





模型加速越来越成为深度学习工程中的刚需了,最近的CVPR和ICLR会议中,模型的压缩和剪枝是受到的关注越来越多。毕竟工程上,算法工程师的深度学习模型是要在嵌入式平台跑起来,投入应用的。在模型的推理(inference)过程中,计算速度是很重要的。比如自动驾驶,如果使用一个经典的深度学习模型,很容易就跑到200毫秒的延时,那么这意味着,在实际驾驶过程中,你的车一秒钟只能看到5张图像,这当然是很危险的一件事。所以,对于实时响应比较高的任务,模型的加速时很有必要的一件事情了。
如果你使用英伟达的产品,比如PX2,那么在平台上部署模型投入应用,很多时候就需要用到专门的模型加速工具 —— TensorRT。
TensorRT下的模型是在做什么?
TensorRT只负责模型的推理(inference)过程,一般不用TensorRT来训练模型的哈。
TensorRT能加速模型吗?
能!根据官方文档,使用TensorRT,在CPU或者GPU模式下其可提供10X乃至100X的加速。本人的实际经验中,TensorRT提供了20X的加速。
TensorRT为什么能提升模型的运行速度?
TensorRT是英伟达针对自家平台做的加速包,TensorRT主要做了这么两件事情,来提升模型的运行速度。
- TensorRT支持INT8和FP16的计算。深度学习网络在训练时,通常使用 32 位或 16 位数据。TensorRT则在网络的推理时选用不这么高的精度,达到加速推断的目的。
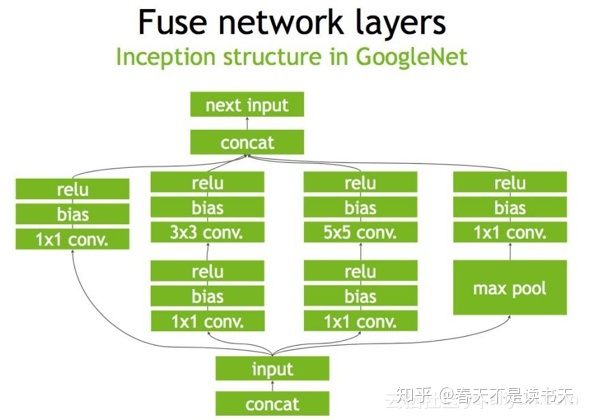
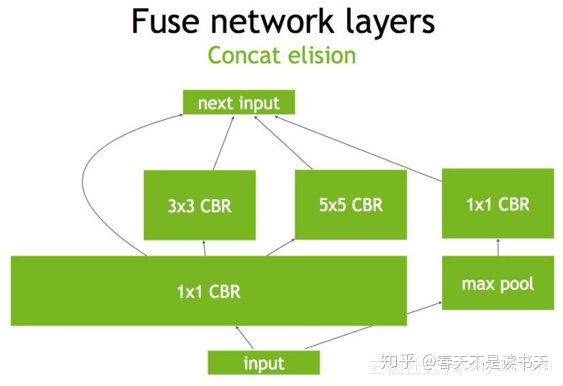
- TensorRT对于网络结构进行了重构,把一些能够合并的运算合并在了一起,针对GPU的特性做了优化。现在大多数深度学习框架是没有针对GPU做过性能优化的,而英伟达,GPU的生产者和搬运工,自然就推出了针对自己GPU的加速工具TensorRT。一个深度学习模型,在没有优化的情况下,比如一个卷积层、一个偏置层和一个reload层,这三层是需要调用三次cuDNN对应的API,但实际上这三层的实现完全是可以合并到一起的,TensorRT会对一些可以合并网络进行合并。我们通过一个典型的inception block来看一看这样的合并运算。
在没有经过优化的时候,inception block是图1中的样子,一个既有深度,又有宽度,还有concat操作的结构。
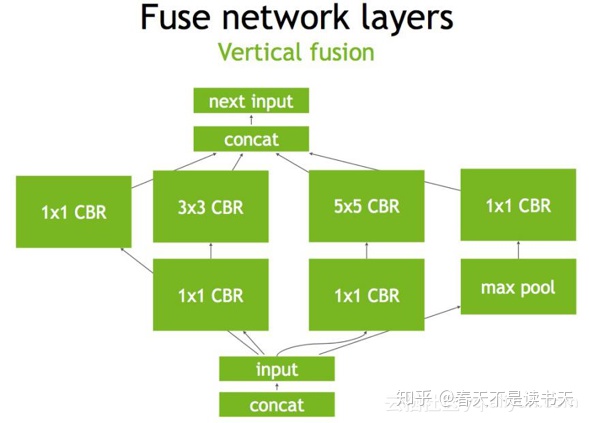
首先,对于网络结构的垂直整合,即将目前主流神经网络的conv、BN、Relu三个层融合为了一个层,所谓CBR,合并后就成了图2中的结构。
然后,TensorRT还可以对网络做水平组合,水平组合是指将输入为相同张量和执行相同操作的层融合一起,比如图3, 就将三个相连的1×1的CBR为一个大的1×1的CBR。
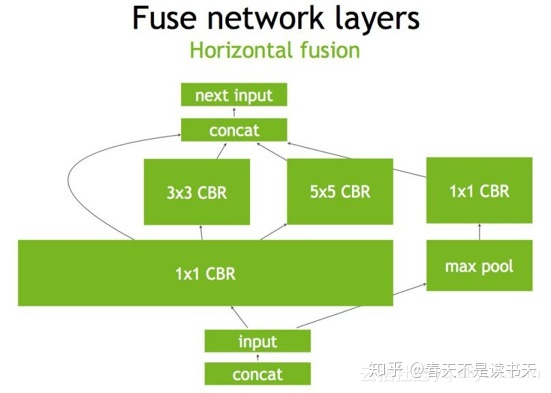
最后,对于concat层,将contact层的输入直接送入下面的操作中,不用单独进行concat后在输入计算,相当于减少了一次传输吞吐。
所以啊,如果你使用的是英伟达家的产品,TensorRT还是很推荐的呢!















 4816
4816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









