






前言
本文是对之前实现的软光栅渲染器中光栅化算法的进一步讲解与优化,这里放上前文的传送门:https://zhuanlan.zhihu.com/p/95621444
在之前的文章中,我使用的是扫描线算法来对三角形进行光栅化,这种方法非常直观,效率也还不错,但并不是现代GPU和CPU上使用的算法。本文将基于使用更广泛的重心法进行讲解,在学习过程中我主要参考了下面两篇文章,并补充了一些细节,如果英语水平过关的话建议先阅读下面的文章哦。
重心的计谋
加速半空间三角形光栅化
回顾
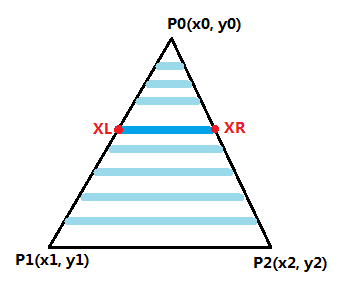
前文中我们实现的是扫描线算法,这种算法的原理是以三角形的长边为底,一行一行向上/向下绘制像素点。

具体到操作上,该算法步骤为:
- 判断三个顶点的相对位置,确定是平顶/平底还是一般三角形
- 将一般三角形以中间的顶点横向拆分为一个平底和一个平顶三角形
- 通过插值在长边上生成新的边界点
- 分别对上部/下部三角形运行平底/平顶光栅化算法
- 每次绘制一行,通过插值生成两个边界点,绘制边界点之间部分
扫描线算法的缺点在于难以并行化(毕竟操作的单位是一条线)。此外,在实现时还存在由于多次插值的精度损失导致的多个三角形间存在接缝的问题。需要说明的是,这些问题并不是没法解决,我查到的资料中还是有游戏实际应用了这种算法的,只不过现在大家都换用更加适合并行的算法了。单线程情况下扫描线算法的效率并不算低,用CPU渲染的话瓶颈更多的是在插值和片段着色上。
边界函数算法(Edge-Function)
边界函数算法,又叫半空间(half-space)光栅化算法,其基本原理在于,每一条直线都可以将平面分为左右(上下)两个半空间。三角形三条边的半空间交集可以定义三角形的内部区域
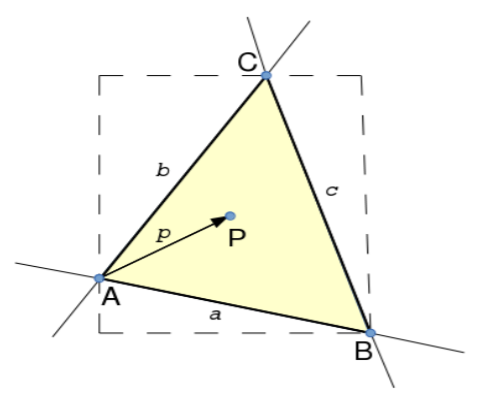
如果我们有一个点P,该如何判断点P是否在三角形内部呢?以上图为例,AP向量在AC向量的右侧,AP向量在BA向量的右侧,AP向量在CB向量的右侧,也就是说,将三角形的边向量按照同一个旋向定义(AC CB BA或是AB BC CA),在三角形内部的点与(AP BP CP)的位置关系应该是一致的。
这个判断我们可以用叉乘来做,按照右手定则,由AC/CB/BA握向AP/CP/BP,拇指的指向是相同的。以坐标表示如下
这个Fab(P)就是我们的边界函数了,它实际上就是AB与AP的叉乘,对于逆时针顶点顺序三角形,在内部的点求得的三个F值都应大于等于0(顺时针都小于等于0)。
基础的边界函数算法的实现伪代码如下
//求出三角形的包围盒(minX,minY,maxX,maxY)
上面的写法适用于逆时针顶点顺序,也就是我们一般认为的正向面,对于顺时针顶点顺序三角形,在计算之前交换任意两个顶点顺序即可。
优化考虑
我们的边界函数可以改写一下:
可以看到这个函数对于Px Py都是完全线性的,两格之间的差值是固定值。
那么我们在遍历的时候根本就不需要每次计算三个边界函数值了,只需要计算起点处的三个初始值,每移动一格就加上固定差值即可。优化后的伪代码如下:
其中
//求出三角形的包围盒(minX,minY,maxX,maxY)
这样优化以后,整个像素遍历内循环就不再需要做乘法运算,运算速度更快。此外,由于对循环内的每个像素执行的操作都一样,我们还可以使用SIMD指令对整个流程进行加速,同时对四个像素进行操作,一次执行4个像素的加法操作。
分块
上面的算法优化了边界函数的计算,但还有一个很严重的问题没有解决,那就是该如何减少遍历的空像素数量。三角形的面积最多只有包围盒的一半,这意味着逐像素遍历我们始终要遍历大于一半的空像素。因此便有了分块的优化算法。
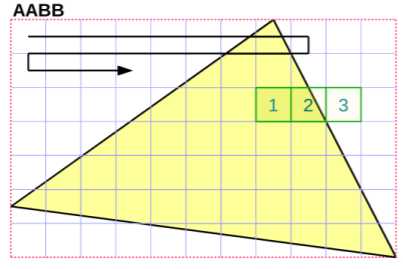
如上图所示,将多个像素组合成正方形的像素块,每次逐块遍历,检测每个块的左下角和右上角是否在三角形内,并可分为图中绿块表示的三种类型:
- 完全在三角形内
- 部分在三角形内
- 完全在三角形外
对于1和3,我们就不需要再为块中每个像素计算边界函数了,直接对整个块进行渲染或是丢弃。对于2,我们再使用刚才的逐像素边界函数算法进行绘制。此方法对于占屏幕面积较大的三角形优化效果明显,但如果是小三角形或是斜长的细三角形,反而不如不分块来得快。此外,太大的分块会进一步降低小三角形的绘制效率,而太小的分块又变回了逐像素算法,因此分块的大小需要仔细的权衡。
还有一件事
上述算法只做到了判断某个像素是否在三角形内,但真正要绘制像素点还需要运行片段着色器。我们原来的扫描线算法在光栅化的时候就做好了插值,但现在去哪里找法线和深度信息呢?这时候就需要重心坐标出马了。
这里我放一篇知乎上写重心坐标的文章:三角形重心坐标 by @二圈妹
借用一下配图进行推导
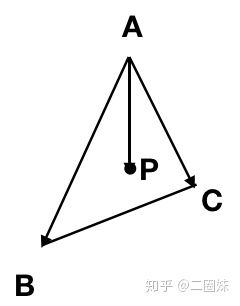
使用三个顶点的信息按照(1-u-v,u,v)的权重进行线性插值,即可获得P点处的信息,此处的信息可以是一切线性信息(包括深度,透视除法后的法线、纹理坐标、世界坐标等等等)。
那么,这个插值权重该如何获取呢?

我们知道三角形的面积等于
取两条边AB和AC ,可得三角形面积为 (把叉乘行列式拆开)
我们回头看一下边界函数,发现
三个边界函数之和正好是三角形面积的两倍,那么:
于是
令
则可以得出插值公式 :
这个插值公式在像素间的差值同样是定值,因此我们同样可以将插值工作转化为加法操作,加快运算的速率。
由于:
所以 :
加入了插值的光栅化算法伪代码如下:
//这里的顶点信息已经经过了透视除法
写在最后
看到这里相信你已经三角形的光栅化有一定了解了,希望这篇文章能够帮到你。不过在最后我想吐槽的是,在CPU单线程条件下上述算法的改进实在是聊胜于无。如果不运行片段着色器,仅插值深度(Intel就弄了一个在CPU上光栅化深度图的软件,可以加速显卡渲染:软件遮挡剔除),能够提升30%以上的速度,一旦改成完整的渲染流程,帧数则几乎没有变化,可见瓶颈并不在这里。想要更进一步的提升,就必须考虑并行化了,包括使用SSE、AVX等SIMD指令,以及使用多线程等。

下一期打算写纹理相关的内容,这期就写到这里吧















 8139
8139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









