





在日常开发中,无实时性或密集型计算,python基本满足需求。但对于一些计算有时间要求或密集地计算时,python执行速度相比其他以性能著称的语言来说,是一件非常糟糕的事情。
C++在计算上的性能是非常不错的,能不能在密集计算上,使用C++,而其他操作,仍然是python,如果能在python上直接写出代码,然后编译成C++,那么就更好了,由此cython应用而生。cython只能用于cpu密集计算,对于IO型操作,起作用基本为零。
以下所有示例均来自于Cython的官方文档
Welcome to Cython’s Documentationdocs.cython.org此文章需要对Cython有最基本的了解,如:如何编译及编译基本逻辑,Cython文件名后缀;
一、使用 .pyx 文件名后缀加速
只要是 .py 文件均直接编译为C、C++,但每个变量有声明,将大大提升运行速度
若需要调用 C、C++库,则需要安装C、C++编译器;
#test.py
def f(x):
return x ** 2 - x
def integrate_f(a, b, N):
s = 0
dx = (b - a) / N
for i in range(N):
s += f(a + i * dx)
return s * dx以上脚本系python代码,编译后,计算速度将提升35%,但对一些变量做静态类声明,那么计算速度将提升原来的4倍,脚本如下:
#test.pyx
def f(double x):
return x ** 2 - x
def integrate_f(double a, double b, int N):
cdef int i
cdef double s, dx
s = 0
dx = (b - a) / N
for i in range(N):
s += f(a + i * dx)
return s * dx做类别声明,脚本后缀名是:.pyx
示例来源:Faster code via static typing
详细的性能提升,请看:Working with NumPy 和 Cython for NumPy users,这两个链接,对于不同格式、声明等有详细的性能对比,里面有不明白的点,不用担心,你可以返回回来继续看下面的内容或着自己查阅资料,如果你把 Cython 文档都看完,就可以发现,我只是一个搬运工;
二、修改sklearn的setup.py文件进行编译
将 .py 或 .pyx 脚本编译为 C 或 C++,方式多种多样,但不管哪种方式,最终 windows 编译为 .pyd 文件,linux 或 mac 编译为 .so 文件。本人比较喜欢采用 sklearn 的编译格式,就是拿 sklearn 编译脚本做修改(思路来源于faster-rcnn源码),这样做的目的是,脚本风格与大佬风格接近,便于分享等
编译脚本 setup.py 修改于 scikit-learn,如下:
from __future__ import division, print_function, absolute_import
import os
from os.path import join
import warnings
import os.path as osp
import sys
#以下有注释的,可根据实际业务做修改
def add_path(path):
if path not in sys.path:
sys.path.insert(0, path)
this_dir = osp.dirname(__file__)
previous_path = osp.join(this_dir, '..')
add_path(path=previous_path)
DEFAULT_ROOT = 'name' #当前文件夹名称
# on conda, this is the latest for python 3.5
CYTHON_MIN_VERSION = '0.28.5' #编译版本
from lib.algorithm._build_utils import get_blas_info
from lib.algorithm._build_utils import maybe_cythonize_extensions
def configuration(parent_package='', top_path=None):
from numpy.distutils.misc_util import Configuration
from numpy.distutils.system_info import get_info, BlasNotFoundError
import numpy
#默认即可
cblas_libs, blas_info = get_blas_info()
config = Configuration('', parent_package, top_path)
libraries = []
if os.name == 'posix':
cblas_libs.append('m')
libraries.append('m')
#只需要把sklearn源码中以下的两个文件夹复制到需要编译的目录
config.add_subpackage('__check_build')
config.add_subpackage('_build_utils')
config.add_extension('dist_metrics',
sources=['test.pyx'], #需要编译的脚本
include_dirs=[numpy.get_include(),
os.path.join(numpy.get_include(),
'numpy')],
libraries=libraries,
# language="c++", #编译默认 C,如需要编译C++,则需要指定
)
config.add_extension('typedefs',
sources=['typedefs.pyx'],
include_dirs=[numpy.get_include()],
libraries=libraries,
# language="c++",
)
#以下默认即可
blas_info = get_info('blas_opt', 0)
if (not blas_info) or (
('NO_ATLAS_INFO', 1) in blas_info.get('define_macros', [])):
config.add_library('cblas',
sources=[join('src', 'cblas', '*.c')])
warnings.warn(BlasNotFoundError.__doc__)
maybe_cythonize_extensions(top_path, config)
return config
if __name__ == '__main__':
from numpy.distutils.core import setup
setup(**configuration(top_path='').todict())将python脚本编译为 C 或 C++,流程很简单,但坑很大,总结有如下几点:
- 变量声明错误,导致编译失败,这种谁也救不了自己,只能先从简单开始一步一步达到自己的需求;
- 当编译完成后速度提升不明显,可能对Cython了解还不深,无法实现复杂的逻辑,那么先减需求,在Cython层减少复杂的计算,在后续的项目中逐渐加深应用;
- 实现复杂的业务逻辑,尽量修改已有框架,如,本人经常修改sklearn中的源码来实现业务需求;
- 修改现有框架,需注意的是,人家编译为C文件,在你修改时候增加了import C++库或 函数,是无法编译成功的,但可以把整个C文件修改为C++风格吗?答案不可能,不然就不会去修改现有框架,所以这一点需要注意;
- 修改现有框架,最大的优势是,脚本整体上是优的,根据业务需求,做一些增删,性能可能会比numpy直接调用优很多,甚至与C++大佬脚本性能媲美,因为去除了中间一些非业务需要的操作,详看:Cython for NumPy users;
- 在修改现有框架,可能要安装C、C++编译器,本人这一块未作深入研究,在windows安装了VIsual Studio Community就一劳永逸了,Linux或mac系统则无此问题;
- 若对 Cython 感兴趣的朋友,强烈建议把 Cython的官方文档 看一遍,并不难,大约80%的内容浅显易懂;
- Cython 无需研究过深,因为其对职业发展加分并不多,若业务有大量实时密集型计算,可以尝试学习 C++ 等在计算非常有优势的语言,笔者所在小组均已经在学习并应用C++;
sklearn版本迭代较快,本人使用的是早起版本,最近在完善此文档时,发现最近版本sklearn的setup.py有较大的变化,如果你对cython编译有个基本的了解,那么修改也是没难度的;
三、增加同名后缀为 .pxd 的文件来加速计算
Cython可将 pyx、py 编译为 C, C++,若扩充一个.pxd类型声明文件,名字与.pyx 或 .py 相同,将大大提高编译函数运行性能,示例如下:
test.pyx
test.pxd test.pyx:核心计算脚本;test.pyd:是test.pyx 文件中的一些变量、函数声明,.pyx, .pyd 本质和C++的 .cpp、.hpp 文件是一样的,只是 .pyx, .pyd 声明风格是 Cython;
.pyd 可以看成是计算实现加速的声明文件,先声明好一些变量、函数,那么计算就无需做额外的判断等,直接进行计算;
示例:如果有个需要编译的文件 test.py
def myfunction(x, y=2):
a = x - y
return a + x * y
def _helper(a):
return a + 1
class A:
def __init__(self, b=0):
self.a = 3
self.b = b
def foo(self, x):
print(x + _helper(1.0))同目录下增加一个 test.pxd
cpdef int myfunction(int x, int y=*)
cdef double _helper(double a)
cdef class A:
cdef public int a, b
cpdef foo(self, double x)无需import,直接可使用
Python可见函数签名(即变量被指定了值)必须声明为cpdef(默认参数替换为*以避免重复):
cpdef int myfunction(int x, int y=*)- 内部函数的C函数签名可以声明为cdef:
cdef double _helper(double a)本例子来自于: Augmenting .pxd,讲述的点很多,无需做过深入的研究,过深研究就成开发者了;
这也就是为什么推荐修改 sklearn的setup.py文件进行编译,因为sklearn是经典机器学习包,包含算法核心计算模块很多是用Cython(部分直接是 C、C++)编译完成;
四、修改sklearn算法Cython模块
使用Cython来编译,主要目的就是为了加速计算,何不修改一些开源包的对应的Cython模块;
在 GitHub 下载 sklearn,把相对应的模块复制到自己项目对应目录之下,接下来举两个实例,修改 距离函数 和 dbscan 算法;
(一)、修改距离函数
sklearn距离函数罗列了绝大部分的距离计算函数,开箱即用,很方便;
# metric mappings
# These map from metric id strings to class names
METRIC_MAPPING = {'euclidean': EuclideanDistance,
'l2': EuclideanDistance,
'minkowski': MinkowskiDistance,
'p': MinkowskiDistance,
'manhattan': ManhattanDistance,
'cityblock': ManhattanDistance,
'l1': ManhattanDistance,
'chebyshev': ChebyshevDistance,
'infinity': ChebyshevDistance,
'seuclidean': SEuclideanDistance,
'mahalanobis': MahalanobisDistance,
'wminkowski': WMinkowskiDistance,
'hamming': HammingDistance,
'canberra': CanberraDistance,
'braycurtis': BrayCurtisDistance,
'matching': MatchingDistance,
'jaccard': JaccardDistance,
'dice': DiceDistance,
'kulsinski': KulsinskiDistance,
'rogerstanimoto': RogersTanimotoDistance,
'russellrao': RussellRaoDistance,
'sokalmichener': SokalMichenerDistance,
'sokalsneath': SokalSneathDistance,
'haversine': HaversineDistance,
'pyfunc': PyFuncDistance}直接调用也很简单,例如计算经纬度数组之间的距离,如下:
from sklearn.neighbors import DistanceMetric
haversine = DistanceMetric.get_metric('haversine')
r = 6371008.7714 #地球半径
points = [[-115.1722053039234, 36.11955221409178],
[-115.1721313078572, 36.11877300592508],
[-115.1718530355559, 36.11893568847024],
[-115.1707093194468, 36.11910033468673],
[-115.1707551475009, 36.11908843720018]]
print(np.round(haversine.pairwise(points * r, 3))
'''
[[ 0. 2443.506 2938.334 9631.558 9348.245]
[2443.506 0. 1842.144 9115.164 8820.947]
[2938.334 1842.144 0. 7304.159 7010.378]
[9631.558 9115.164 7304.159 0. 294.245]
[9348.245 8820.947 7010.378 294.245 0. ]]
'''计算距离算是比较密集的计算,如果需要根据实际需要调整,将 sklearn/neighbors/_dist_metrics.pyx 文件拷贝出来进行修改,不但可以满足自己需要,计算速度也不输原版速度;
_dist_metrics.pyd 一些变量和函数的基本声明
a. 在变量声明脚本中插入自己的距离函数的基本声明
#欧式距离函数声明,并实现了一些基本计算
#DTYPE_t, ITYPE_t 等来自于同目录下的typedefs.pyx文件声明
cdef inline DTYPE_t euclidean_dist(DTYPE_t* x1, DTYPE_t* x2,
ITYPE_t size) nogil except -1:
cdef DTYPE_t tmp, d=0
cdef np.intp_t j
for j in range(size):
tmp = x1[j] - x2[j]
d += tmp * tmp
return sqrt(d)
cdef inline DTYPE_t euclidean_rdist(DTYPE_t* x1, DTYPE_t* x2,
ITYPE_t size) nogil except -1:
cdef DTYPE_t tmp, d=0
cdef np.intp_t j
for j in range(size):
tmp = x1[j] - x2[j]
d += tmp * tmp
return d
cdef inline DTYPE_t euclidean_dist_to_rdist(DTYPE_t dist) nogil except -1:
return dist * dist
cdef inline DTYPE_t euclidean_rdist_to_dist(DTYPE_t dist) nogil except -1:
return sqrt(dist)
#距离类声明,还未实现
cdef class DistanceMetric:
cdef DTYPE_t p
#cdef DTYPE_t[::1] vec
#cdef DTYPE_t[:, ::1] mat
cdef np.ndarray vec
cdef np.ndarray mat
cdef DTYPE_t* vec_ptr
cdef DTYPE_t* mat_ptr
cdef ITYPE_t size
cdef object func
cdef object kwargs
cdef DTYPE_t dist(self, DTYPE_t* x1, DTYPE_t* x2,
ITYPE_t size) nogil except -1
cdef DTYPE_t rdist(self, DTYPE_t* x1, DTYPE_t* x2,
ITYPE_t size) nogil except -1
cdef int pdist(self, DTYPE_t[:, ::1] X, DTYPE_t[:, ::1] D) except -1
cdef int cdist(self, DTYPE_t[:, ::1] X, DTYPE_t[:, ::1] Y,
DTYPE_t[:, ::1] D) except -1
### -*- 我自己的代码, start. ###
#自己插入的代码
cdef int hdist(self, DTYPE_t[:, ::1] X, DTYPE_t[:, ::1] D,
DTYPE_t outerRadius, DTYPE_t innerRadius) except -1
### -*- 我自己的代码, end. ###
cdef DTYPE_t _rdist_to_dist(self, DTYPE_t rdist) nogil except -1
cdef DTYPE_t _dist_to_rdist(self, DTYPE_t dist) nogil except -1- 声明的变量和函数是非常简单的,按其格式进行修改,可事半功倍;
- inline 表示声明内联函数,用于优化规模小、流程简单、频繁调用的函数;
- nogil 表示释放全局锁GIL,详情请看 15.11 用Cython写高性能的数组操作;
- except -1 表示如果函数出错返回 -1,类似于 python 的 try ... except 函数;
2、3、4点解析后,那么你对上面脚本中的变量、函数声明理解可以说是非常的清楚; 若果有需要频繁调用的,按此方式来声明,然后再看下面的 _dist_metrics.pyx 文件展示部分的代码,那么就可以很快的根据自己的需求进行修改;
_dist_metrics.pyx 文件是 _dist_metrics.pyd 声明的函数具体实现,和应用其声明的变量
b. 在函数具体实现脚本中,插入自己的实现代码,基本是将已有的算法复制出来,做部分修改;
cdef class DistanceMetric:
... ...
cdef DTYPE_t rdist(self, DTYPE_t* x1, DTYPE_t* x2,
ITYPE_t size) nogil except -1:
return self.dist(x1, x2, size)
cdef int pdist(self, DTYPE_t[:, ::1] X, DTYPE_t[:, ::1] D) except -1:
"""compute the pairwise distances between points in X"""
cdef ITYPE_t i1, i2
for i1 in range(X.shape[0]):
for i2 in range(i1, X.shape[0]):
D[i1, i2] = self.dist(&X[i1, 0], &X[i2, 0], X.shape[1])
D[i2, i1] = D[i1, i2]
return 0
cdef int cdist(self, DTYPE_t[:, ::1] X, DTYPE_t[:, ::1] Y,
DTYPE_t[:, ::1] D) except -1:
"""compute the cross-pairwise distances between arrays X and Y"""
cdef ITYPE_t i1, i2
if X.shape[1] != Y.shape[1]:
raise ValueError('X and Y must have the same second dimension')
for i1 in range(X.shape[0]):
for i2 in range(Y.shape[0]):
D[i1, i2] = self.dist(&X[i1, 0], &Y[i2, 0], X.shape[1])
return 0
### -*- 我自己的代码, start. ###
#不用去理解里面的含义,只是为了满足需求,对原距离计算做了调整;
#展示只是为了说明,直接修改比自己写,方便快捷,性能还高
cdef int hdist(self, DTYPE_t[:, ::1] X, DTYPE_t[:, ::1] D,
DTYPE_t outerRadius, DTYPE_t innerRadius) except -1:
"""compute the pairwise distances between points in X"""
cdef ITYPE_t i1, i2, disp
cdef DTYPE_t tmp
for i1 in range(X.shape[0]):
for i2 in range(i1, X.shape[0]):
# D[i1, i2] = self.dist(&X[i1, 0], &X[i2, 0], X.shape[1])
tmp = self.dist(&X[i1, 0], &X[i2, 0], X.shape[1])
if tmp > outerRadius:
break
if tmp < innerRadius:
D[i1, i2] = tmp
D[i2, i1] = D[i1, i2]
if X.shape[0] > 1:
for i1 in range(1,X.shape[0]):
disp = 0
for i2 in range(i1 - 1, -1, -1):
if disp == 1:
D[i1, i2] = INF
elif D[i1, i2] > outerRadius:
disp = 1
D[i1, i2] = INF
elif D[i1, i2] > innerRadius:
D[i1, i2] = INF
return 0
... ...- 上面脚本的实现,与 python 原生代码很类似,
[:, ::1] X是内存视图,下文将讲到,除 内存视图 是新的知识点外,无其他额外的引入,由此就完成了高效的 Cython 代码编写;
c. 编译,使用步骤二方法进行编译;
d.运行与测试;
在a、b、c、d步中,可能 c步 编译坑比较大,这也就是为什么推荐修改已有的编译脚本,可以避免很多坑; a、b步,出错率较低,因为是按照原有的算法,根据自己需求做一些细节上的修改,可能性能会比原算法实现差一些; d步,是测试算法性能与结果检验,在多次调试后,理论上是比原算法更快的,因为按照相应需求修改,会去掉中间部分不需要的操作,因此性能上一般是稍快的; 这也是写此文章的主旨,a、b、c步骤都是搬运原有算法、脚本,然后做一些细节上的修改,但可以避免大部分坑,实现的速度和算法运行的速度,会让你体验到无比的自豪的;
(二)、dbscan函数(更简单的实现)
dbscan在sklearn包中 Cython 实现是最简单的,而且也是最经典之一,自己对其做了很多修改,衍生了很多版本;
dbscan是无需指定聚类族数,但需要指定距离的聚类算法,在行程上,广泛应用,感兴趣的同学可以自行了解,下面链接为 dbscan 聚类过程的可视化
Visualizing DBSCAN Clusteringwww.naftaliharris.com
如果将 dbscan 用于业务上,一条轨迹点很多,存储空间大,如果可以稀疏而保留原有绝大部分轨迹信息,不单可以节省存储空间,关键信息点也一目了然:
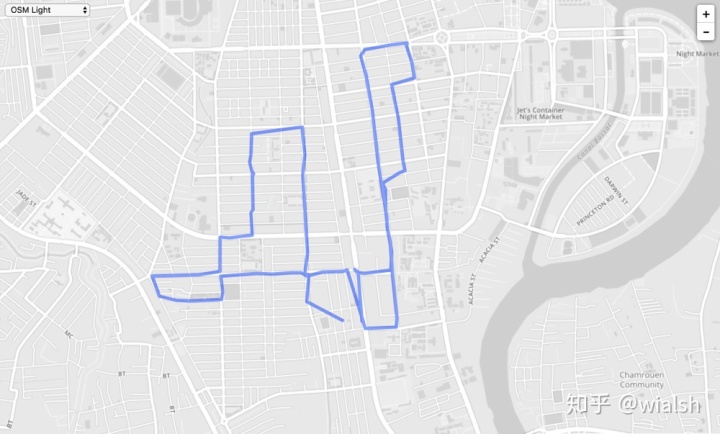
dbscan 文件位于 sklearn/cluster/_dbscan_inner.pyx;
a. 直接修改核心算法部分(无b步,然后进入c、d步骤)
# Fast inner loop for DBSCAN.
# Author: Lars Buitinck
# License: 3-clause BSD
cimport cython
from libcpp.vector cimport vector
cimport numpy as np
import numpy as np
# Work around Cython bug: C++ exceptions are not caught unless thrown within
# a cdef function with an "except +" declaration.
#将变量放入容器中
cdef inline void push(vector[np.npy_intp] &stack, np.npy_intp i) except +:
stack.push_back(i)
@cython.boundscheck(False)
@cython.wraparound(False)
def dbscan_inner(np.ndarray[np.uint8_t, ndim=1, mode='c'] is_core,
np.ndarray[object, ndim=1] neighborhoods,
np.ndarray[np.npy_intp, ndim=1, mode='c'] labels):
cdef np.npy_intp i, label_num = 0, v
cdef np.ndarray[np.npy_intp, ndim=1] neighb
cdef vector[np.npy_intp] stack
for i in range(labels.shape[0]):
if labels[i] != -1 or not is_core[i]:
continue
# Depth-first search starting from i, ending at the non-core points.
# This is very similar to the classic algorithm for computing connected
# components, the difference being that we label non-core points as
# part of a cluster (component), but don't expand their neighborhoods.
while True:
if labels[i] == -1:
labels[i] = label_num
if is_core[i]:
neighb = neighborhoods[i]
for i in range(neighb.shape[0]):
v = neighb[i]
if labels[v] == -1:
push(stack, v)
if stack.size() == 0:
break
i = stack.back() #从容器中拿去第一个元素
stack.pop_back() #删除第一个元素
label_num += 1- vector 是 C++ 标准库,容器,类似于 python 的 list;
- @cython.boundscheck(False) 表示关闭越界检查;
@cython.wraparound(False) 表示关闭负数下标索引;
均关闭后在数组索引时,那么将大大提升索引效率(Cython有示例说明关闭提升的速度,相关链接待提供); - 整体的脚本风格基本上是 python 风格,因此在修改、调优、debug方面,是事半功倍的,其次也可是比较快速的学习到如何写出高效的 Cython 的方法之一;
除了 vector 是 C++ 标准库外,其他是纯 python 代码,对其做一些修改,基本无其他技术难度;
另外,Cython可以完全由 Python 代码,开篇也说到,需要注意如下几点:
- 数组需要转化为 内存视图(下文将解析);
- 尽量减少使用 Python 内置函数的复杂操作,如 list的 append, map函数,filter函数,set去重等;
- 对于一些操作(索引、赋值、计算等)多用
for 和 while,所以上面示例中对于一些基本操作主要是以 for 循环为主,在 Cython 脚本编写中,你会感觉代码变‘低级’了; - 频繁调用 或 for循环无序(先索引、赋值、计算哪个值都可以),在声明文件中( .pyd )将对应的函数声明为 inline 或 释放GIL ;
- 如果你知道 C,C++ 标准库可以替代python中内置函数,那么就更高效了,这种慢慢品读 Cython 官方文档即可;
数据要像list那样操作,如 .append, .pop() ,建议使用 vector ,但尽量减少一个集合不断增加,且需要返回,如下:
#n值不固定,那么在Cython是比较低效的,笔者还未找到替代这种方法
#而上面dbscan脚本中,vector是C++容器,操作是在内部进行,无返回给python,因此它是高效的
def test(a0=[], n=10):
a = []
for i in range(n):
a.append(i)
a0.append(a0)
return a, a0关于一些补充
相信部分同学对距离计算函数数组声明方式有一些疑问,如下:
DTYPE_t[:, ::1] X`::1` 表示为了获得额外的速度增益,如果您知道您提供的NumPy阵列在内存中是连续的,则可以将 memoryview 声明为 连续性 的;
接下来对相关名词进行解析: memoryview 和 连续性
memoryview(内存视图)是C结构,可以保存指向NumPy数组的数据的指针以及所有必要的缓冲区元数据,以提供有效和安全的访问:维度,步幅,项目大小,项目类型信息等,memoryview支持切片,所以即使NumPy数组在内存中不连续,也能正常工作。它们可以由C整数索引,从而允许快速访问NumPy数组数据。
以下是如何声明整数的内存视图:
cdef int [:] foo # 1D memoryview 声明一维数组
cdef int [:, :] foo # 2D memoryview 声明二维数组
cdef int [:, :, :] foo # 3D memoryview 声明三维数组
... # You get the idea.
# def compute(array_1, array_2, int a, int b, int c): #old
def compute(int[:, :] array_1, int[:, :] array_2, int a, int b, int c):
...memoryview 和 numpy 初始化类似;
连续性 是指数组在哪一维度是连续排列的,numpy存储的数组默认是列存储,若是二维数组,那么numpy存储的数组第二维度是连续的,连续性索引性能高于非连续性,详情请看:What is the difference between contiguous and non-contiguous arrays?
定义方式如下:
cdef int [:,:,::1] a #C contiguous
cdef int [::1, :, :] a #Fortran contiguousC contiguous列连续,Fortran contiguous行连续,对于一个数组arr

import numpy as np
a = [[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]]
a0 = np.array(a, order='F')
print(a0.flags)
'''
C_CONTIGUOUS : False
F_CONTIGUOUS : True
OWNDATA : True
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
UPDATEIFCOPY : False
'''
a0 = np.array(a) # or a0 = np.array(a, order='C')
print(a0.flags)
'''
C_CONTIGUOUS : True
F_CONTIGUOUS : False
OWNDATA : True
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
UPDATEIFCOPY : False
'''如果频繁列索引,那么就数组调整为列连续;
如果频繁行索引,那么就数组调整为行连续;
行连续(Row major order)和 列连续(Column-major order) 的区别,主要看你拿这数组作什么运算,如果是要依次访问每列的元素,Fortran Order(即Column-major order)下每列在内存中是连续的,这种结构相对更加Cache-friendly。这并不是编程语言自身的特性,在C语言中完全可以使用Column-major order,只不过访问起来计算index不太习惯而已。Fortran大概是因为主要用于科学计算,Column-major order对于一些矩阵运算有性能优势。
释放GIL锁有几种方式
# We declare our plain c function nogil
cdef my_type clip(my_type a, my_type min_value, my_type max_value) nogil:
return min(max(a, min_value), max_value)
#example2
with nogil:
for i in range(a.shape[0]):
out[i] = (a[i] if a[i] < max else max) if a[i] > min else min
#example3
cimport cython
ctypedef fused double_or_object:
cython.double
object
def increment(double_or_object x):
with nogil(double_or_object is cython.double):
# Same code handles both cython.double (GIL is released)
# and python object (GIL is not released).
x = x + 1
return xCython推断C类型
如果一个变量输入有多种类型,那么可以在脚本顶端添加指令infer_types=True ;
定义了一个函数输入类型是 int,若可以扩展到double, long long等类型,使用ctypedef fused定义,同时在脚本顶端添加指令 infer_types=True
# cython: infer_types=True
import numpy as np
cimport cython
ctypedef fused my_type:
int
double
long long
...更多信息详看:Fused Types (Templates)
若果你想测试 Cython 脚本像测试 .py 脚本那样,使用 jupyter-notebook 执行 cython 脚本,示例请看:Cython for NumPy users(GitHub),Cython for NumPy users;
总结
自己捣鼓了 Cython 有一段时间,研究并不是很深,同时与同事做过一些交流,得到如下几点;
关于优势方面:
- Cython 用于一些简单的密集型计算法有着非常大的优势,不单计算快,还可以解锁 GIL;
- Cython 如果使用了 C、C++ 库,编译 BUG 比较多,但计算收益也是非常明显的,关于对比,本人自己用纯python写的 改进版dbscan 和 Cython 版 dbscan,后者速度是前者的 10倍 之多,数据量越大,加速越快;
- 修改现有开源包的 Cython,开发效率高;
关于缺点方面:
- 自导自演,Cython 如果不是专业开发者,无需捣鼓那么深,对于多语言用的很溜的同学,机器学习、深度学习做的很厉害的同学,可能完全不知道 Cython,主要是因为,如果需要高效的计算何不用 scala/go/C++ 等,同时 Cython 如果要深入研究,就涉及到了 引用、指针 等,而 Cython 风格又和 C++ 有些差异,如果算法经常涉及到 实时性、密集性,何不直接使用其他在此方面有很大优势的语言;
- Cython 对技能几乎无加分,因此本人也在此弃坑,转了解其他语言;
其他方面:
- Cython 文档写的很浅显易懂,而且还有性能对比,是入门首选;
- 简单且密集计算方面用 Cython 在对性能提升有很大帮助,但也不会在此方面开发太久;
一些补充:
- 写此文章,本人已在 Cython 弃坑一段时间,此前有个同学问,怎么入门学习Cython来加速算法,就把此前学习笔记整理给到他,他参考之后,觉得总结笔记还ok,建议有时间整理一下,把它分享出来,因此刚写文章不久,可能条理上不是很通顺,望指出;
- 此外很多例子因为与此前有一段时间,导致没有实质性的性能数值差异对比,这也是本篇文章的不足之处,但一些术语、速度对比均有相对应的 Cython 官方文档实例链接;
2020.05.10
- 首先,主要开发语言是python,且需要开发出简洁、高效的脚本,是有必要看看一些经典包部分细节实现,本人实现算法分析中经常剖析算法包,所以自己写的语言风格和技巧基本来自于自己剖析的包;
- 其次,对于包的官方文档或网上资料描述的可能不全,此时比较常用的手段就是进入包中查看相关实现细节,而对于机器学习来说,算法包为了加速算法,核心部分多数采用Cython实现,所以了解Cython,或可以加快开发进度,笔者因为有一定的Cython的经验,因此对了解部分算法参数在官方文档未查到满意结果,都会剖析下源码;
- 再次,在你对Cython有一定了解后,你或许会很喜欢剖析源码,而查看别人对包的文档总结不一定有很深的记忆,在开发效率(后期)和算法改进方面有一定帮助【笔者深有这种体会,特意分享出来】,当然此处本人一般不会去剖析复杂算法详细情况,因为耗时;
- 最后,经常剖析源码的人,代码会变得简洁,提高了代码运行效率,而且变量命名变得越来越规范(你是否有变量名不够用的情况?在剖析源码,吸收源码命名方式,会增加自己的命名词库),当然你可以在 codeif 利用关键字获取相关变量命名;















 502
502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









