







有一天接到了同事的一个电话,说是有一个数据库无法访问了,希望我帮一下忙,连接过去查看,发现是一个看似很简单的ORA错误,如下。
$ sqlplus / as sysdba
Copyright (c) 1982, 2011, Oracle. All rights reserved.
ERROR:
ORA-09817: Write to audit file failed.
Linux-x86_64 Error: 28: No space left on device
Additional information: 12
ORA-01075: you are currently logged on
这种问题想必大家都或多或少碰到过,从错误日志来看还是因为审计日志写不进去了;再进一步来说,就是磁盘空间不足了。
通过df -h的结果足以说明,磁盘空间确实是不足了,如下。
Filesystem Size Used Avail Use% Mounted on
/dev/sda7 5.9G 633M 4.9G 12% /
...
/dev/sdb1 3.1T 3.0T 0100%/data
注意:如果数据库因为磁盘空间无法登录,查看不了审计日志的路径,可以通过$ORACLE_ HOME/dbs下的参数文件来查找审计日志的路径。
准备清理磁盘空间,发现有一个大约100MB的临时文件,可以先挪到其他的目录下,然后再次尝试TNS连接就没有问题了。
问题似乎已经得到初步解决。但是过了不到一分钟,再次尝试,发现又无法登录。查看磁盘空间,空间已经用完了,于是又做了一些磁盘空间的清理,问题的处理才暂时告一段落。
这样一来,我们需要分析问题的原因。
首先,空间问题导致的数据库无法登录是不应该犯的错误。因为查看前几天的巡检结果,看到还剩下很多的空间。按照一个阈值来参考,还是够用的。
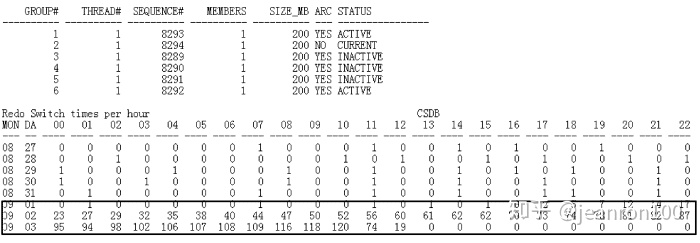
那就说明数据库层面还是有一些异常的地方,于是得到了如图4-2所示的报告。这个报告能够看出一个数据库的负载情况,能够看到在一个小时内redo的切换频率。横轴上方是时间,显示的是每个小时的归档切换频率,纵轴是日期。
可以看到在问题发生的时间段内(用框图标注出来的部分),redo切换频率极高,数据库负载是在近两天才升上去的,但是数据库redo切换如此频繁,是否在应用层面有一些大的变更目前还没有相关的通知,而导致空间问题就这样累计了下来,结果到第二天归档时一下子撑满了磁盘空间才发现问题。
为证实上面的想法还需要协同其他部门进一步确认,在此不作赘述。但是对于DBA来说,确实需要检查数据库层面的一些数据变化情况,而随时做出响应。
因为目前的环境使用Data Guard的架构,归档数据传输到备库的频率还是很高的,所以对于归档的保留也就采用了一些处理。目前的归档保留时间是2天,考虑到这些天内归档切换频率极高,很可能备库的空间也会占满。所以简单地修改了一下crontab中归档的删除策略很有必要。
注意:归档路径最好是放在fast_recovery_area_dest下,在11g备库中,会有一个空间阈值,超过了80%会自动删除闪回区下的文件,这是11g的一个新特性。
对于这个问题的反思如下:
(1)对于归档的删除,最好能够做些前瞻性的处理,比如,对于归档产生较多,但是又不希望直接删除归档的情况,可以对归档进行定时压缩和定时删除(定时删除的文档须是过期的),这样既节省了空间又可保留尽可能多的归档。
(2)数据库级的变更和应用关系极为紧密,如果有什么大的变更或者批量处理还是能够让DBA知晓,在这个问题上DBA还是需要做到先知先觉。
(3)从数据库层面进行了分析,在短期内生成了大量的redo,造成了频繁的日志切换,导致归档占用了大量的空间,最后无法登录,因此,我们可以做一些工作来尽可能长时间的保留近期的归档;同时我们还可以换一个思路,即查看是什么操作生成了大量的redo,是否可以减少redo的生成量,达到釜底抽薪的效果。
关于上面的反思第三条,顺着这个思路我们详细讲述一下。
一般来说,日志会记录尽可能完整的信息,这是做数据恢复的基础,但谨慎起见,我们先来分析一下再来做决定看看是否可行。
查看数据库的redo切换频率,在近几天内的redo切换频率极高,基本每个小时日志切换都在250次左右。对于一个OLTP的系统来说是非常高的负载,这种频繁的日志切换我也只在数据迁移的一些场景中碰到过。
但是奇怪的是查看数据库的DB time,却发现这个值其实并不高,如下所示,看起来似乎前后矛盾,因为从这一点来看数据库内的负载变化其实并不是很高。
BEGIN_SNAP END_SNAP SNAPDATE DURATION_MINS DBTIME
---------- ---------- ----------------------- ----------
82560 82561 05 Sep 2015 00:00 30 26
82561 82562 05 Sep 2015 00:30 30 26
82562 82563 05 Sep 2015 01:00 29 29
82563 82564 05 Sep 2015 01:30 30 27
82564 82565 05 Sep 2015 02:00 30 23
82565 82566 05 Sep 2015 02:30 30 23
82566 82567 05 Sep 2015 03:00 30 20
对于这种情况,我们还是抓取一个AWR报告来看看。
在AWR报告中,可以看到瓶颈还是主要在DB CPU和IO相关的等待事件,见表4-1。
Top 5 Timed Foreground Events
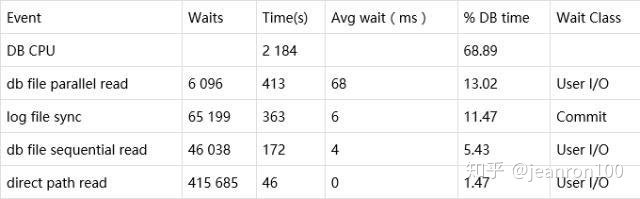
查看时间模型,可以看到DB CPU和SQL相关的影响各占了主要的比例。
查看等待事件能够看到主要都是在CPU的消耗上,进一步分析能够关注的重点就是SQL语句,Top 1的SQL语句执行情况见下表。
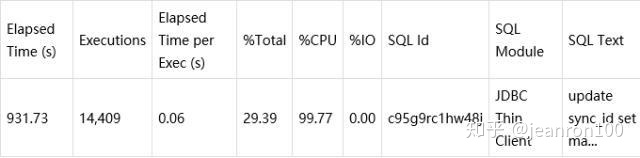
这条语句执行频率极高,语句也很简单,但是CPU消耗却很高,初步怀疑是走了全表扫描。
语句如下:
update sync_id set max_id = :1 where sync_id_type = :2
简单查看执行计划,发现确实是走了全表扫描;通常情况下,这种情况首先是需要走索引的,没有索引可以新建一个索引,但是当笔者看到SQL by Executions这个部分时,发现问题其实不是那么简单。
可以看到第2个语句就是刚刚提到的Top 1的SQL,对应的指标很不寻常的,一次执行处理的行数近5 000多行,执行了1万多次,处理的数据行数近8000万,见下表。
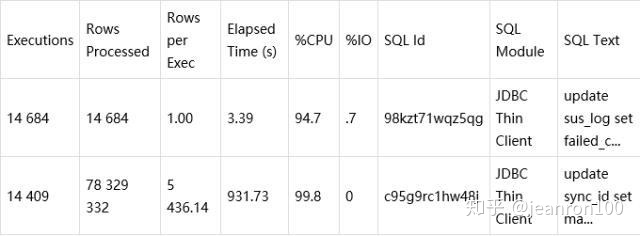
但是查看表,发现数据其实就是1万多条,所以这明显是一个问题。
我们再来进一步分析,一个小表1万多行的数据,每次执行更新5 000多行,可以断定数据的分布是不均匀的。因为这个表结构非常简单,只有两个字段,所以还是很好定位的。
简单查看了一下数据情况,发现数据主要分布在两个type列值上,基本上占用了99.99%以上,如下所示。
SQL> select max_id,count(*)from SYNC_ID where SYNC_ID_TYPE='SYNC_LOG_ID' group by max_id;
MAX_ID COUNT(*)
---------- ----------
38 5558
SQL> select max_id,count(*)from SYNC_ID where SYNC_ID_TYPE=SYNC_TEST2_LOG_ID' group by max_id;
MAX_ID COUNT(*)
---------- ----------
108 5577
从数据的分布情况可以看到,表中存在了大量的冗余数据,而且表中也没有索引字段和其他约束;这样一来,每次更新时只要更新一个字段值,就会修改5 000多行数据的值;如果执行频繁,短时间内就会频繁生成大量的redo。因此从目前的SQL运行情况来看,这条语句应该是造成redo频繁切换的主要原因。
毕竟是线上环境,需要做一些确认和沟通之后才能够变更的,目前只是建议,我们还需要验证测试一下。
测试的思路很简单,只需把这个表里的数据导出来,放到其他的测试环境中,然后模拟做频繁的更新,查看归档的频率即可。
首先把数据导入另外一个测试环境中。
其次使用下面的语句进行频繁更新即可,先更新100万次,中间可以随时中断,于是我写了下面的脚本。
function test_update
{
sqlplus test/test <<EOF
update sync_id set max_id = 38 where sync_id_type = 'SYNC_LOG_ID';
commit;
EOF
}
for i in {1..1000000}
do
test_update
done
在测试开始的时候,归档切换频率是0。
Redo Switch times per hour xxxx-Sep-05 16:02:55
MON DA 16 17 18 19 20 21 22 23
--- -- -- ---- ---- ---- ---- ---- ---- ---- ----
09 05 0 0 0 0 0 0 0 0
运行了不到3分钟,日志切换就达到了14次,还是能够说明问题的。
Redo Switch times per hour xxxx-Sep-05 16:05:20
MON DA 16 17 18 19 20 21 22 23
--- -- - ---- ---- ---- ---- ---- ---- ---- ----
09 05140 0 0 0 0 0 0
然后我们使用更新的方式来验证一下。
Redo Switch times per hour xxxx-Sep-05 16:08:04
MON DA 16 17 18 19 20 21 22 23
--- -- ------ ---- ---- ---- ---- ---- ---- ----
09 05140 0 0 0 0 0 0
过了4分钟,日志一次都没有切换,这就足以说明了我们的推论是正确的。
MON DA 16 17 18 19 20 21 22 23
--- -- ------ ---- ---- ---- ---- ---- ---- ----
09 05140 0 0 0 0 0 0
最后就是做进一步的确认,然后在正式的环境中部署,在线上环境清理了冗余数据之后,这个问题再没有出现过。















 5431
5431











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









