







 本文深入探讨了Xavier和He初始化方法在神经网络中的作用,解释了权重初始化的重要性,以及不当初始化可能引起的梯度消失或爆炸问题。介绍了PyTorch中10种权重初始化方法,并对比了Keras的实现。
本文深入探讨了Xavier和He初始化方法在神经网络中的作用,解释了权重初始化的重要性,以及不当初始化可能引起的梯度消失或爆炸问题。介绍了PyTorch中10种权重初始化方法,并对比了Keras的实现。
文章目录
两种初始化方法的Paper
【Xavier initialization Paper(2010)】:Understanding the difficulty of training deep feedforward neural networks
【He initialization Paper(2016)】:Delving Deep into Rectifiers:Surpassing Human-Level Performance on ImageNet Classification
1. 为什么需要权重初始化?
当定义好网络模型之后,需要进行权重初始化,恰当的权重初始化方法,可以加快模型的收敛,不恰当的初始化方法,可能导致梯度消失或爆炸,导致模型不可用。如果权重太小,则输入信号通过网络中的每一层时,其方差就会开始减小,输入最终会降低到非常低的值,导致梯度消失。如果权重太大,则输入数据的方差往往会随着每个传递层而迅速增加。最终,变得很大以至于梯度爆炸。
如果希望神经网络正常运行,则使用正确的权重初始化网络非常重要。在开始训练网络之前,我们需要确保权重在合理范围内,尽量控制在1附近。
2. Xavier 初始化
在开始训练之前分配网络权重似乎是一个随机过程,对吗?我们对数据一无所知,因此我们不确定如何分配在特定情况下适用的权重。一种好的方法是从高斯分布中分配权重。显然,这种分布将具有零均值和一些有限方差。
考虑一个线性神经元:
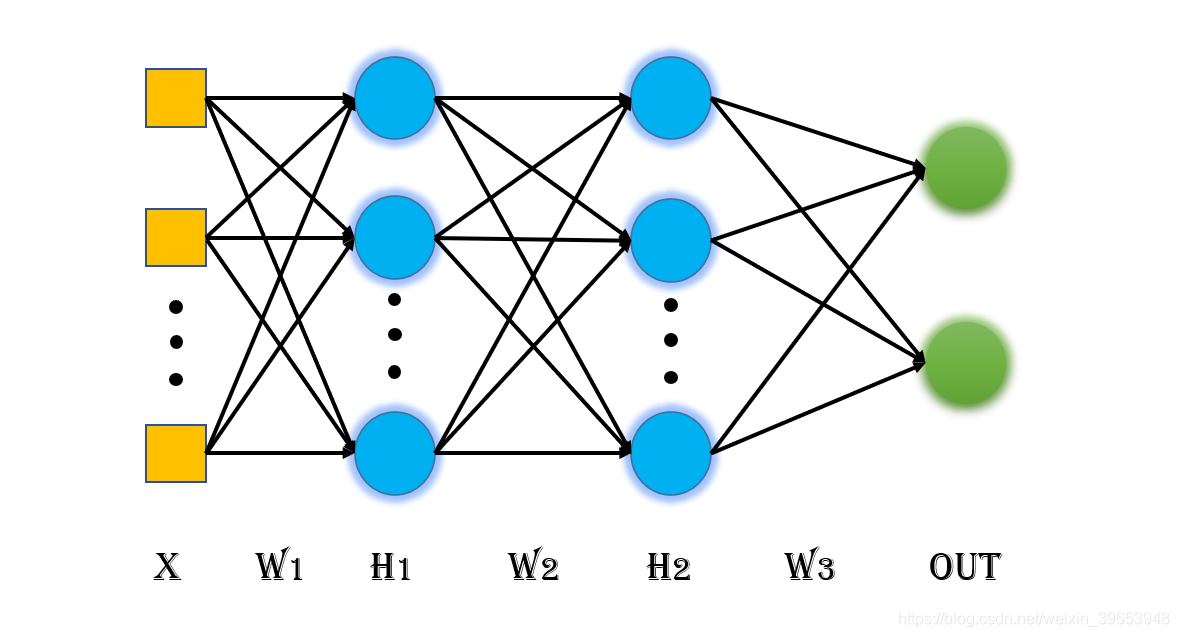
有下式成立:
- H 1 = H 1 ∗ W 2 H_1=H_1∗W_2 H1=H1∗W2
- Δ W 2 = ∂ L o s s ∂ W 2 = ∂ L o s s ∂ o u t ∗ ∂ o u t ∂ H 2 ∗ ∂ H 2 ∂ w 2 ΔW_2= \frac{\partial_{Loss}}{\partial W_{2}}=\frac{\partial_{Loss}}{\partial_{out}} * \frac{\partial_{out}}{\partial_{H_2}} * \frac{\partial_{H_2}}{\partial_{w_2}} ΔW2=∂W2∂Loss=∂out∂Loss∗∂H2∂out∗∂w2∂H2
- = ∂ L o s s ∂ W 2 = ∂ L o s s ∂ o u t ∗ ∂ o u t ∂ H 2 ∗ H 1 = \frac{\partial_{Loss}}{\partial W_{2}}=\frac{\partial_{Loss}}{\partial_{out}} * \frac{\partial_{out}}{\partial_{H_2}} * H_1 =∂W2∂Loss=∂out∂Loss∗∂H2∂out∗H1
【梯度消失】:
- H 1 → 0 ⇒ Δ W 2 → 0 H_1→0⇒ΔW_2→0 H1→0⇒ΔW2→0
【梯度爆炸】:
- H 1 → ∞ ⇒ Δ W 2 → ∞ H_1→∞⇒ΔW_2→∞ H1→∞⇒ΔW2→∞
假设:
y
=
w
1
x
1
+
w
2
x
2
+
.
.
.
+
w
N
x
N
+
b
y = w_1 x_1 + w_2 x_2 + ... + w_N x_N + b
y=w1x1+w2x2+...+wNxN+b
对于每个经过的层,我们希望方差保持相同,这有助于防止梯度爆炸或消失。换句话说,我们需要以使 x x x 和 y y y 的方差保持相同的方式来初始化权重,此初始化过程称为Xavier初始化(Xavier initialization)。(Xavier 读音 zeivier)
我们希望 方差(var) 经过每一层时保持相同,首先计算 y y y 的方差:
v a r ( y ) = v a r ( w 1 x 1 + w 2 x 2 + . . . + w N x N + b ) var(y) = var(w_1x_1 + w_2x_2 + ... + w_Nx_N + b) var(y)=var(w1x1+w2x2+...+wNxN+b)
有上图的神经网络可知有:
第一层隐藏层中有:
- H 11 = ∑ i = 0 n X i ∗ W 1 i H_{11} = \sum^{n}_{i=0} X_i * W_{1i} H11=∑i=0nXi∗W1i;
【推导过程】
由题意知, X X X 和 Y Y Y 是独立同分布的,则有:
- V ( X Y ) = E ( X ² Y ² ) − E ² ( X Y ) = E ( X ² ) E ( Y ² ) − E ² ( X ) E ² ( Y ) V(XY)=E(X²Y²)-E²(XY)=E(X²)E(Y²)-E²(X)E²(Y) V(XY)=E(X²Y²)−E²(XY)=E(X²)E(Y²)−E²(X)E²(Y)
又因为:
- V ( X ) = E ( X ² ) − E ² ( X ) → E ( X ² ) = V ( X ) + E ² ( X ) V(X)=E(X²)-E²(X) \rightarrow E(X²) = V(X)+E²(X) V(X)=E(X²)−E²(X)→E(X²)=V(X)+E²(X)
- V ( Y ) = E ( Y ² ) − E ² ( Y ) → E ( Y ² ) = V ( Y ) + E ² ( Y ) V(Y)=E(Y²)-E²(Y) \rightarrow E(Y²) = V(Y)+E²(Y) V(Y)=E(Y²)−E²(Y)→E(Y²)=V(Y)+E²(Y)
而:
- V ( X Y ) = E ( X ² ) E ( Y ² ) − E ² ( X ) E ² ( Y ) V(XY) = E(X²)E(Y²)-E²(X)E²(Y) V(XY)=E(X²)E(Y²)−E²(X)E²(Y)
- = [ V ( X ) + E ² ( X ) ] ∗ [ V ( Y ) + E ² ( Y ) ] − E ² ( X ) E ² ( Y ) = [V(X)+E²(X)] * [V(Y)+E²(Y)] -E²(X)E²(Y) =[V(X)+E²(X)]∗[V(Y)+E²(Y)]−E²(X)E²(Y)
- = V ( X ) V ( Y ) + V ( X ) E ² ( Y ) + E ² ( X ) V ( Y ) = V(X)V(Y)+V(X)E²(Y)+E²(X)V(Y) =V(X)V(Y)+V(X)E²(Y)+E²(X)V(Y)
回到原式,计算其方差有(因为偏差 b b b 为一常数,所以求方差为 0,故结果中不存在与 b b b 相关的项):
- V ( H 11 ) = ∑ i = 0 n = V ( X i ) V ( W 1 i ) + V ( X i ) E ² ( W 1 i ) + E ² ( X i ) V ( W 1 i ) V(H_{11}) = \sum^{n}_{i=0} =V(X_i)V(W_{1i})+V(X_i)E²(W_{1i})+E²(X_i)V(W_{1i}) V(H11)=∑i=0n=V(Xi)V(W1i)+V(Xi)E²(W1i)+E²(Xi)V(W1i)
因为有假设输入和权重符合零均值的高斯分布,所以期望 E ( ∗ ) = 0 E(*) = 0 E(∗)=0, 由此可以得到:
- V ( H 11 ) = ∑ i = 0 n V ( X i ) ∗ V ( W 1 i ) V(H_{11}) = \sum^{n}_{i=0} V(X_i) * V(W_{1i}) V(H11)=∑i=0nV(Xi)∗V(W1i)
又因为各变量都是独立同分布的,所以可以改写为:
- V ( H 11 ) = n ∗ V ( X i ) ∗ V ( W i ) V(H_{11}) = n * V(X_i) * V(W_{i}) V(H11)=n∗V(Xi)∗V(Wi)
进一步推到可得:
- V ( H 1 ) = n ∗ V ( X ) ∗ V ( W ) V(H_{1}) = n * V(X) * V(W) V(H1)=n∗V(X)∗V(W)
Xavier 初始化假设 输入 X X X 和 输出 H 1 H_1 H1 的方差相同,则有:
V ( W ) = 1 n → s t d ( W ) = 1 n V(W) = \frac{1}{n} \rightarrow std(W) = \sqrt{\frac{1}{n}} V(W)=n1→std(W)=n1
由此,推导出了 Xavier 初始化公式。即从均值为零,方差为 1 n \frac{1}{n} n1 的高斯分布中选择权重,其中 n n n 表示输入神经元的数量。
在原始论文中,作者取输入神经元和输出神经元数量的平均值。因此公式变为:
-
V ( W ) = 1 n a v g = 2 n i n + n o u t = 2 n i + n i + 1 V(W) = \frac{1}{n_{avg}} = \frac{2}{n_{in} + n_{out}} = \frac{2}{n_{i} + n_{i+1}} V(W)=navg1=nin+nout2=ni+ni+12
-
他们这样做的原因也是为了保留反向传播的信号,但是实现起来在计算上更加复杂。因此,在实际实施过程中,仅采用输入神经元的数量。
考虑保持方差一致性,即保持数据尺度维持在恰当范围,通常方差为 1。
以上是针对无激活函数的情况,对于有激活函数的情况,Xavier初始化适用于饱和激活函数,如Sigmoid、Tanh。
- W ∽ U [ − a , a ] W∽U[−a,a] W∽U[−a,a]
- D ( W ) = ( − a − a ) 2 12 = ( 2 a ) 2 12 = a 2 3 D(W)=\frac{(−a−a)^2}{12}=\frac{(2a)^2}{12}=\frac{a^2}{3} D(W)=12(−a−a)2=12(2a)2=3a2
- 2 n i + n i + 1 = a 2 3 ⇒ a = 6 n i + n i + 1 \frac{2}{n_i+n_{i+1}}=\frac{a^2}{3}⇒a=\frac{\sqrt{6}}{\sqrt{n_i+n_{i+1}}} ni+ni+12=3a2⇒a=ni+ni+16
- ⇒ W ∽ U [ − 6 n i + n i + 1 , 6 n i + n i + 1 ] ⇒W∽U[−\frac{\sqrt{6}}{\sqrt{n_i+n_{i+1}}},\frac{\sqrt{6}}{\sqrt{n_i+n_{i+1}}}] ⇒W∽U[−ni+ni+16,ni+ni+16]
3. He 初始化
何凯明初始化同样遵循方差一致性原则。该权重初始化方法适用于 ReLU及其变种。其计算公式如下:
- D ( W ) = 2 n i D(W)=\frac{2}{n_i} D(W)=ni2 (适用于ReLU激活函数)
- D ( W ) = 2 ( 1 + a 2 ) ∗ n 1 D(W)=\frac{2}{(1+a^2)∗n_1} D(W)=(1+a2)∗n12 (适用于ReLU激活函数的变种,比如PReLU)
- s t d ( W ) = 2 1 + a 2 ∗ n i std(W)=\sqrt{\frac{2}{1+a^2∗n_i}} std(W)=1+a2∗ni2 (其中,a 表示激活函数负半轴的斜率)
4. PyTorch 提供的 10 种权重初始化方法
以下初始化方法都需要遵循方差一致性原则。
4.1 Xavier均匀分布
torch.nn.init.xavier_uniform_(tensor, gain=1)
- 服从均匀分布 U ( − a , a ) U(−a,a) U(−a,a) ,分布的参数 a = g a i n ∗ 6 f a n i n + f a n o u t a = gain * \sqrt{\frac{6}{fan_{in}+fan_{out}}} a=gain∗fanin+fanout6,
- 参数
gain表示增益,其大小由激活函数类型决定,比如nn.init.xavier_uniform_(w, gain=nn.init.calculate_gain(‘relu’)) - 该初始化方法,也称为 Glorot initialization。
4.2 Xavier标准正态分布
torch.nn.init.xavier_normal_(tensor, gain=1)
- 服从正态分布, m e a n = 0 , s t d = g a i n ∗ 2 f a n i n + f a n o u t mean=0,std = gain * \sqrt{\frac{2}{fan_{in} + fan_{out}}} mean=0,std=gain∗fanin+fanout2
4.3 Kaiming均匀分布
torch.nn.init.kaiming_uniform_(tensor, a=0, mode=‘fan_in’, nonlinearity=‘leaky_relu’)
- 服从均匀分布 U ( − b o u n d , b o u n d ) U(-bound, bound) U(−bound,bound),其中, b o u n d = 6 ( 1 + a 2 ) ∗ f a n i n bound = \sqrt{\frac{6}{(1+a^2)*fan_{in}}} bound=(1+a2)∗fanin6
a:激活函数的负半轴的斜率,relu是0;mode:可选fan_in或fan_out,fan_in使正向传播时,方差一致;fan_out使反向传播时,方差一致;nonlinearity:可选relu或leaky_relu,默认值为leaky_relu;- 实例:
nn.init.kaiming_uniform_(w, mode=‘fan_in’, nonlinearity=‘relu’)
4.4 Kaiming标准正态分布
torch.nn.init.kaiming_normal_(tensor, a=0, mode=‘fan_in’, nonlinearity=‘leaky_relu’)
- 服从0均值的正态分布
N(0, std),其中, s t d = 2 ( 1 + a 2 ) ∗ f a n i n std = \sqrt{\frac{2}{(1+a^2)*fan_{in}}} std=(1+a2)∗fanin2; a:激活函数的负半轴的斜率,relu是0;mode:可选fan_in或fan_out,fan_in使正向传播时,方差一致;fan_out使反向传播时,方差一致;nonlinearity:可选relu或leaky_relu,默认值为leaky_relu;- 实例:
nn.init.kaiming_normal_(w, mode=‘fan_out’, nonlinearity=‘relu’)
4.5 均匀分布
torch.nn.init.uniform_(tensor, a=0, b=1)
4.6 正态分布
torch.nn.init.normal_(tensor, mean=0, std=1)
4.7 常数分布
torch.nn.init.constant_(tensor, val)
4.8 单位矩阵初始化
torch.nn.init.eye_(tensor)
4.9 正交矩阵初始化
torch.nn.init.orthogonal_(tensor, gain=1)
4.10 稀疏矩阵初始化
torch.nn.init.sparse_(tensor, sparsity, std=0.01)
- 从正态分布
N(0. std)中进行稀疏化,使每一个 column 有一部分为 0; sparsity:每一个 column 稀疏的比例,即为 0 的比例;- 实例:
nn.init.sparse_(w, sparsity=0.1)。
5. 增益计算
torch.nn.init.calculate_gain(nonlinearity, param=None)
功能:计算激活函数的方差变化尺度。即计算输入数据的方差除以经过激活函数之后输出数据的方差,亦即两个方差的比例。
nonlinearity:激活函数名称;param:激活函数的参数,如 Leaky ReLU 的negative_slop;
6. Keras 初始化方法实现
tf.keras.initializers.glorot_normal(seed=None)
'''
sqrt(2 / (fan_in + fan_out))
'''
tf.keras.initializers.glorot_uniform(seed=None)
'''
sqrt(6 / (fan_in + fan_out))
'''
tf.keras.initializers.he_normal(seed=None)
'''
sqrt(6 / fan_in)
'''
tf.keras.initializers.he_uniform(seed=None)
'''
sqrt(6 / fan_in)
'''
tf.keras.initializers.lecun_normal(seed=None)
'''
stddev = sqrt(1 / fan_in)
'''
tf.keras.initializers.lecun_uniform(seed=None)
'''
sqrt(3 / fan_in)
'''
参考:
https://prateekvjoshi.com/2016/03/29/understanding-xavier-initialization-in-deep-neural-networks/
https://medium.com/@prateekvishnu/xavier-and-he-normal-he-et-al-initialization-8e3d7a087528
https://blog.csdn.net/u011995719/article/details/85107122


















 2608
2608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











