







目录
环境:
WIN10 + vs2015 + python3.6 + YOLOV3 + GPU训练
一、数据集准备
这里有DETRAC数据集的包,用到的是其中的DETRAC-train-data及DETRAC-Train-Annotations-XML包。
链接:https://pan.baidu.com/s/1WE4jUbP9UoH7w3dghzDDWA 提取码:oc8t
使用的数据集为DETRAC,此数据集来自北京和天津不同的24个区域道路的监控中的截取,为车辆的俯拍,与本项目的应用场景相吻合。
1. 首先,这个数据集为每个文件夹中的图片提供了一个xml文件,不需要自己再进行手动标识,但是需要将xml文件分成对应每个图片的xml,这里参考的是https://blog.csdn.net/w5688414/article/details/78931910博客,博主也在自己的博客中给出了GitHub源码。
DETRAC_xmlParser.py这个文件与xml文件夹放在同一路径下就可以自动转换了,最终会在同一目录下生成xml_test文件夹,里面存放的是每个图片对应的xml文件。
2.这个数据集一个train文件夹下的图片有几万张,这对我自己的项目来说太大了,所以我删减了一部分,剩下了六千多张图片。然后执行voc_data_migrate.py,将删减后的六千多张图片转移到同一文件夹下。同样,py文件与Insight-MVT_Annotation_Train文件夹在同一目录下,最终生成picture_test文件夹,里面含有六千多张图片。
3.为了让xml文件及图片文件对应起来,又删减了一遍xml文件。到此为止,已经有xml文件夹及图片文件夹了,接下来要做的工作就是将xml文件转换成YOLOv3规定的txt文件就大功告成了。网上有很多将xml文件转成txt的python文件。并且会同时生成下面训练时需要使用的train.txt文件(也可以同时生成test.txt)。
# -*- coding: utf-8 -*-
"""
Created on Tue Apr 23 16:31:07 2019
@author: lenovo
"""
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
classes = ["car"]
#myRoot = r'E:\python\spyder'
xmlRoot = r'data\xml_test'
txtRoot = r'labels'
imageRoot = r'data\picture_tain'
#imageRoot = r'data\picture_test'
def getFile_name(file_dir):
L=[]
for root, dirs, files in os.walk(file_dir):
print(files)
for file in files:
if os.path.splitext(file)[1] == '.jpg':
L.append(os.path.splitext(file)[0]) #L.append(os.path.join(root, file))
return L
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open(xmlRoot + '\\%s.xml' % (image_id))
out_file = open(txtRoot + '\\%s.txt' % (image_id), 'w'
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
#image_ids_train = open('D:/darknet-master/scripts/VOCdevkit/voc/list.txt').read().strip().split('\',\''image_ids_train = getFile_name(imageRoot)
list_file_train = open(r'train.txt', 'w')
#list_file_train = open(r'test.txt', 'w')
#list_file_val = open('boat_val.txt', 'w')
for image_id in image_ids_train:
list_file_train.write(imageRoot + '\\%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file_train.close()
# for image_id in image_ids_val:
# list_file_val.write('/home/*****/darknet/boat_detect/images/%s.jpg\n'%(image_id))
# convert_annotation(image_id)
# list_file_val.close()
最后按照链接里给出的步骤对将txt文件及图片文件放在同一个文件夹内就可以进行YOLO的训练啦。
二、配置文件的修改及训练
从这一部分开始,根据大神的方法。
https://github.com/AlexeyAB/darknet#how-to-train-to-detect-your-custom-objects
1.修改需要用到的数据集,比如我用到的是YOLOv3.cfg,那么我将YOLOv3.cfg另存为yolov3-car.cfg,再修改里面的内容:

我的GPU显存是小于4G的,因此要将subdivision调大,subdivision是指将batch分成多少份进行运算,如果我的batch是64的话,subdivision必须也是64,才不会报错,但是我发现分别设成32、32要比64、64迭代的快一些,具体原因我还不太清楚,实践出真知。
2.修改car.name,只有一个类别就是car
3.修改car.data中的内容

4.将刚才我们生成的txt及图片放在同一个文件夹下,并将这个文件夹data文件夹下。
5.将上面最后一步生成的train.txt文件放入data文件夹下。
6.在官网上下载链接:https://pjreddie.com/media/files/darknet53.conv.74
然后执行命令darknet.exe detector train data/car.data yolov3-car.cfg darknet53.conv.74
YOLO训练数据集是可以分段的,YOLO会每一百次更新一次训练的weights文件,每一千次保存一个weights文件,如下图的说明:

最后我的数据集还正在训练,我电脑的GPU真的太差劲了,上一次测试是迭代900次的时候,已经呈现了一个不错的效果。
下图是900次到1400左右迭代的loss图像

IOU:代表预测的矩形框和真实目标的交集与并集之比;
class:标注物体分类的正确率,期望该值趋近于1;
Obj:越接近1越好;
No Obj:越接近0越好。
.5R: 1.000000: 是在 recall/count 中定义的, 是当前模型在所有 subdivision 图片中检测出的正样本与实际的正样本的比值;
0.75R: 以IOU=0.75为阈值时候的recall;
count:正样本数目。
三、训练结果检验
经过大约两三天的训练…GPU实在是不给力,最后的训练次数达到2500次,因为只有一个类别,所以两千次已经足够了。
1.什么时候停止训练
官方给出的是,average loss在0.05~3之间,0.05是相对来说小模型而且简单的数据集(for a small model and easy dataset),3是较大模型并且复杂的数据集 (for a big model and a difficult dataset)。非常简单的特性,就是发现avg loss在很多代中不再下降了,就可以停止训练了。
最后我训练的数据集的avg loss在0.7~1之间波动,第二条会讲怎么挑选最合适的weights文件。
贴两张我自己的训练时的average loss chart图:
第一张是900~1700次的迭代,第二张是1700~2500次。前900次收敛较快,但是我忘记调max_batch了,所以都几乎挤在一条线上看不出来趋势。


2.并不是迭代次数越多越好,也不是avg loss越低越好。
官方的说法如下,训练次数过多可能会出现过拟合的现象:可以在train数据集中检测到物体,但是在其他的数据集中效果会降低。
For example, you stopped training after 9000 iterations, but the best result can give one of previous weights (7000, 8000, 9000). It can happen due to overfitting. Overfitting - is case when you can detect objects on images from training-dataset, but can't detect objects on any others images. You should get weights from Early Stopping Point:
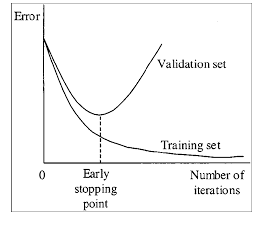
3.选择一个效果最好的weights文件。
在训练过程中得到了三个weights文件,如下,迭代次数大小关系为1000<2000<last。
分别使用三个命令行进行测试:
- darknet.exe detector map data/car.data yolov3-car.cfg backup\yolo-car_1000.weights
- darknet.exe detector map data/car.data yolov3-car.cfg backup\yolo-car_2000.weights
- darknet.exe detector map data/car.data yolov3-car.cfg backup\yolo-car_last.weights
yolo-car_1000.weights:

yolo-car_2000.weights:

yolo-car_last.weights:

比较一下就能发现三个权重文件的avg precision及avg IoU的关系都是 1000<last<2000,可以得出在这三个文件中yolo-car_2000.weights是最佳的权重文件,而不是迭代次数最多的last文件。
4.最后来检测一下识别效果,我是视频识别,视频中的图片不包含在数据集中,截取了其中的一帧,效果还是不错的。

OK!到此为止训练全部结束!可以愉快的使用在自己的项目中啦~
由于车辆数据集是俯视角度,所以最好是使用在这种监控视频中进行识别。
参照博客:
https://blog.csdn.net/weixin_38106878/article/details/88684280
https://blog.csdn.net/w5688414/article/details/78931910
https://github.com/AlexeyAB/darknet#how-to-train-to-detect-your-custom-objects















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









