






原创:谭婧
谭婧老师我近期看大模型推理,
有点心(脱)得(发)。
首先,害得我又又又高强度学习了一把,
说好背水一战,
怎么背水十战?
其次,什么Batching,
KVCache,HBM,Tokens/s……
一时间,
都不知道是在学AI,
还是在学英语。
我的结论是,推理高效实现在芯片上,
需要考虑和顾虑的东西有很多,
俗称,水很深。
当然,如果你是大神,
就当我啥也没说。
虽然从算法上看,
推理比训练简单了很多,
但想实现得好。
且有的讲究。
若细细来写,篇篇万字,稿稿术语。
那简直是读者劝退三连发。
上一篇的本质是在评价:
中美科技企业在推理上不同的吸睛策略。
被吐槽难啃。

于是,这篇聊点浅的,
先看发生了哪些好玩的。
(一)四件事四个视角
第一件事,
吴恩达在推特上,
亲自为推理芯片(算力需求)站台。
他同时表扬了两家风头正劲的美国AI芯片公司,
一家叫Groq的公司,
“号称”快,
但这家成本太高(堆Sram)。
5月29日官宣推理速度到1250 Tokens/s。
一家叫SambaNova的公司,
它家非常猛,
他们连混合专家大模型都自己做了,
整了个软硬全栈大全套,
可以直接对标华为在AI上的打法。
5月29日官宣推理速度搞到1084Tokens/s。
看看时间,
看看指标,
你追我赶,氛围感有了吧,
吴恩达老师的推特全文会放在文末。
我的结论是:
上周,美国湾区AI推理速度已经迈入,
每秒生成千个Token(词元)大关。
对,是每秒。
这是一件大事。
很多人没有感知到。

第二件事,
有一位互联网大厂技术高管,
以朋友身份私下告诉我,
他们公司技术高管会上,有一个结论:
训练并非终极难题。
若是训练慢?
多个把月,尚可忍耐。
若是缺算力?
从别的事业部“借”。
若是训练性能不好?
从开源社区“借”。
那何为这一阶段的难题?
答案是,推理。
第三件事,
有投资人告诉我:
“现阶段,重点全放在推理芯片上。”
注意这个“全”字。
“别说单独做推理芯片,
就算搞训推一体的芯片,
重点也在推理上。”
投资人的话不能全信,
尤其当他们已经做出选择的时候。
不过,从2022年开始,
芯片融资不太容易,
今年有不少崭新的《推理芯片再融资计划书》,
轻置于投资人桌上。
“再融资”,是说,
现有芯片玩家针对推理芯片有一轮新的融资计划,
说到底,推理芯片,
很多玩家都能做。
到底做的性能如何?
是菜鸡互啄,还是八仙过海。
第四,
我当面请教了,
零一万物的李开复老师。
他先肯定了推理芯片的技术含量:
“训练芯片和推理芯片差别比较大。
训练芯片还是有一定的难度。”
在机会方面,他这样告诉我:
“推理芯片有几点:
一是本身比较简单,
二是对CUDA没有那么强的依赖性,
还有,它不见得需要那么难的制造过程,
所以,我们对国产AI推理芯片是看好的,
也会在合适的时候去采用。
同时,创新工场一直在关注这方面的投资机会。”
在我看来,以上这四件事,
是强有力的“信号”:
是时候该推理发力了。
有人会问,训练和推理都是大模型这个软件系统的一部分,
难道不是一体的吗?
是的。
而推理也有自己的特点,
有了特点,才好聊如何针对性地解决。
(二)AI推理芯片特点
大模型是军备竞赛,
几乎是个共识。
要我说,训练是军备竞赛。
而推理不是。
一套流水线上是有两套系统,
先训练,后推理,
两个阶段,前后分明。
两者的裉节也不一样。
训练是大力出奇迹。
而推理用大力,
出不了奇迹。
训练是研发,
而推理是生产,
训练的难处,
可用研发实验室里的故事来理解。
而推理的难,
可用在生产线上的故事来理解。
谁率先创新,
谁率先烧钱。
有一种“训练”,
叫“假装训练”,
那种把别人家训练代码,
数据,参数一口气都买走的玩家,
那种直接用开源的玩家,
假装很投入。
假装干大事。
而真投入,风险大。
一堆人天天跑实验。
实验就有可能结果不确定,
常用动词:探索,摸索。
(AI大模型技术路线之争:你可以信仰多模态,也可以无视多模态)
(科大讯飞刘聪:假如对大模型算法没把握,错一个东西,三个月就过去了)
训练跑实验,要有卡,很花钱。
推理则是要把烧掉的钱赚回来。
玩极致性价比。
给企业客户省钱,
给APP个人用户省钱,
且保证性能。
当大语言模型的回答问题的能力,
颠覆互联网搜索,
来看看,
谷歌母公司Alphabet 董事长,
约翰·赫尼西(John Hennessy)
对路透社说的话:
“大语言模型的对话成本,
可能比我们熟知的上网搜索高出10倍。”
关键词,只有几个词。
大模型则不然,推理成本要分两种情况考虑。
一种,给大模型一句话。
另一种,给大模型一本书。
《三体》《红楼梦》,随你。
玩法变了,成本肯定也变了。
很显然,经济学维度的考虑加进来了。
简单说,
虽有“扔本书”有一定技术含量,但很费钱。
所以,市面上有一家耳熟能详的技术公司,
抓住了这个技术定位,
好好地提高了一把知名度。
这个定位就是:超长的模型上下文长度。
这是一个技术指标。
若不是竞争到如此激烈的程度。
我相信这个词不会这么出圈。
于是,同行们纷纷跟进。
你能塞一本书,是吧?
我能塞十本书。
总之,文本量的提高,模型能力也提高。
没有人会嫌大模型能力高,
只有花钱的时候嫌多。
4K,8 K,32K,128K,200K……
数字后面的单位是Token(词元) ,
大语言模型的上下文长度通常以Token为单位,
专业词汇嘛。
逛街买菜用不上,
咱就追求一个,
聊天不露怯。
毕竟,只有工程师们在低头干活。
于是,3.4K常见(Qwen1.5-110B版本),
4K也常见(Yi-1.5)。
豆包通用模型Pro一把放出32K版本。
Claude3挑战100万长度的Token。
GPT-Turbo整一个128K,
Deepseek开源模型也有128K,
Gemini1.5 Pro则在2024年5月16日,推出200K版本。
而Kimi很早就20万汉字
(Kimi的单位是汉字,不是Token),
甚至早到了2023年10月。
我这里所列并不全面,
主打一个围观“战况”,
反正就是,你长,我比你更长。
从某种程度上,“长”意味着聪明。
但也不全是,因为没有考虑有没有漏掉信息。
这需要一种专门的测试,叫“大海捞针”,
这又说远了。
长和短的成本非常不一样。
当年看8K也不短,
而今一顿呼呼涨。
Token渐长迷人眼,
再看看价格,
GPT-4的价格,
32K比8K贵了一倍。

贵是成本显著上升了。
当模型效果一样,
Token的价格也一样,
谁家成本低,
谁家赚大钱。
那么问题来了:
(三)
把推理成本降下来,还有哪里能发力?
我考虑,先讲两个答案,
第一,拼芯片。
第二,拼推理基础软件技术水平。
后面,会分别讲两个代表性厂商。

很显然,最见效果的是芯片。
芯片是个老话题了。
第一,从赚钱的角度,
推理芯片值不值得单独做?
只要推理市场足够大,
就可以单独去单开一类芯片了。
这点我就不论证了,
线报是,
很多人默默地没吭声,
把推理芯片的故事写在给投资人的BP里了。
话说,造芯片,
研发费用分为很多种:
IP,EDA,人力,投片。
另有生产成本。
请仔细看清这些成本,
后面也不会再讲了,
因为讲也没用,
芯片只要出货量足够大,
成本都不是事。
再说,谁让英伟达猛烈的股价,
将AI芯片的格局打开。
第二,从技术角度,
推理芯片能不能单独做?
省流版的答案:
能做。
训练和推理是不同的“技术KPI”。
这就引出了两个选项:
在英伟达的大蛋糕上,
要么正面硬刚,训练推理一起抢。
要么只抢推理的蛋糕。
在大语言模型的超强刺激之下,
推理要抓什么重点?
这真是个好问题,
在前一篇文章里,我大概讲了,
推理的痛苦面具是,那种重复计算的冗余量非常大。
又重复,又大,那肯定快不了。
还要在有限带宽的条件下,算快点。
不过,不同厂商工作的侧重不同。
谭婧老师我,
近距离观察了两个厂商,
一家是芯片+模型,
一家是应用+模型。
第一家,
近在咫尺,
国内互联网某头部厂商,
在它这个生态位上,
推理上的活,不用像芯片公司那么累,
但可干的事情也很多,
哪个大厂商敢不好好优化推理?
若用两种不同的芯片,
那就麻烦您受累熟悉两套不同的系统。
即便是场景没爆发,
推理技术必须提前几步,
早做打算
(易用性,支持各大主流模型,
CTR超长上下文推理加速)
若场景爆发,压力更大。
我走访后,了解到这些。
第二家,
大洋彼岸,
美国芯片公司SambaNova,
简单说,芯片性能强,
所有人都变强了。
芯片果真是,
阳光普照,人人需要。
某国产AI芯片初创公司产品总监Winnie常对我说:
“只要硬件加速,任何一种负载都能受益。”
她对SambaNova芯片的评价是,
在所有的设计中,
它把堆料(有什么好东西都用上)
和创新(搞数据流等)全都做了,
是典型的“既要又要型”产品。
要我说,推理芯片的本质确实是既要又要。
既要抓住要害,也要锥刀之末。
要害有两个,
第一,用好高带宽内存(HMB),
第二,完备的存储架构。
用不用HMB?
决不能犹豫。
谁犹豫,谁后悔。
比如,他家的芯片发展到SN40L这一代的时候,
HBM已经给足了(64 GB)。
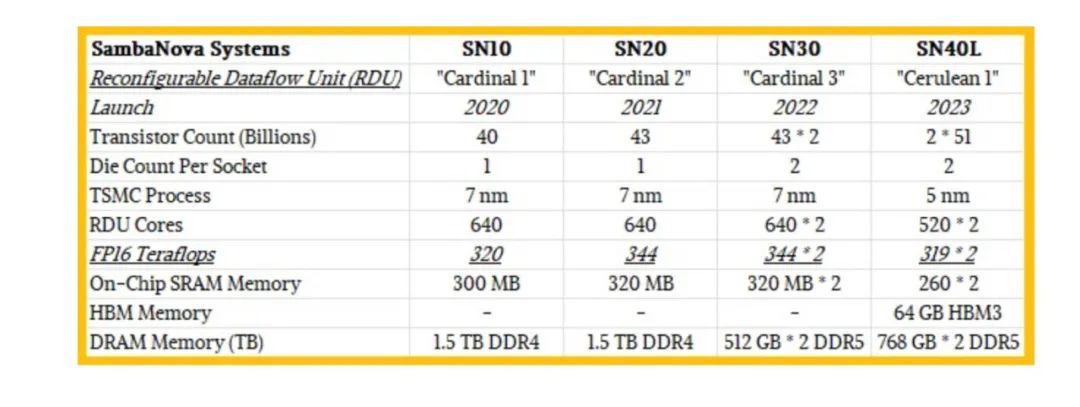
这还不够。
完备的存储架构(三级)必不可少。
至于锥刀之末,
正如公司CEO Rodrigo Liang说的:
“优化是平衡资源分配的过程”。

平衡这事,很微妙。
能做的事情就太多了
(片上做数据并行,HBM带宽打满,算子融合等)。
SambaNova全栈厂商,
有模型,有硬件,
软硬配合起来,有天然优势。
文章的最后,吴恩达在推特上还说了一个预测,
他引用美国投资公司ARK的观点。
推理成本的下降速度(每年下降86%),
比训练成本下降得更快(每年下降75%)。
花钱少了,用户高兴,
想要过上这种钱少效果棒的好日子,
推理还要好好发力。
(完)
One More Thing
吴恩达推文信息量挺大,
虽然字小。

(完)

《我看见了风暴:人工智能基建革命》,
作者:谭婧
















 972
972











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









