








先说重点,
GPU计算不能等,网要好。
到底用哪种网,
这个问题成了关键。
而且,还有人误会网络不重要,
我得知:
一家国产知名大模型厂商,
就不说哪家了,
买了英伟达一万张卡,
配的PCIe接口。
送命不至于,
就是吃亏。
我判断:
2024年全球头部GPU技术路标:
用超节点连起的10万卡GPU集群。
那么问题来了,卡之间的连接,
用什么网?
我还判断:
英伟达超节点(NVL72)引领下一轮组网架构,
除了英伟达以外的玩家,
他们往往被称为“非英伟达厂商”
该如何应对?
言下之意明了,
AI网络进入大争之世,
各自为战,还是联盟合作?
这篇文章将探讨,
多方玩家竞争与合作的可能。
目录:

(一)机内机外“过时了“?

故事开始了。
无论别人信不信英伟达垄断,
反正我信了。
当然可以说得保守点:
“有垄断之嫌”。
英伟达垄断了计算,
那是否垄断了网络?
在大规模GPU相互连接进行计算的情况下,
计算与网络紧密交织,
性能不再是一个单一的概念。
英伟达服务器内部网络是封闭玩法,
谁也不能自造一个网络,
跟英伟达的拼起来用。
俗称“拼桌。
不就是传输个数据包,还分派系了?
真是如此,
没办法,
科技厂商天然偏好各自为战,
因为终极都追求“垄断”。
如果哪天不这样了,
一定是有什么强大力量,
让他们痛苦了。
这是我一开始的想法,
只看到了其中一层,
现在我有了更深的理解,
后面会讲。

你看,数据中心里的AI网络,
网络分两种。
机内和机外。
不得不服气的是,
短短几个月,
我发现这种说法已经过时了。
没办法,技术又迭代了。
一个服务器是4卡8卡GPU的时期,
可以这样说。
然而,当NVL72这种超节点产品来了,
这个说法就不准了。
“机内机外”容易造成误解。
也就是,“机内机外”过时了。
这意味着,
一场新纷争悄然揭幕。
两句话说不清,
展开细聊。

话说回来,
GPU4卡8卡的时候,
机内互联,集成度高,
网络速度非常快。
打个比方,
一个服务器好比一间教室,
坐8个学生,互相传作业
相当于,8张GPU卡用NVLink相连。

然而,想和其他教室传作业,
网速就会慢。
有多慢呢?
服务器外的网络(机外网络),
比机内网络慢了一个数量级。

除了快慢,
还有价格,
机内网络比机外网络贵多了。
结果很清楚,
英伟达赚了好多钱。
强需求,
又推着GPU了上了一新台阶。
英伟达拿出了产品GB200 NVL72,
下文简称NVL72。
这个产品一出现,
就引领了一个新方向,
在计算集群中,
每个节点通常包含多个 GPU 和处理器。
这里提到的 " NVL +数字" ,
指的是一个超大节点中GPU数量。
NVL36的节点有36个GPU。
同理,NVL576的节点有576个GPU。
让人生气的是,
国产暂时没有能比肩的。
不过谭老师我可以喊话国产厂商:
“等着用,搞快点”。

英伟达NVL72的机柜就像一个大冰箱。
内部也挺复杂,
有72个GPU分别放在18张计算卡上,
一个计算卡,其实就是一个Tray(托架)。
而一张计算卡,
相当于一台服务器。
这样,每张计算卡里有4个GPU。
口算4 X 18=72,
相当于装了72个GPU。
网络也非常好,
72个GPU工作起来像一个。
这个东西再叫服务器,就不合适了,
那就叫超节点吧。
于是,新问题来了,
请问,这个超节点里面72个GPU用的什么网络连接?
答案是选A,还是选B?
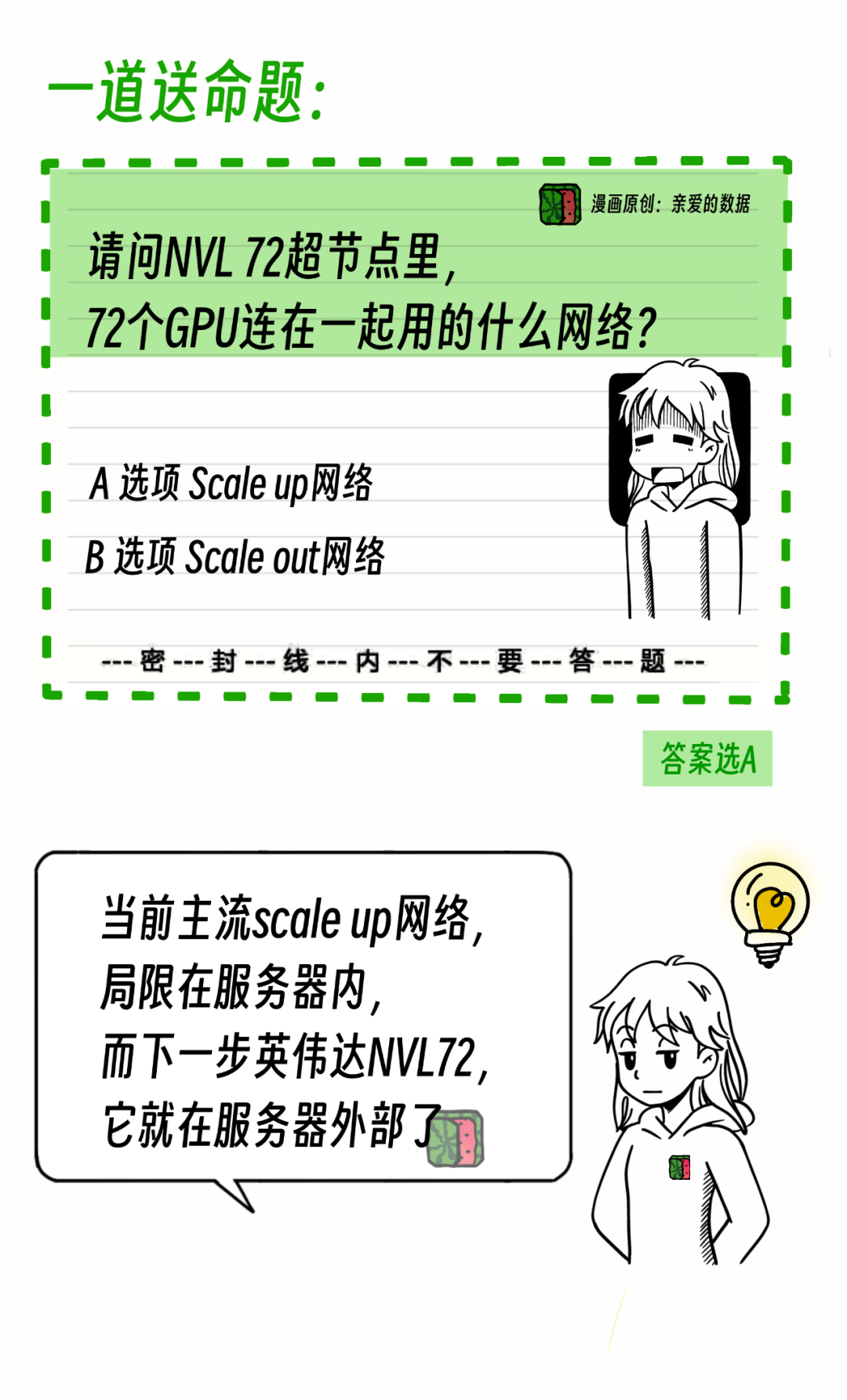
没搞错吧?
以前,机内和机外网络。
以前,8个以上GPU就是Scale out网络,
现在72个GPU了,
理应仍然是Scale out网络。
为什么是Scale
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2647
2647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









