






本文概要
本文主要讨论Kafka新版本reblance机制的优缺点,通过这篇文章,你可以了解到以下内容:
- 什么是Reblance
- Reblance过程
- Kafka1.1对Reblance的优化
- Kafka2.3对Reblance的优化
- 新版本Reblance存在的问题
什么是Reblance
- Reblance是Kafka协调者把partition分配给Consumer-group下每个consumer实例的过程
- 在执行Reblance期间,Group内的所有Consumer无法消费消息。因此频繁的Reblance会降低消费系统的TPS。
通常在以下情况,会出发Reblance:
-
- 组订阅topic数变更
- topic partition数变更
- consumer成员变更
- consumer 加入群组或者离开群组的时候
- consumer被检测为崩溃的时候
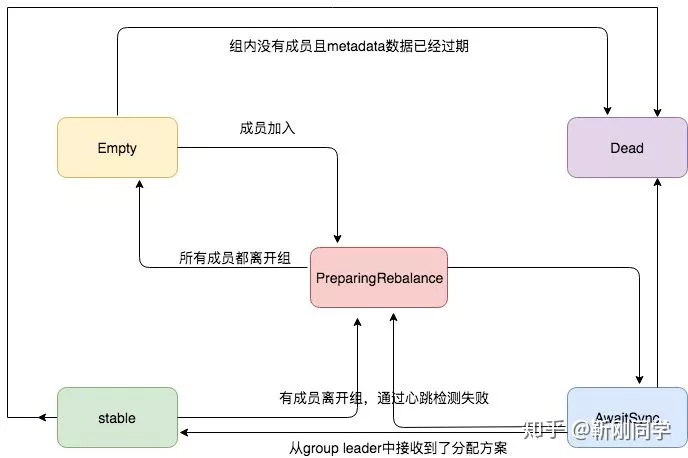
Reblance过程
Kafka Reblance是通过协调者Coordnator实现的:
- consumer通过fetch线程拉消息(单线程)
- consumer通过心跳线程来与broker发送心跳。超时会认为挂掉
- 每个consumer group在broker上都有一个coordnator来管理,消费者加入和退
如果心跳线程在timeout时间内没和broker发送心跳,coordnator会认为该group应该进行reblance。接下来其他consumer发来fetch请求后,coordnator将回复它们进行reblance准备。当consumer成员收到请求后,发送response给coordnator。其中只有leader的response中才包含分配策略。在consumer的下次请求到来时,coordnator会把分配策略同步给各consumer
存在的问题
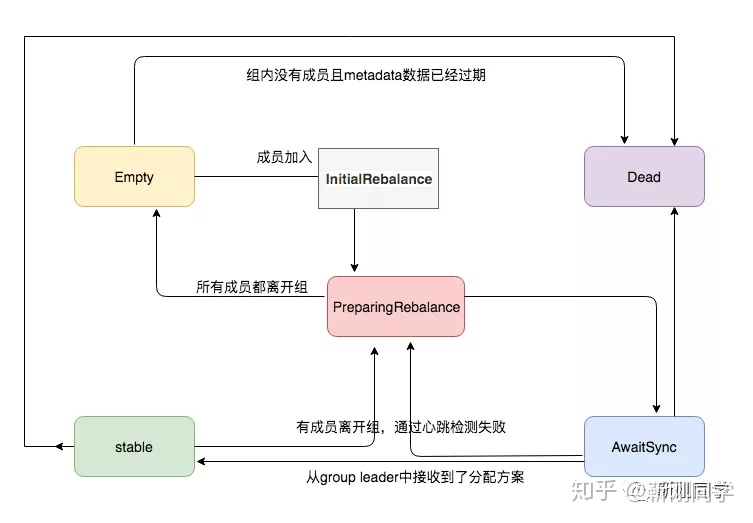
在大型系统中,一个topic可能对应数百个consumer实例。这些consumer陆续加入到一个空消费组将导致多次的rebalance;此外consumer 实例启动的时间不可控,很有可能超出coordinator确定的rebalance timeout(即max.poll.interval.ms),将会再次触发rebalance,而每次rebalance的代价又相当地大,因为很多状态都需要在rebalance前被持久化,而在rebalance后被重新初始化。Kafka 1.1对reblance的优化通过延迟进入PreparingRebalance状态减少reblance次数
我们系统的一个Group通常包含成百consumer,为防止服务启动时,这些consumer不断加入引起频繁的reblance,Kafka新增了延迟reblance机制。即从初始状态到准备Reblance前,先进入InitialReblance状态,等待一段时间(group.initial.rebalance.delay.ms)让其他consumer到来后再一起执行reblance,从而降低其频率。
Kafka2.3对reblance的优化
以上解决了服务启动时,consumer陆续加入引起的频繁Reblance,但对于运行过程中,consumer超时或重启引起的reblance则无法避免,其中一个原因就是,consumer重启后,它的身份标识会变。简单说就是Kafka不确认新加入的consumer是否是之前挂掉的那个。
在Kafka2.0中引入了静态成员ID,使得consumer重新加入时,可以保持旧的标识,这样Kafka就知道之前挂掉的consumer又恢复了,从而不需要Reblance。这样做的好处有两个:
- 降低了Kafka Reblance的频率
- 即使发生Reblance,Kafka尽量让其他consumer保持原有的partition,减少了重分配引来的耗时、幂等等问题
新版reblance使用时存在的问题
目前系统把每个上游的业务线抽象成一个topic,假设他们partition分别是10、20、40、80,我们的80台机器往往是分批次灰度发布。这样全量发布完,只有80个partition的topic才会被每台机器所占有,而其他topic的partition只能被先启动的那批consumer抢占到,这样就造成了分配不均匀;由于粘性reblance的存在,下次reblance,大部分consumer依旧占有之前partition,就造成了长久的分配不均匀。之前想过,配置每台机器启动那部分topic的consumer,但会强依赖IP,在容器化的趋势下,显然是不划算的。长按订阅更多精彩▼

如有收获,点个在看,诚挚感谢















 890
890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









