






这里我们将展示如何使用 NBA 比赛的以往统计数据,判断每个球队的战斗力,及预测某场比赛中的结果。我们将按照下面的流程实现 NBA 比赛数据分析的任务:
- 获取比赛统计数据
- 比赛数据分析,得到代表每场比赛每支队伍状态的特征表达
- 利用机器学习方法学习每场比赛与胜利队伍的关系,并对 2016-2017(这里只是举个例子,大家可以预测2020赛季的,哈哈)的比赛进行预测
在本次实验中,我们将采用 Basketball Reference.com中的统计数据。在这个网站中,你可以看到不同球员、队伍、赛季和联盟比赛的基本统计数据,如得分、犯规次数、胜负次数等情况。而我们在这里将会使用 2015-2016 NBA Season Summary 中的数据。在这个 2015-2016 总结的所有表格中,我们将使用的是以下三个数据表格:
- Team Per Game Stats:每支队伍平均每场比赛的表现统计
- Opponent Per Game Stats:所遇到的对手平均每场比赛的统计信息,所包含的统计数据与 Team Per Game Stats 中的一致,只是代表的是该球队对应的对手的统计信息
- Miscellaneous Stats:综合统计数据
获取比赛数据
我们将以获取 Team Per Game Stats 表格数据为例,展示如何获取这三项统计数据:
- 进入到 Basketball Reference.com 中,在导航栏中选择Season并选择2015~2016赛季中的Summary:
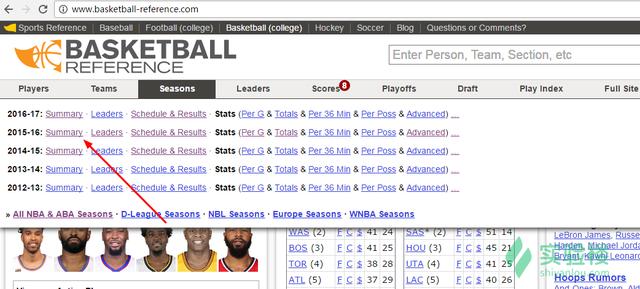
2.进入到 2015~2016 年的Summary界面后,滑动窗口找到Team Per Game Stats表格,并选择左上方的 Share & more,在其下拉菜单中选择 Get table as CSV (for Excel):

3.复制在界面中生成的 csv 格式数据,并粘贴至一个文本编辑器保存为 csv 文件即可:
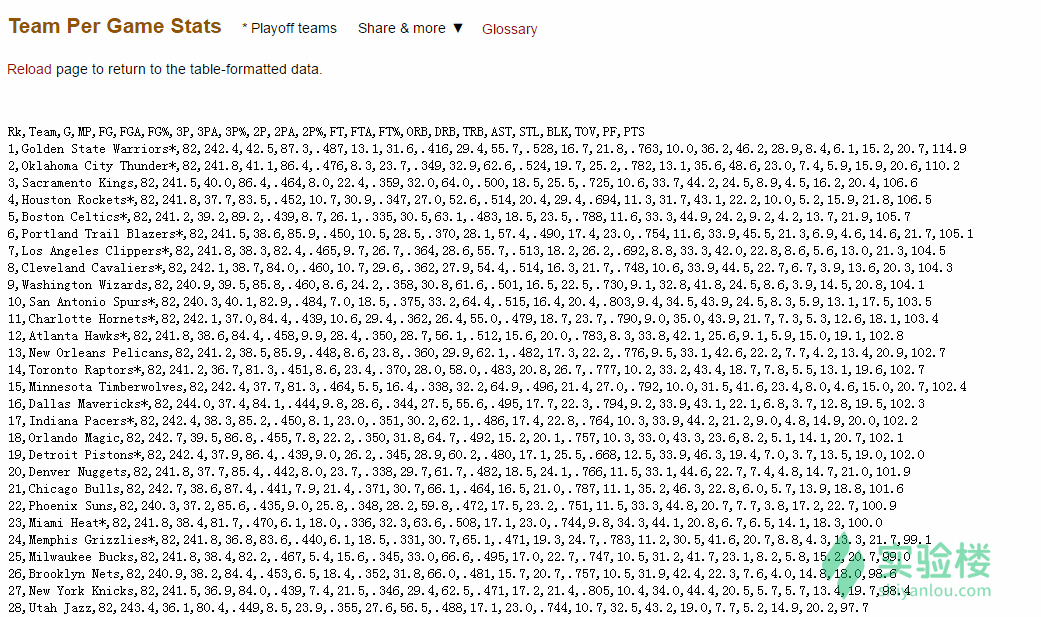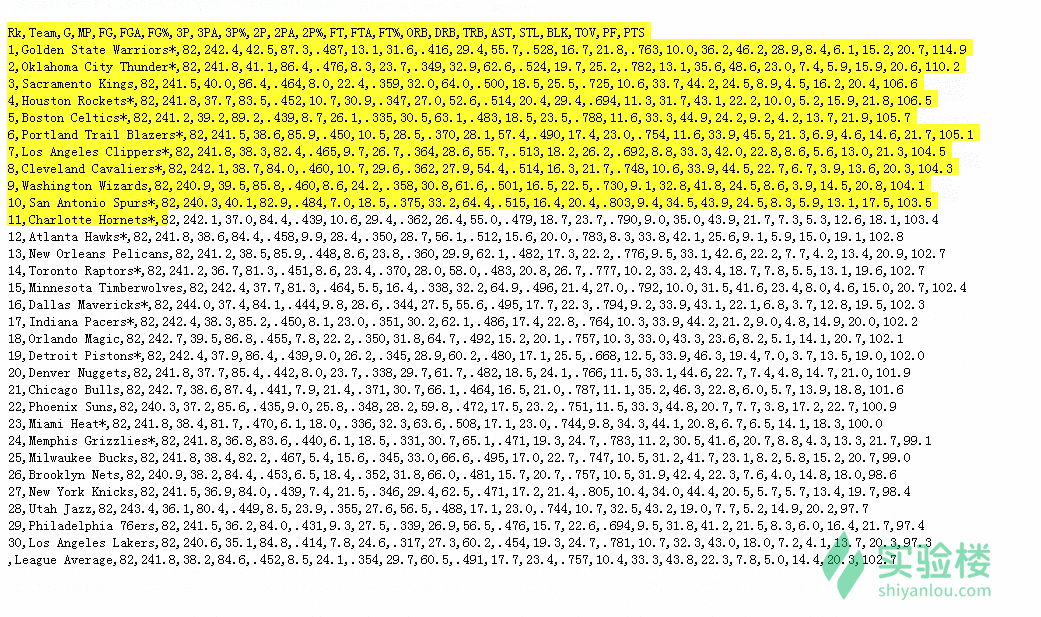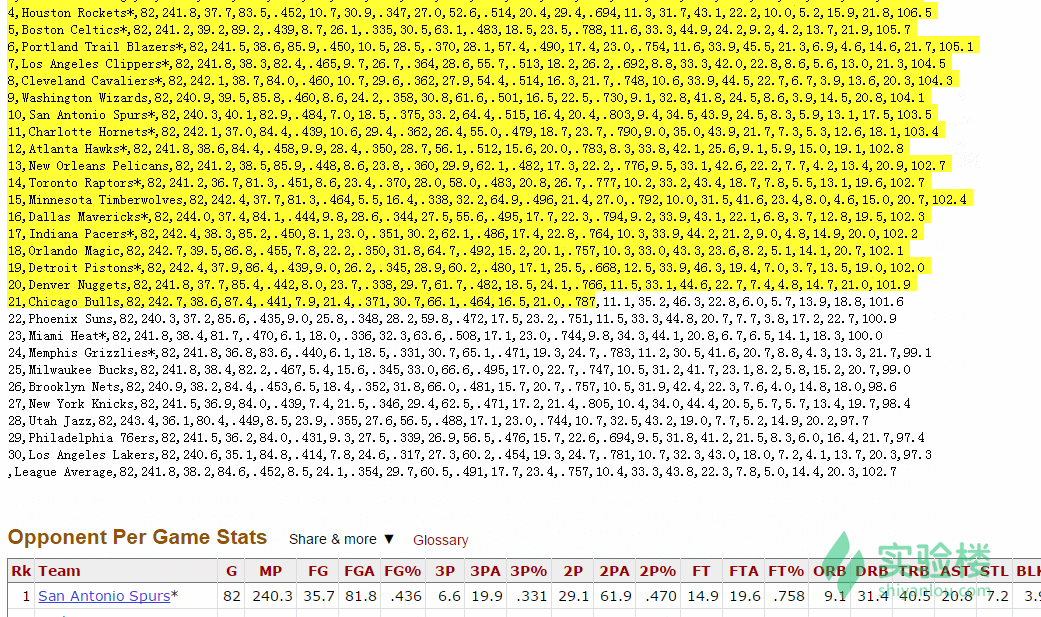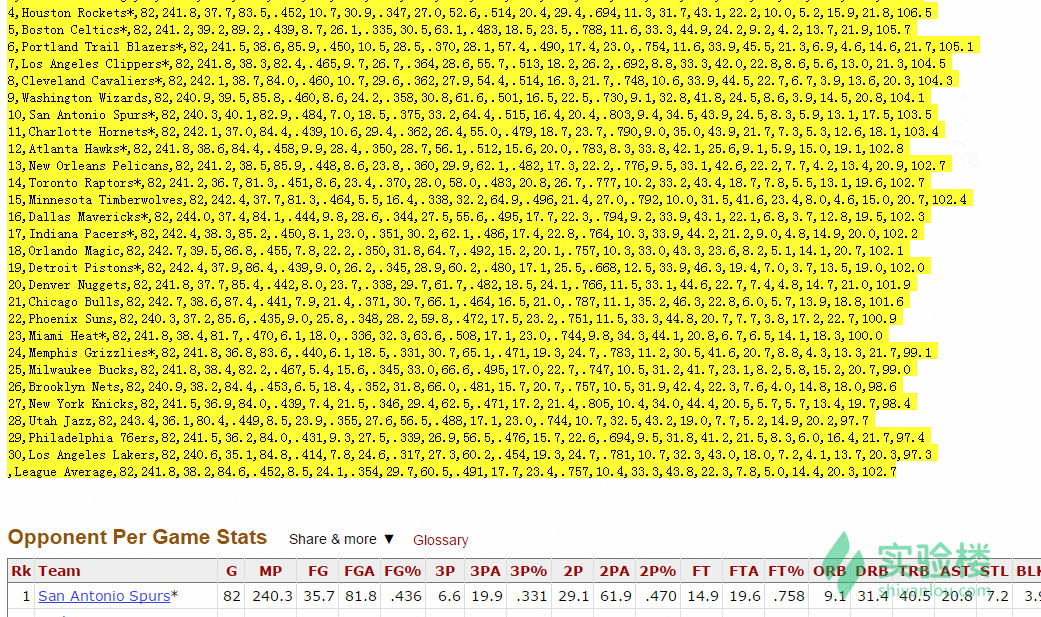
数据分析
在获取到数据之后,我们将利用每支队伍过去的比赛情况和 Elo 等级分来判断每支比赛队伍的可胜概率。在评价到每支队伍过去的比赛情况时,将使用到 Team Per Game Stats、Opponent Per Game Stats 和 Miscellaneous Stats(之后简称为 T、O 和 M 表)这三个表格的数据,作为代表比赛中某支队伍的比赛特征。我们的目标是实现针对每场比赛,预测比赛中哪支队伍最终将会获胜,但并不是给出绝对的胜败情况,而是预判胜利的队伍有多大的获胜概率。因此我们将建立一个代表比赛的特征向量。由两支队伍的以往比赛统计情况(T、O 和M表)和两个队伍各自的 Elo 等级分构成。所谓Elo等级分就i是一个公式。
代码实现
首先,引入实验相关模块:
import pandas as pd
import math
import csv
import random
import numpy as np
from sklearn import linear_model
from sklearn.model_selection import cross_val_score
设置回归训练时所需用到的参数变量:
# 当每支队伍没有elo等级分时,赋予其基础elo等级分base_elo = 1600team_elos = {} team_stats = {}X = []y = []# 存放数据的目录folder = 'data' 在最开始需要初始化数据,从 T、O 和 M 表格中读入数据,去除一些无关数据并将这三个表格通过Team属性列进行连接:
# 根据每支队伍的Miscellaneous Opponent,Team统计数据csv文件进行初始化
def initialize_data(Mstat, Ostat, Tstat):
new_Mstat = Mstat.drop(['Rk', 'Arena'], axis=1)
new_Ostat = Ostat.drop(['Rk', 'G', 'MP'], axis=1)
new_Tstat = Tstat.drop(['Rk', 'G', 'MP'], axis=1)
team_stats1 = pd.merge(new_Mstat, new_Ostat, how='left', on='Team')
team_stats1 = pd.merge(team_stats1, new_Tstat, how='left', on='Team')
return team_stats1.set_index('Team', inplace=False, drop=True)
获取每支队伍的Elo Score等级分函数,当在开始没有等级分时,将其赋予初始base_elo值:
def get_elo(team): try: return team_elos[team] except: # 当最初没有elo时,给每个队伍最初赋base_elo team_elos[team] = base_elo return team_elos[team]定义计算每支球队的Elo等级分函数:
# 计算每个球队的elo值
def calc_elo(win_team, lose_team):
winner_rank = get_elo(win_team)
loser_rank = get_elo(lose_team)
rank_diff = winner_rank - loser_rank
exp = (rank_diff * -1) / 400
odds = 1 / (1 + math.pow(10, exp))
# 根据rank级别修改K值
if winner_rank < 2100:
k = 32
elif winner_rank >= 2100 and winner_rank < 2400:
k = 24
else:
k = 16
# 更新 rank 数值
new_winner_rank = round(winner_rank + (k * (1 - odds)))
new_loser_rank = round(loser_rank + (k * (0 - odds)))
return new_winner_rank, new_loser_rank
基于我们初始好的统计数据,及每支队伍的 Elo score 计算结果,建立对应 2015~2016 年常规赛和季后赛中每场比赛的数据集(在主客场比赛时,我们认为主场作战的队伍更加有优势一点,因此会给主场作战队伍相应加上 100 等级分):
def build_dataSet(all_data):
print("Building data set..")
X = []
skip = 0
for index, row in all_data.iterrows():
Wteam = row['WTeam']
Lteam = row['LTeam']
#获取最初的elo或是每个队伍最初的elo值
team1_elo = get_elo(Wteam)
team2_elo = get_elo(Lteam)
# 给主场比赛的队伍加上100的elo值
if row['WLoc'] == 'H':
team1_elo += 100
else:
team2_elo += 100
# 把elo当为评价每个队伍的第一个特征值
team1_features = [team1_elo]
team2_features = [team2_elo]
# 添加我们从basketball reference.com获得的每个队伍的统计信息
for key, value in team_stats.loc[Wteam].iteritems():
team1_features.append(value)
for key, value in team_stats.loc[Lteam].iteritems():
team2_features.append(value)
# 将两支队伍的特征值随机的分配在每场比赛数据的左右两侧
# 并将对应的0/1赋给y值
if random.random() > 0.5:
X.append(team1_features + team2_features)
y.append(0)
else:
X.append(team2_features + team1_features)
y.append(1)
if skip == 0:
print('X',X)
skip = 1
# 根据这场比赛的数据更新队伍的elo值
new_winner_rank, new_loser_rank = calc_elo(Wteam, Lteam)
team_elos[Wteam] = new_winner_rank
team_elos[Lteam] = new_loser_rank
return np.nan_to_num(X), y
最终在 main 函数中调用这些数据处理函数,使用 sklearn 的Logistic Regression方法建立回归模型:
if __name__ == '__main__': Mstat = pd.read_csv(folder + '/15-16Miscellaneous_Stat.csv') Ostat = pd.read_csv(folder + '/15-16Opponent_Per_Game_Stat.csv') Tstat = pd.read_csv(folder + '/15-16Team_Per_Game_Stat.csv') team_stats = initialize_data(Mstat, Ostat, Tstat) result_data = pd.read_csv(folder + '/2015-2016_result.csv') X, y = build_dataSet(result_data) # 训练网络模型 print("Fitting on %d game samples.." % len(X)) model = linear_model.LogisticRegression() model.fit(X, y) # 利用10折交叉验证计算训练正确率 print("Doing cross-validation..") print(cross_val_score(model, X, y, cv = 10, scoring='accuracy', n_jobs=-1).mean())最终利用训练好的模型在 16~17 年的常规赛数据中进行预测。
利用模型对一场新的比赛进行胜负判断,并返回其胜利的概率:
def predict_winner(team_1, team_2, model): features = [] # team 1,客场队伍 features.append(get_elo(team_1)) for key, value in team_stats.loc[team_1].iteritems(): features.append(value) # team 2,主场队伍 features.append(get_elo(team_2) + 100) for key, value in team_stats.loc[team_2].iteritems(): features.append(value) features = np.nan_to_num(features) return model.predict_proba([features])在 main 函数中调用该函数,并将预测结果输出到16-17Result.csv文件中:
# 利用训练好的model在16-17年的比赛中进行预测
print('Predicting on new schedule..')
schedule1617 = pd.read_csv(folder + '/16-17Schedule.csv')
result = []
for index, row in schedule1617.iterrows():
team1 = row['Vteam']
team2 = row['Hteam']
pred = predict_winner(team1, team2, model)
prob = pred[0][0]
if prob > 0.5:
winner = team1
loser = team2
result.append([winner, loser, prob])
else:
winner = team2
loser = team1
result.append([winner, loser, 1 - prob])
with open('16-17Result.csv', 'w') as f:
writer = csv.writer(f)
writer.writerow(['win', 'lose', 'probability'])
writer.writerows(result)
print('done.')
最后,我们实验 Pandas 预览生成预测结果文件16-17Result.csv文件:
pd.read_csv('16-17Result.csv',header=0)













 1202
1202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









