






这个爬虫主要利用scrapy+beautifulsoup完成,其中图片保存碰到了一个大坑,花了一天的时间才解决。
大坑就是:在抓取文章页指定区域所有图片的时候,刚好那块区域的图片所有页面都一样,导致图片下载完第一个页面的时候,其他页面就不会再去下载了。所以其他文件夹里没有图片数据。一开始以为代码写错了,最后换了个地址才找到原因,ImagesPipeline实现图片下载中 同样的图是不会重复下载的!
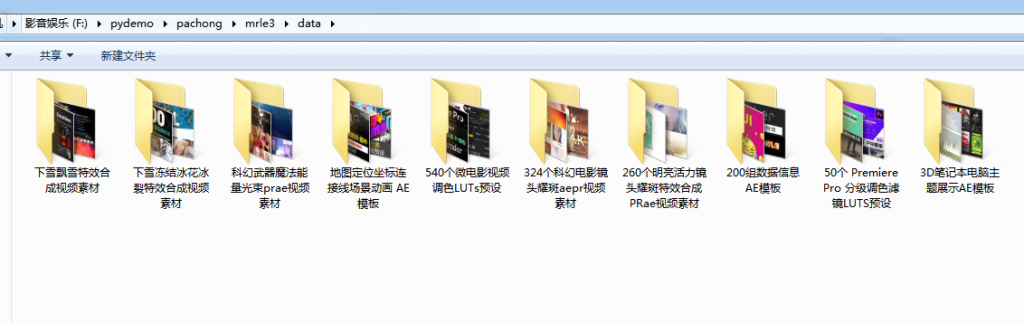
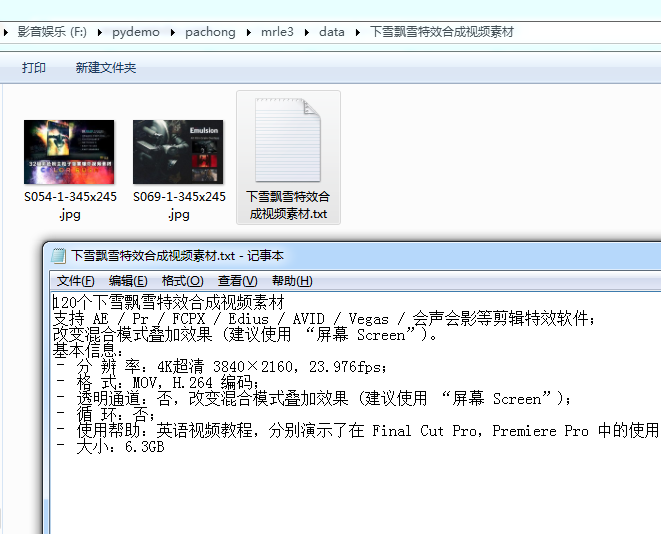
成功后的效果图如下:
items.py文件代码编写
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class mrle3Item(scrapy.Item):
#定义一个类mrleItem,它继承自scrapy.Item
picurl = scrapy.Field()
title = scrapy.Field()
wenzi = scrapy.Field()
link = scrapy.Field()
video = scrapy.Field()
urls = scrapy.Field()
setting.py 代码编写
# -*- coding: utf-8 -*-
# Scrapy settings for mrle project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'mrle3'
SPIDER_MODULES = ['mrle3.spiders']
NEWSPIDER_MODULE = 'mrle3.spiders'
#存储路径 决定文件存储在哪个文件夹下面
IMAGES_STORE = 'data'
# 定义接受图片的变量
IMAGES_URLS_FIELD = 'urls'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
'User-agent': 'Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2733
2733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









