






原创:谭婧
指导教授:王金桥,张家俊
白天有太多干扰,
某日临睡前,和一位百度的朋友聊几句,
我说了一句:“不把DeepSeek写爽,我不想开别的选题。”
还配上了态度的表情包,
朋友回复说,他要笑死了。

DeepSeek那几篇论文和技术报告,
于我而言,常看常新。
吃不吃的透是其次,态度要有,
学习是最好的致敬。
思考中,我反复陷入旧思路,
需要在王金桥,张家俊教授(武汉人工智能研究院)的多次提醒下,重新理解,推理大模型的出现,迫使之前玩法都变成“传统模型”,推理大模型的大门已经打开,你进不进,它都在那里。
跪谢DeepSeek,“开源推理大模型”套路开创者,
一把节约几年的时间,
一起跨入“推理大模型”的大门。
一番新景致,好不淋漓畅快。
01
先讲,什么是思维链吧,
这是推理大模型的一种能力。
好家伙,一句话包括两个新名词:
“思维链”“推理大模型”,
热门话题,很多人都讲了,
我不赘述,直接看例子。
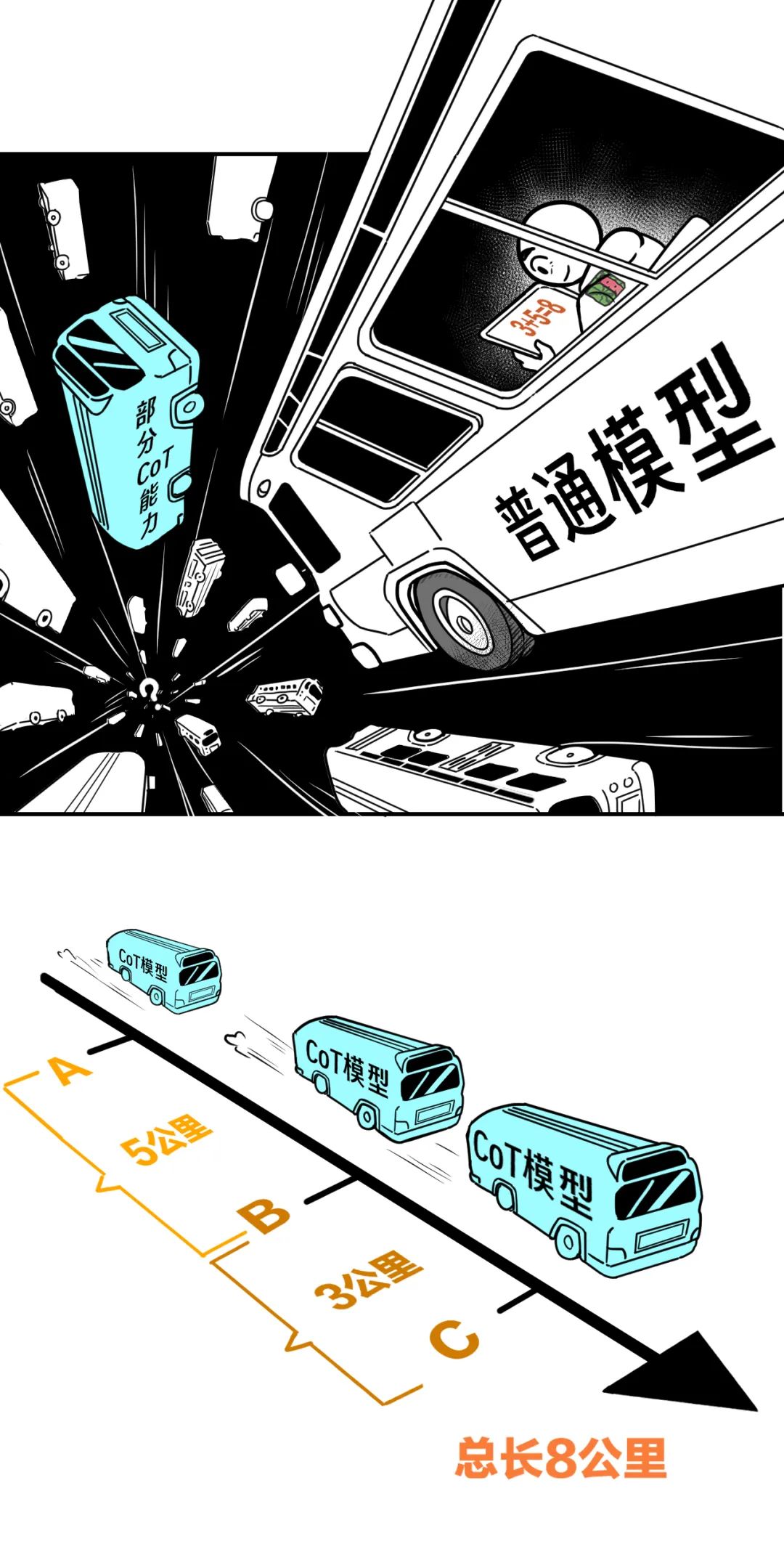
对比,普通模型和有思维链能力的模型。
题目:
车起点是A点,经过5公里后到达B点,
再经过3公里后到达C点,
请问车从A到C总距离是多少?
普通模型,直接回答:“8公里”。
答案虽然正确,但没有一步一步讲算的过程。
而有思维链(CoT)能力的模型,
回答时,有解题步骤和过程,
给出推理链条的各个环节。
回答:
从A到B距离5公里。
从B到C距离3公里。
所以,从A到C总距离是5公里加上3公里,
总共8公里。
推理大模型“给出解题过程”这件事,
在复杂的问题中显得尤为重要。
先说什么是“复杂”?
意味着,当我们需要多步推理,
多步解题、长篇逻辑推导的时候。
有人认为,给正确答案就行了,何必有步骤?
只给答案当然不够,
比如侦探破案,不仅要知道谁是罪犯,
还要知道是怎么推理出来的。
除了说服法官,你还要说服陪审团,
甚至赢得公众的理解和支持。
展示推理过程,能帮助别人理解这个过程,
学到关键,尤其在复杂问题中,
步骤和过程比单纯答案还能增强我们对结果的信任。日后反思,也知道错在哪里。
要我说,既然要顺藤摸瓜,
这个藤和这个瓜同样重要。
“藤”在这里是指的两件事情,
一个是“推理中的步骤”,也是“训练过程”。
好的,既然推理大模型这么重要,
那么问题来了,怎么得到它?
或者说,怎么得到世间最好的推理大模型?
02
能问出这个问题,真是志存高远,
因为相信,所以看见,
OpenAI O1做出来了,
DeepSeek也做出来了,
是首个复现OpenAI O1模型的开源模型。
国货之光,当之无愧。
有人吐槽,DeepSeek只有模型参数开源,
训练数据和训练过程并未开源。
先反驳一句,
这种开源方式在大模型领域本就主流。
这已经很Open了,
比OpenAI不知道Open到哪里去了。
“开源”模型并不意味着啥都告诉你。
那要不要手把手教会你?
在这个点上吐槽DeepSeek,完全忍不了。
而且,我在后文中亦会分析,
这样“有极高技术含量,
且依然成谜”的点,还有哪些。
前面提到的未开源的“训练过程”,
这是件很学术,很实验,很工程的事情,
“人话版”就是:“如何得到推理大模型?
DeepSeek得到了,且创新点密度之高,叹为观止。
而且会在整个训练过程中从头到尾不断出现,
这样“创新”含量极高的一个过程,
其本身也是一种创新。
所以,我想先写R1模型的训练过程。
而且,训练过程这件事,比蒸馏重要多了。
就技术含量来讲,
“蒸馏”和“训练过程”完全不在一个级别上。
在“训练过程”面前,
”蒸馏“充其量是低处好摘的果子。
因为R1在V3之后发布,且R1比V3更好理解,
想吃透,我的方法是:
学习顺序是倒序。
我写稿AI深度稿8年,
都没有信心把这几个模型吃透,
过去软弱的我已经死了,现在是更软弱的我。

话说回来,R1模型的训练过程,论文里虽有描述,
但业界仍然有不同观点。
咱们花开两朵,各表一枝。
先谈,我不同意的,
再谈,我同意的。
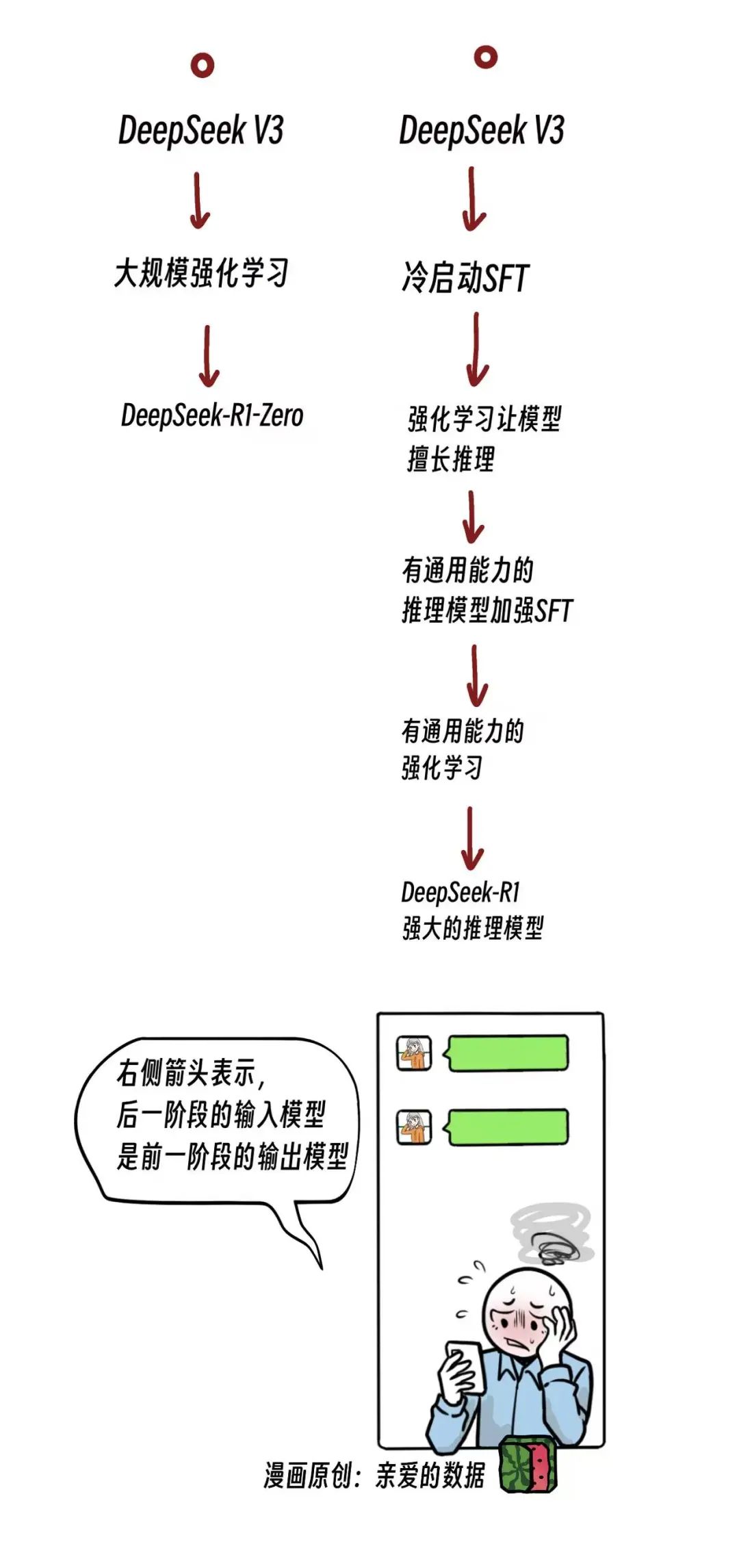
我观察到,整个训练过程中的一些中间模型,
它们并没有被接着训练下去,
其中一些甚至被“舍弃”了,
或者说好听点,“退休”了。
这时候,应该深度思考,
如果他们被构建出来之后,
并不参与下一个训练流程,
那他们被造出来的目的和意义是什么?
想通这点,才能算理解了这篇文章的核心。
回到我的结论,我不认为是R1的训练过程是下面这样。
03
再看第二种,我同意的训练过程,
整个训练过程,可转化为这样一套朴素的想法:

以上,是我理解了王金桥和张家俊两位教授核心观点后总结的,
细心的读者可能已经发现了,
这个过程正巧是一个人类思维链。
确实是用思维链解释思维链大模型的思维链。
(禁止俄罗斯套娃梗)
04

高质量推理数据的含金量还在增加,
到底怎么理解?
开个玩笑,拿来300集《名侦探柯南》,
全套《福尔摩斯》,这些也是推理数据?
当然不是,它们只含有推理的信息。
这么说推理数据吧:
是高难度数据,极难获得的高质量数据。
数据里面得有完整解题步骤,
得有各种推理方式,
得逻辑有连贯性;
这么好的数据哪里找?

回答这个问题,
先得知道一个著名的模型叫“R1-Zero”,简称Zero;
这种模型通过纯强化学习过程开发,
“激发”⼤型语⾔模型推理能⼒的潜⼒。
R1论文报告标题里也用的“激发”一词。
我管这种训练方法叫纯血强化学习,很特别。
不仅Zero的这个训练方法太特别了,
而且还有一个大用,就是造数据。
换句话说,整个过程中,不仅拿Zero来造数据,
造完数据Zero模型虽然已经宣布退休了,
但是造Zero模型的方法还在继续使用。
所以Zero一定要留下名字。
在易被忽略之处,还有一个没有名字的模型,
诚如开发者所愿,它连名字都不配拥有,
就叫“中间模型”吧,也可以叫“无名模型”。
中间模型存在的意义和价值,
就是构造第二个微调阶段所需要的高质量的数据。
而“无名模型”正是构建高质量(CoT)数据的幕后推手。这个模型可能并不直接负责输出最终的推理链,但它为后续的微调和优化提供了极为关键的支持:高质量数据。
也就是说为了造数据,
模型都专门训练了两种:有名的和无名的。
我不禁喟叹,DeepSeek:为了造数据,我造了模型,
电影《邪不压正》里姜文的声音,飘入脑海:
就是为了这点醋,我才包的这顿饺子。
冷启动(SFT)是什么意思?
一方面是说它用的数据特别少,才几千条。
无论多少,没有数据,这件事还是干不了。
这几千条数据谁帮忙造的?
答案是Zero模型。
没有Zero模型给你造数据,神仙也干不成。
第一阶段先冷启动(SFT),
然后用强化学习增强模型的推理能力,
尤其是在数学,代码上。
这时候,事情结束了吗?
当然没有,第一阶段后面是第二阶段,
这句话显然不是废话,
因为第二阶段对高质量数据的要求更大,
你也不能再冷启动一次了,
于是,又进行了一次第二阶段的SFT和强化学习。
细数一下,微调(SFT)和强化学习分别做了两次,前面讲了,第二阶段的数据,
比第一阶段的数据要求更多,
大约60万高质量推理数据,20万非推理数据,
V3还在中间当了裁判,
质量不行,看不懂的数据直接不要了。
这60万数据是精挑细选后的,
那没有挑选之前的数据哪里来的呢?
那个无名模型,也就是中间模型,
默默地支撑了。

这里可以插一句:
“有极高技术含量,且依然成谜”的点这里也有,
请问这20万数据的类型配比是啥?
这是一道思考题,也是一道实践题。
我们言归正传,下面怎么办呢?
又把V3拿来用了。
这时候,我们甚至可以再细数一下,
V3用一次,V3用两次,V3用三次,
才得到了R1这个模型。
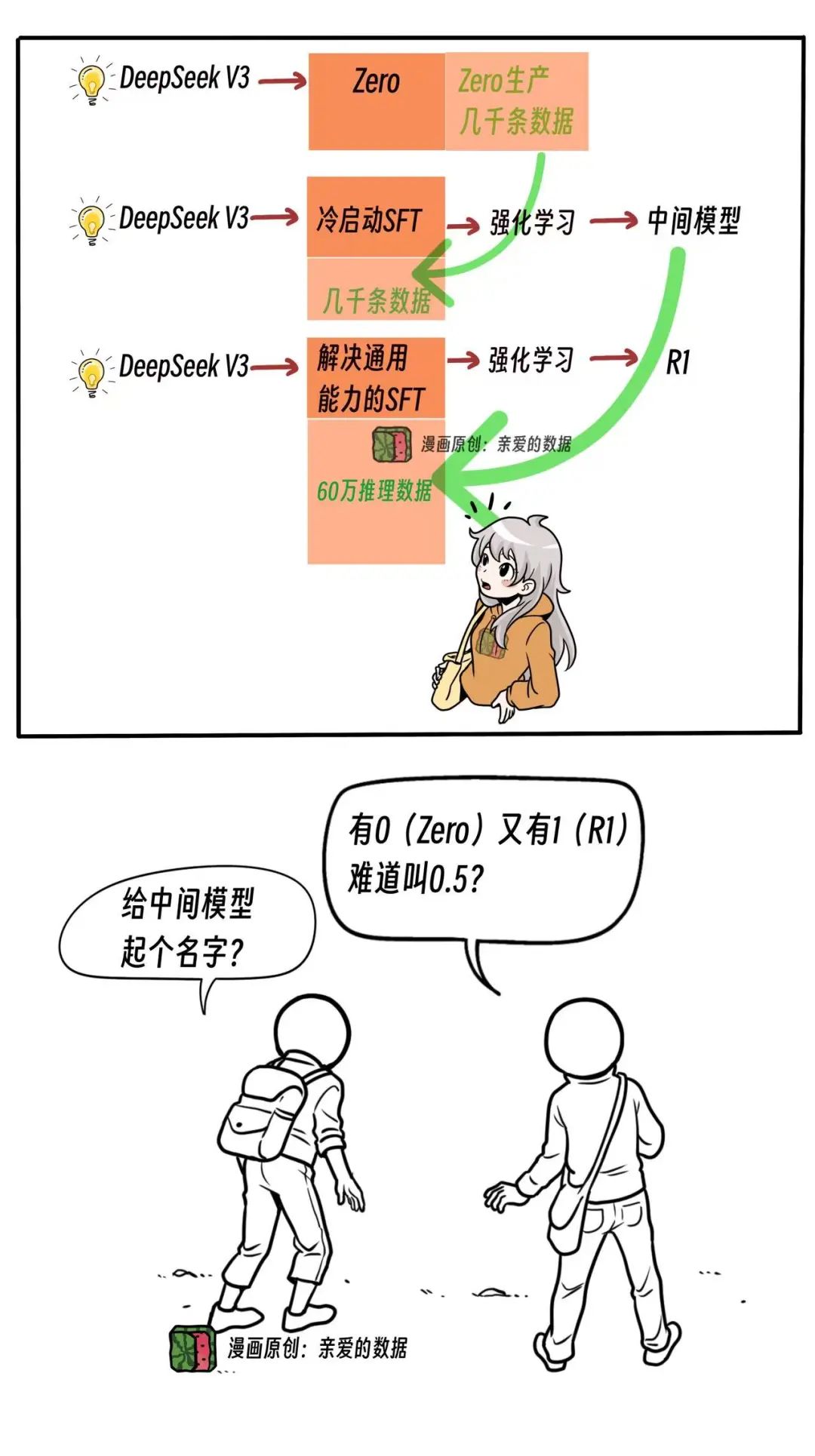
所以,R1它就像啥?
就像一个俄罗斯套娃,不对,是三个。
要我说,DeepSeek在训练方式上的独具创新之处在于,
每个人都想增强模型的推理能力。
而DeepSeek为它的增强推理能力,
造了一个模型,又造了“造数据的模型”,
还造了造模型造数据的方法。
张家俊教授的观点是:
“DeepSeek他们可能有一个信念,数学和代码等专用领域的推理能力可以泛化到通用。之前我们见到更多的,是先做通用,然后再训练专用能力成为一个专用模型,例如通用模型到行业模型再到场景模型。而这次通用领域推理能力的习得则采用了相反的思路,先搞定专用领域模型推理能力的学习范式,再由专用模型的推理能力牵引泛化至通用领域。”
“然后,虽然DeepSeek R1中如何构造高质量推理和通用数据至关重要,本质上R1 Zero是最大的创新。构建R1的整个过程可能也是不断尝试和折中的结果,最理想情况应该是希望R1 Zero就能实现通用领域推理能力的直接泛化,后来发现Zero只有专用推理能力,而且推理过程语言混杂可读性差,不过可喜的是能生产比较完整的推理数据了,那就退回经典的SFT+RL的范式,为了造更高质量的推理数据,就有了第一阶段的冷启动+Zero推理方法。”
如此独具匠心的设计,
有“因为相信所以看到”这样的信仰,
而我还停留在“因为看到,所以相信”。
这次就到这里,
很多时新酷炫的专业术语都被我删减了,
因为在此时此刻,它们都不重要。
这篇科普漫画看完已经发给我妈了,
又不是多难,别人妈妈会的,我妈也要会。
毕竟,她从小也是这么教育我的。
春节期间,我已经在饭桌上被狂轰乱炸了个遍,
从我妈到七大姑八大姨,
谁不想懂DeepSeek呢。
(完)
One More Thing
我知道有的数据团队在爬我公众号上的内容,
感谢视其为高质量数据,
说实话,我不愿意,
而又无力阻止。
我能做的就是,精品和核心内容会更多的向漫画上迁移,
一方面文章更好看,
另一方面,想把数据拿走,
你们就得必须再接一套Caption方案;
效果好不好,不知道了,
反正成本是更高了,
这可以视为,
我对AI版权问题有声的抵抗。

更多阅读:
《作者直到最近才费劲弄清楚的……》
2.AI推理红海战:百万Token一元钱,低价背后藏何种猫腻?
3.质疑美国芯片Etched:AI领域最大赌注的尽头是散热?
5.对抗NVLink简史?10万卡争端,英伟达NVL72超节点挑起
6. 硅谷访客丨谁在“掏空”深度学习框架PyTorch?
长文系列
4. 假如你家大模型还是个二傻子,就不用像llya那样操心AI安全
6. 对话百度孙珂:想玩好AI Agent,大模型的“外挂”生意怎么做?
7. 再造一个英伟达?黄仁勋如何看待生物学与AI大模型的未来?
8. 对话科大讯飞刘聪:假如对大模型算法没把握,错一个东西,三个月就过去了
11. 如何辨别真假“AI刘强东”?10亿参数,数字人实时生成视频
12. 智谱清影做“Stable Diffusion”,生数科技做“Midjourney”?
漫画系列
5. AI大模型技术路线之争:你可以信仰多模态,也可以无视多模态
6. 独家丨科大讯飞多模态:都说端到端好,看谁有本事先做出来
7. 硅谷访客丨AI大模型垂直整合:我有一条龙服务,我就是那条龙
AI安全
1.假如你家大模型还是个二傻子,就不用像llya那样操心AI安全
2.前所未有:GPU集群恶意代码注入?模型投毒?资源消耗攻击?



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









