





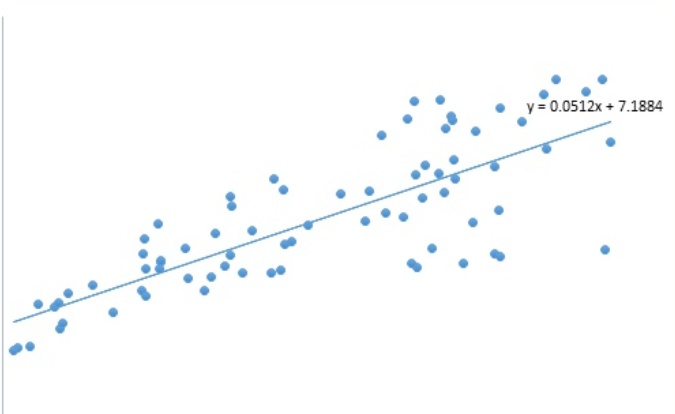
1 介绍
线性回归与逻辑回归是机器学习中必须要掌握的算法,接下来我会用简洁的语言介绍一下算法的原理。然后是逻辑回归的代码实现,代码中加入了充分的注释以易理解。
(如果您对线性回归与逻辑回归的原理已经了如指掌,可以回顾一下原理中的求导结果(代码中会用到),然后直接前往代码实践部分)
2 原理
2.1 线性回归
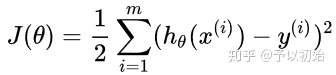
线性回归的损失函数如上所示,是预测值与真实值的均方误差,越小越好。
(为什么用该式作为损失函数?直观理解,该式子表达的是预测值与真实值总体的差异。也可从概率的角度解释,从极大似然估计的最大化目标,推导得到最小化该目标,这里不作解释)
简洁起见,下面的公式使用矩阵形式进行介绍。(X,Y表示的是整体的样本与标签,所以矩阵形式的公式无需累加符号)
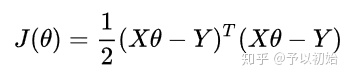
此时的目标是:求得最优的
步骤:
1)先求 J 对
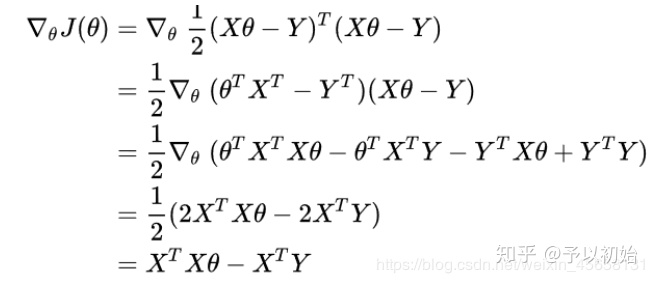
2)再求使得 J 最小的
有两种方法:
正规方程法:直接令 J 对

梯度下降法:该方法通过迭代使得
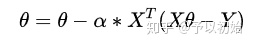
2.2 逻辑回归
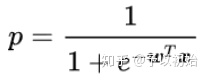
输出的表达式P如上图,逻辑回归就是在线性回归输出时,套上一个sigmoid函数,将输出值压缩到 [0, 1] 之间作为概率值。
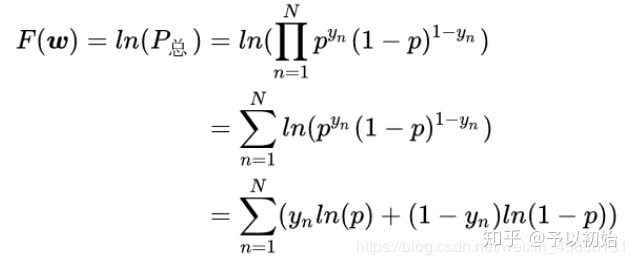
(为什么用该式作为损失函数?交叉熵损失也可从概率的角度进行解释,从极大似然估计的最大化目标,推导得到最小化该目标,这里不作解释)
求解步骤:
1)先求 -F 对 w 的导数:
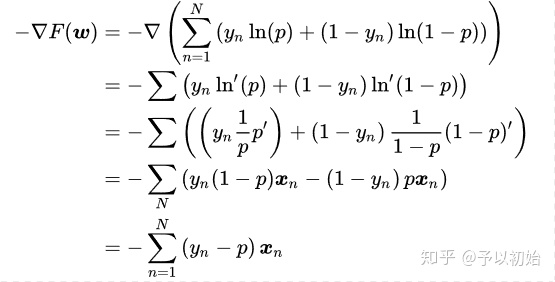
(可以发现,求得的导数跟线性回归形式相同,都是真实值与预测值的误差乘上输入X)
2)梯度下降迭代求解:
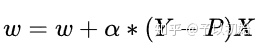
(牢记该公式,代码实现中会使用到该结果)
3 代码
该代码为逻辑回归算法的实现:
class LogRegres:
def __init__(self, lr, epchos):
self.lr = lr
self.epchos = epchos
def sigmoid(self, x):
return 1 / (1 + np.exp(-x))
def train(self, X, y):
# 将输入转换成numpy的矩阵类型,防止出现运算错误
X = np.mat(X)
y = np.mat(y).reshape(-1, 1)
m, n = X.shape
# 初始化权重矩阵W与偏置b,权重个数等于特征个数n
self.W = np.zeros((n, 1))
self.b = 0
# 将偏置b融合进W,跟随W一起计算
# 输出的计算:X*W = (m,n+1)*(n+1,1) =(m, 1)
X = np.insert(np.mat(X), 0, 1, axis=1) #输入的第一列加上1,shape(m, n+1)
self.W = np.insert(self.W, 0, self.b, axis=0) #权重第一行加上b,shape(n+1, 1)
# 迭代更新W
for i in range(self.epchos):
output = self.sigmoid(X*self.W)
self.W += self.lr * X.T * (y-output) # 损失函数对w的偏导等于X*(y_true-y_pre)
return
def predict(self, X_test):
# 第一列加上1
X_test = np.insert(np.mat(X_test), 0, 1, axis=1)
return self.sigmoid(X_test * self.W)使用: 数据集如下:
testSet.txtgithub.comimport numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
train = np.loadtxt('testSet.txt') #数据集shape(100, 3),最后一列是类别标签
X, y = train[:, :2], train[:, -1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4)
model = LogRegres(lr=0.1, epchos=1000) #配置模型参数:学习率、迭代次数
model.train(X_train, y_train)
y_pre = model.predict(X_test)
y_pre = [1 if x>=0.5 else 0 for x in y_pre] #概率转成类别
print(accuracy_score(y_test, y_pre)) #0.975
print(model.W) #打印训练好的权重希望看完此文的你,能够有所收获,如有问题,欢迎指出。
喜欢可以点个赞~ 三克油
写在最后
机器学习zhuanlan.zhihu.com
如果你对机器学习感兴趣,欢迎关注我的机器学习专栏~















 708
708











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









