滤波器个偏置 conv_bias = self.weight_loader.parser_buffer( shape=(filters,), dtype='float32', buffer_size=filters*4) # 如果有bn,则接着读取滤波器个scale,mean,var if batch_normalize: bn_weight_list = self.bn(filters, conv_bias) # 读取权重 conv_weights = self.weight_loader.parser_buffer( shape=darknet_w_shape, dtype='float32', buffer_size=weights_size*4) # DarkNet conv_weights are serialized Caffe-style: # (out_dim, in_dim, height, width) # We would like to set these to Tensorflow order: # (height, width, in_dim, out_dim) conv_weights = np.transpose(conv_weights, [2, 3, 1, 0]) conv_weights = [conv_weights] if batch_normalize else \ [conv_weights, conv_bias] act_fn = None if activation == 'leaky': pass elif activation != 'linear': raise if stride > 1: self.prev_layer = ZeroPadding2D(((1,0),(1,0)))(self.prev_layer) conv_layer = (Conv2D( filters, (size, size), strides=(stride, stride), kernel_regularizer=l2(self.weight_decay), use_bias=not batch_normalize, weights=conv_weights, activation=act_fn, padding=padding))(self.prev_layer) if batch_normalize: conv_layer = BatchNormalization(weights=bn_weight_list)(conv_layer) self.prev_layer = conv_layer if activation == 'linear': self.all_layers.append(self.prev_layer) elif activation == 'leaky': act_layer = LeakyReLU(alpha=0.1)(self.prev_layer) self.prev_layer = act_layer self.all_layers.append(act_layer) def bn(self,filters,conv_bias): '''bn有4个参数,分别是bias,scale,mean,var, 其中bias已经读取完毕,这里读取剩下三个,scale,mean,var ''' bn_weights = self.weight_loader.parser_buffer( shape=(3,filters), dtype='float32', buffer_size=(filters*3)*4) # scale, bias, mean,var bn_weight_list = [bn_weights[0], conv_bias, bn_weights[1], bn_weights[2] ] return bn_weight_list def maxpool(self,block): size = int(block['size']) stride = int(block['stride']) maxpool_layer = MaxPooling2D(pool_size=(size,size), strides=(stride,stride), padding='same')(self.prev_layer) self.all_layers.append(maxpool_layer) self.prev_layer = maxpool_layer def shortcut(self,block): index = int(block['from']) activation = block['activation'] assert activation == 'linear', 'Only linear activation supported.' shortcut_layer = Add()([self.all_layers[index],self.prev_layer]) self.all_layers.append(shortcut_layer) self.prev_layer = shortcut_layer def route(self,block): layers_ids = block['layers'] ids = [int(i) for i in layers_ids.split(',')] layers = [self.all_layers[i] for i in ids] if len(layers) > 1: print('Concatenating route layers:', layers) concatenate_layer = Concatenate()(layers) self.all_layers.append(concatenate_layer) self.prev_layer = concatenate_layer else: skip_layer = layers[0] self.all_layers.append(skip_layer) self.prev_layer = skip_layer def upsample(self,block): stride = int(block['stride']) assert stride == 2, 'Only stride=2 supported.' upsample_layer = UpSampling2D(stride)(self.prev_layer) self.all_layers.append(upsample_layer) self.prev_layer = self.all_layers[-1] def yolo(self,block): self.out_index.append(len(self.all_layers)-1) self.all_layers.append(None) self.prev_layer = self.all_layers[-1] def net(self, block): self.weight_decay = block['decay'] def create_and_save(self,weights_only,output_path): if len(self.out_index) == 0: self.out_index.append( len(self.all_layers)-1 ) output_layers = [self.all_layers[i] for i in self.out_index] model = Model(inputs=self.input_layer, outputs=output_layers) print(model.summary()) if weights_only: model.save_weights(output_path) print('Saved Keras weights to {}'.format(output_path)) else: model.save(output_path) print('Saved Keras model to {}'.format(output_path)) def close(self): self.weight_loader.close()def main(): args = parser() print('loading weights...') cfg_parser = DarkNetParser(args.cfg_path,args.weights_path) print('creating keras model...') layers_fun = {'convolutional':cfg_parser.conv, 'net':cfg_parser.net, 'yolo':cfg_parser.yolo, 'route':cfg_parser.route, 'upsample':cfg_parser.upsample, 'maxpool':cfg_parser.maxpool, 'shortcut':cfg_parser.shortcut } print('Parsing Darknet config.') for ind,block in enumerate(cfg_parser.block_gen): type = block['type'] layers_fun[type](block) cfg_parser.create_and_save(args.weights_only, args.output_path) cfg_parser.close()if __name__ == '__main__': main()终端执行命令:如果报错会在data文件夹中生成训练模型h5
python yolov3_darknet_to_keras.py -cfg_path text.cfg -weights_path yolov3.weights -output_path yolov3c_d2k.h5
三、yolo_video.py的用法:
usage: yolo_video.py [-h] [--model MODEL] [--anchors ANCHORS] [--classes CLASSES] [--gpu_num GPU_NUM] [--image] [--input] [--output]positional arguments: --input Video input path --output Video output pathoptional arguments: -h, --help show this help message and exit --model MODEL path to model weight file, default model_data/yolo.h5 --anchors ANCHORS path to anchor definitions, default model_data/yolo_anchors.txt --classes CLASSES path to class definitions, default model_data/coco_classes.txt --gpu_num GPU_NUM Number of GPU to use, default 1 --image Image detection mode, will ignore all positional arguments下面开始训练环节
四、环境要求
tensorflow-gpu keras pycharm五、快速训练
0、测试照片:存放在yolo目录下即可,并命令为bjcar.jpg

1、下载yolov3代码:https://github.com/qqwweee/keras-yolo3 ,并解压缩之后用pycharm打开。
2、下载权重:https://pjreddie.com/media/files/yolov3.weights并将权重放在keras-yolo3的文件夹下。如下图所示:
3、执行如下命令将darknet下的yolov3配置文件转换成keras适用的h5文件。
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5
4、运行预测图像程序
python yolo.pypython yolo_video.py --image输入需要预测的图片路径即可,结果示例如下:
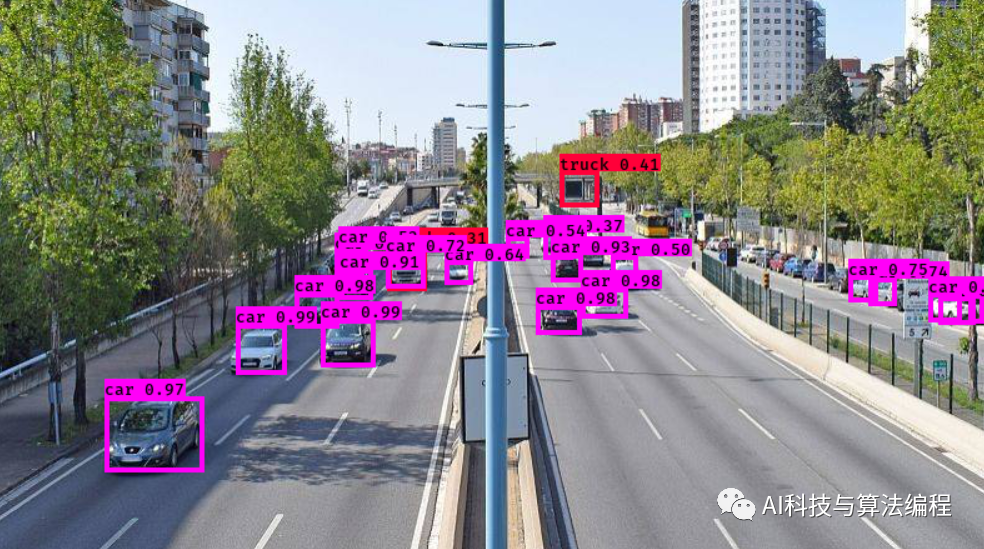
六、数据集:http://host.robots.ox.ac.uk/pascal/VOC/voc2007/
以下数据集下一次开始讲解并训练

类似地,我们可以找一个照片来训练一下:
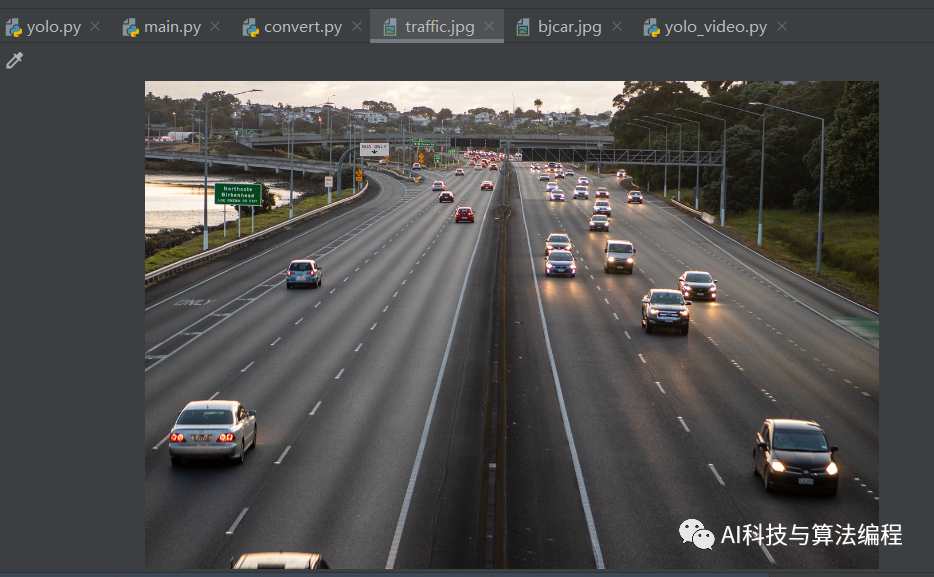
执行结果:

喜欢我的文章请点赞或转发,后续会推送更多有用的技术!















 5777
5777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









