







原创:谭婧
模型参数规模,
越大越好,
有些人把大当做目标,
但这不是答案。
往更大规模训练,
就是还期望效果还能更好,
把“智能上限”往上推。
这个趋势在Llama3.1旗舰模型这里,
到达一个新顶峰。
的确,Llama 3.1 405B太大了,
由大而来的技术难度摆在这里。
上一次的参数量大的历史是英伟达创造的,
2024年6月16日,
英伟达的开源大模型Nemotron,
有3400 亿参数。
再往前,上上一次破参数规模记录,
是马斯克 xAI的记录。
2024年3月17日,
Grok-1模型发布,拥有3140亿参数。
现在模型的发布速度就和1130近防炮一样。
已经不想用“最强”或者“最大”这个词了。
新的纪录,
几个月内就会被打破。
有了Llama3.1旗舰版,
会有哪些变化?
第一种企业,
一直在训练大模型的厂商,
哪怕水平不行,
这次借机可以给模型换底座,
第二种企业,
我有个超级APP,或者我有企业业务,
有很多用户,
从Llama2的API换成Llama3.1旗舰版的API,
我用模型的成本会增高。
有多高?
贾扬清的团队拉起来测了一把,
于是在推特上面算了一笔经济账账:
《Accounting report on llama3 tokenomics》,
他对风投朋友们说:
这个价位的纯API服务,
请不要期待像传统Saas那样80%的利润。
没办法,
模型这么大,
推理的成本也会很高。
接下来需要优化工作一步一步把成本降下来,
但是,需要时间。
吴恩达说一年推理成本能降86%。
前提是Llama3.1旗舰版模型的市场足够好,
才有人愿意干降成本这件事。
第三种企业,
就是各大平台,
立马对Llama 3.1“光速支持”。
云计算厂商,
AWS的SA小哥哥,
当天发了个朋友圈,
说:“Llama3.1已经在AWS Bedrock上可用。”
阿里云宣布,百炼平台限时一个月,
为所有用户提供免费算力额度,
玩转Llama3.1训练推理。
第四种企业,
AI芯片公司,
英伟达的老对手,
美国硅谷AI芯片厂商的技术大牛,
亲口告诉我:
“这是最忙碌的几天,
405B在我们机器上跑起来了。”
还有另外一家美国芯片公司,
倒是十分可笑,
推理卡堆成了奇观。
推理用了2000张卡,
对,你没有看错,
不是20张,
是2000张。
公司网站都崩溃了,
还装模作样在X上宣布:
“试玩者的热情涌入,
Llama 3.1 405b体验暂时关闭了。”
难道不是因为,
片上存储(On Chip Sram)方案不行,
卡太多管不好,
崩溃了吗?
这家公司我先不实名,
日后爆料。
第五种企业,
模型太大了,
没有条件,
搞不起来。
不出意外的话,
Llama3.1出不了什么意外。
工作是一如既往的扎实,
甚或,步步上大分。
规模就不用说了,
技术分享也很实诚,
动不动就92页《报告》。
用ChatGPT投币会员网页版翻译都吃不消,
只有调API来翻译。
01.
如今,优秀的大模型训练团队,
对训练方法的探索都是极致和疯狂的。
甚至可以说,
一切都为了探索训练方法。
4050亿参数模型的训练,
对Meta AI团队也是一次灵魂的远航。
无论成功还是失败,经验同样重要。
激发灵感的线索,
有可能在任何不起眼之处。
经验就是商业秘密。
毕竟,
经验来自于真金白银(GPU卡)的消耗。
《报告》多次用旗舰模型指代Llama3.1模型。
而这个系列模型,
参数规模分别为8B(80亿)、
70B(700亿)和405B(4050亿)。
旗舰版是系列中最强大、性能最好的模型。
万卡训练的法门很多,
现在很是比拼这个。
他们总结了三大重点。
正如《报告》中所写,
他们相信开发高质量基础模型需要三个关键杠杆:
数据、规模和管理复杂性。
在开发过程中格外重视优化这三个杠杆,
万卡法门里的核心技术,
有大有小,
谭老师我发现了一个小问题,
很值得讨论。
照旧,
我请教了很多人,
在我看来,
武汉人工智能研究院的易东博士
和另一位谭博士的讲解,
让我颇有收获。
谭博士坚持文中不实名,
那就成了,谭老师讲谭老师如何讲。
禁止俄罗斯套娃梗,
怎么办?
他说让我凉拌。
聊回来,
关于如何设计训练中的评估方法,
发现问题,搞懂问题,
也小有成就感了。
那么他们Llama3.1模型团队是怎么做的呢?
又到了英语阅读时间,
先看以下原文。
英文: our flagship model outperforms smaller models
trained using the same procedure.
中文: 我们的旗舰模型在各种任务上
超越了采用相同训练流程的小型模型。
英文: While our scaling laws suggest our
flagship model is an approximately
compute-optimal size for our training budget.
中文: 虽然我们的缩放律表明,
在给定训练预算下,
我们的旗舰模型的规模接近计算最优。
英文: we also train our smaller models
for much longer than is compute-optimal.
中文: 但我们仍对小型模型进行了更长时间的训练,
超出计算最优的计算。
英文: The resulting models perform better than
compute-optimal models at the same inference budget.
中文: 结果表明,这些模型在相同推理预算下表现优于计算最优模型。
英文: We use the flagship model to further improve
the quality of those smaller models during post-training.
中文: 我们利用旗舰模型在第二次训练阶段,
进一步提升了小型模型的质量。
为什么多了一个小模型?
这个小模型和4050亿参数大模型什么关系?
思考是,
在给定训练资源的前提下,
想通过实验观察,
大模型的训练成本太高,
小模型的成本就小了很多。
那就一大一小对比。
于是,
他们蒸馏了一个小模型,
原文是:
“我们利用旗舰模型在微调阶段进一步提升了小型模型的质量。”
蒸馏的原理是用一个大模型教会小模型“知识”。
他们观察后发现,
蒸馏效果如预期的好。
也就是“教学质量”好,
Llama3.1旗舰模型是个好老师。
小模型学成毕业了,
那存在的意义是什么?
答案是:便于观测大模型。
因为小模型本身并不是观测的重点,
而是借助小模型,观测大模型。
用小模型验证大模型的一些可能性。
小模型内心OS:“咱就是陪跑工具人”。
这时候,
Scaling law(缩放法则),等比缩小一个模型,
然后,计算小模型的相关实验数据,
目的都是为了观测和验证大模型。
每个尺寸的模型的最优点不一样,
正如刚才所说,先拿一个小模型,
训练出它的最优点。
再给小模型继续增加训练时间,继续观察。
反正,同一个小模型可以训练很多次。
同时,训练资源是一定的,模型变小了,
训练时间是一定的,迭代次数更多。
比如,预算1000张卡,一个月,
小模型迭代2万次,
大模型只能迭代1万次。
相当于,大模型有一个观测指标。
再拿小模型计算同样的观测指标。
有两套观测指标。
02.
我们锚定的观测点是什么?
问这个问题的时候,
有一个叫做“最优点”的东西被引进了。
本质是围绕着这两件事:
给定尺寸估计算力,
给算力估计尺寸。
“最优点”是个预估数据。
大概就是,
用多大规模数据比较好,
训练什么程度,
模型多大,
找到最佳的一个点。
如果超过了“最佳点”你再继续训练,
模型性能提高的性价比也不高了。
我们知道,
Scaling law(缩放法则)是一条曲线,
最优点就在上面。
除了缩放法则,
估计的依据是什么呢?
每个模型的曲线都不是一模一样。
他们可以用来估计的就是,经验,
以前积累的有关模型尺寸经验。
可能4050亿参数就是一个预估出来的尺寸值,
估计完了之后,
就用固定的算力来训练,
(原文中指3.8 × 1025 FLOPs)。
这么大的算力,Meta公司这样的豪门,
也只能承受训练一次。
所以,4050亿参数大模型跑出来的尺寸值,
只有一套。
不过,没关系,
好点子来了,
那就再用小模型来多跑几套尺寸值,
用来参考。
毕竟,
增加实验数据,
能够增加对客观规律的理解,
增强对所观察到的规律的信心。
谁不想增加对4050亿参数模型的理解呢?
对女(男)友的理解恐怕都要往后放。

实验数据宝贵。
一次不够,
多跑几次。
延长训练时间地跑。
大模型,训练30天,
小模型,训练40天。
小模型用较少代价就能“跑出”出一个最优点,
或者还有个方法,
用最优参数来训练。
无论什么方法,可用小模型跑出好几套“数据”来。
小模型跑出来一个“最优点”,
这是一个实际的值,不是预估的。
如果实际的值和预估的值不一样,
就可以作比较。
《报告》里没有说明405B的,
“估计最优点”和“实际最优点”,
到底有何区别。
有一种可能是,
他们跑完发现,
按照缩放法则和经验,
给4050亿参数模型估计出的“最优点”,
有可能保守了。
或者说,
Llama3.1旗舰模型模型参数还可以更大。
假如两个“最优点”吻合,
可以直接在《报告》中公布这个结果。
很可能是不吻合。
令人遗憾的是,
GUP卡数有限,
时限也到期了。
本文中,
谭博士和易东博士观点一致,
谭博士给了我“简约”和“学术论文”两个版本:
简约版:
他们先有一个计算最优点,
再用小模型去训练计算最优点,观察效果,
最后,超过计算最优点,继续训练,
观察效果。
学术论文版:
通过实验观察到的不同规模模型的性能,
与训练计算量之间的关系,
再给定训练预算下,
来预测模型规模与性能之间的最好平衡点。
要我说,就好比一辆车在路上狂奔,
前方有一个车站(观测点)
观测点早早有一堆人在那里等着拍照。
超大车以一定速度跑过某个车站。
再用小车一趟一趟放开车速跑过这个车站。
因为大车太耗能源,
只能跑一遍。
小车多跑几趟。
相当于,大和小做配合性实验。
Llama3.1是个语言模型,
更专业的说法是,
多语种语言模型,
多语言就是能够处理多种语言。
而他们团队的探索工作,
绝不局限于语言。
还探索了语音,多模型,端到端等多种维度。
这次报告,
探索精神特别强。
(完)
One More Thing
所谓的才华是基本功的溢出,
处理训练中的“崩溃”,
也是一种基本功。
英伟达GPU计算集群管理难度实在太高,
当之无愧高科技里的高科技。
他们团队经历了什么样的崩溃呢?
他们制作了详细的表格:
Llama 3 405B模型54天的预训练期间,总共发生了417 次意外中断。
主要原因也列出来了包括:
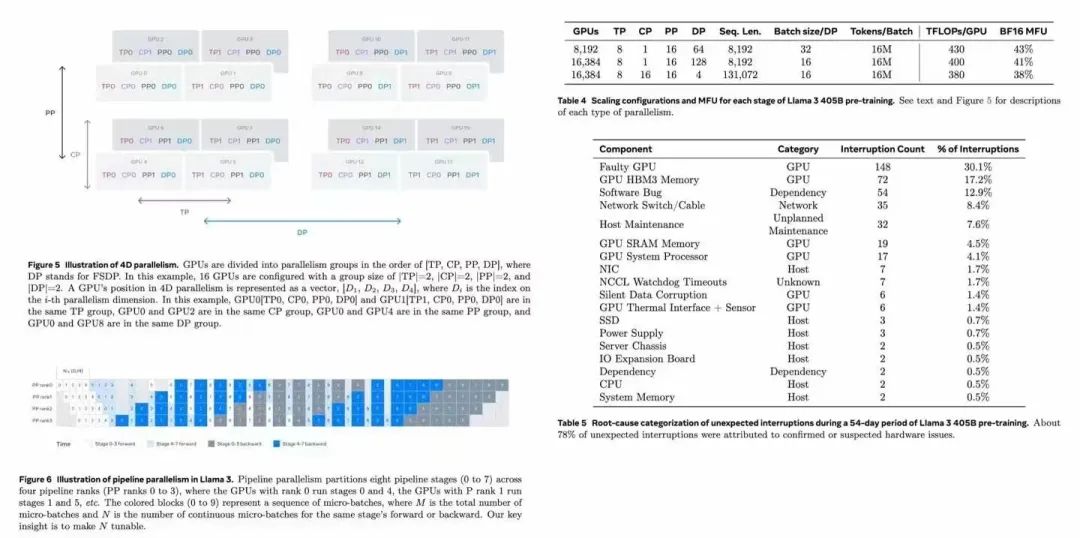
1、GPU故障: 148次 (30.1%)
2、GPU HBM3内存: 72次 (17.2%)
3、软件Bug: 54次 (12.9%)
4、网络交换机/线缆: 35次 (8.4%)
5、主机维护: 32次 (7.6%)
6、GPU SRAM内存: 19次 (4.5%)
7、GPU系统处理器: 17次 (4.1%)
8、NIC: 7次 (1.7%)
9、NCCL看门狗超时: 7次 (1.7%)
10、静默数据损坏: 6次 (1.4%)
11、GPU热接口+传感器: 6次 (1.4%)
此处,心疼小扎一秒。
再多也不行。

《The Llama 3 Herd of Models》
标题可以直译为Llama 3 模型家族。
原意为“牛群,羊群,或者兽群”,
“Herd”这个词,
不仅准确地表达了多个模型的集合,
还很生动,形象地说这个系列模型多样性。
报告看得细,比较慢。
最后,扫到报告里有半句话,
“我们希望旗舰模型的公开发布能够激发研究界的创新浪潮
We hope that the open release of a flagship model will spur a wave of innovation……“
肯定激发了创新。
都多余说这句话。
在这么一个激动人心的时期,
说这话,一点氛围感都没有调动起来。
此时此景,当吟诗一首:
远看模型大,近看大模型,
模型真是大,真是大模型,
停停停……
换个画风,
每一次AI模型的大进展,
都像一条河,
把我们和过去永远分开了。

更多阅读:
《作者直到最近才费劲弄清楚的……》
2.AI推理红海战:百万Token一元钱,低价背后藏何种猫腻?
3.质疑美国芯片Etched:AI领域最大赌注的尽头是散热?
长文系列
4. 假如你家大模型还是个二傻子,就不用像llya那样操心AI安全
6. 对话百度孙珂:想玩好AI Agent,大模型的“外挂”生意怎么做?
7. 再造一个英伟达?黄仁勋如何看待生物学与AI大模型的未来?
8. 科大讯飞刘聪:假如对大模型算法没把握,错一个东西,三个月就过去了
9.美国AI芯片公司“赢”大模型?Samba-CoE v0.2超过多个业界知名对手
11.如何辨别真假“AI刘强东”?10亿参数,数字人实时生成视频
漫画系列
5. AI大模型技术路线之争:你可以信仰多模态,也可以无视多模态
《我看见了风暴:人工智能基建革命》,
作者:谭婧
















 424
424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









