






高维映射跟核方法的概念很容易混淆。
高维映射通过将样本从原始空间映射到一个更高维的特征空间,从而解决了低纬下难以解决的问题。
核方法往往跟高维映射配合使用,可以看做是一种技巧,可以通过它来避免这种映射的计算。
下面详细介绍一下这两个概念。
一、高维映射
我们知道,线性回归是用一条直线来拟合数据。但是我们往往会遇到数据并不服从线性分布的情况,比如:

上图这种情况,明显是一个二次函数的分布。如果我们仍旧用线性回归方程
于是,我们选择变成一个二次方程来拟合:
它虽然是个二次函数,其实仍然可以看成是一个线性回归。但是现在不是对
令
假如把 输入
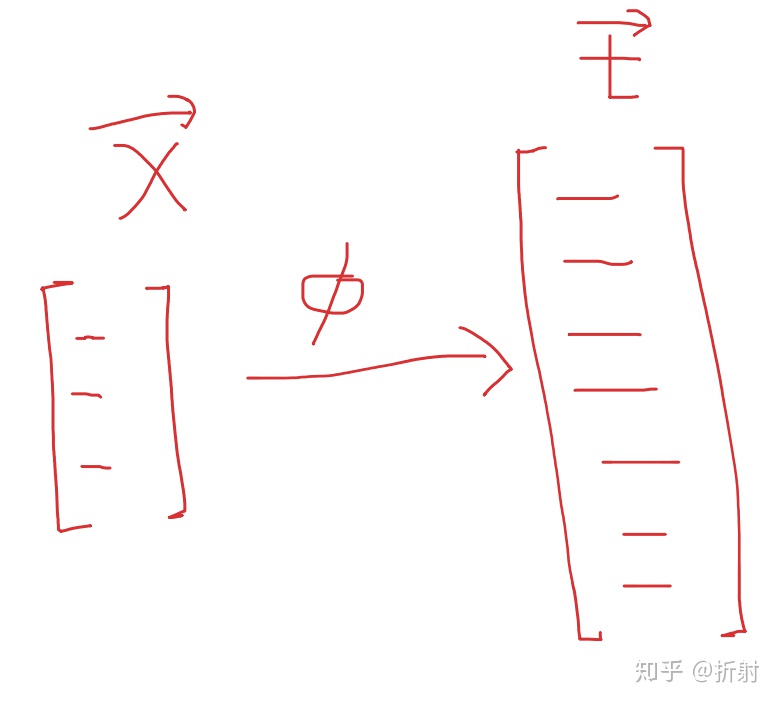
拉伸函数是一类函数,表面上看,只要是能把一个向量经过各种修改让它的维度变高,这样的函数都能当成拉伸函数来用。然而并不是这样的,假如你只是单纯地对向量
将
那么对于提升后的方程,
这里分布是一个二次函数,如果我们遇到了更加复杂的函数,我们依然可以通过选取合适的拉伸函数来变成线性的问题。幸运的是可以证明,只要数据的分布在维度有限的空间上,我们总是(发)能够找到一个更高维度的空间,使得它的分布是线性的。
因此通过高维映射以后,不管原来是不是线性的,总能通过对向量
二、求解高维映射后的线性方程
如果不做高维映射的话,线性回归的解是:
不明白的可以看看我另外一篇的讲线性回归的,里面包含了推导过程。
折射:线性回归Linear regressionzhuanlan.zhihu.com
我举个例子,帮助你回忆一下里面各个符号的含义。假设我们有5个训练样本
公式中的
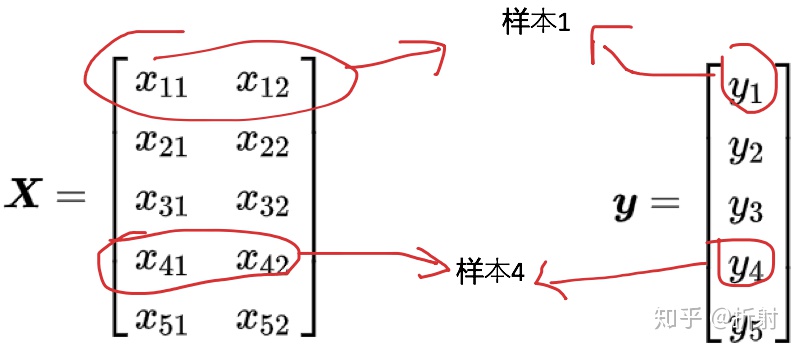
如果我们要对这个公式进行高维映射,也就是说我们对
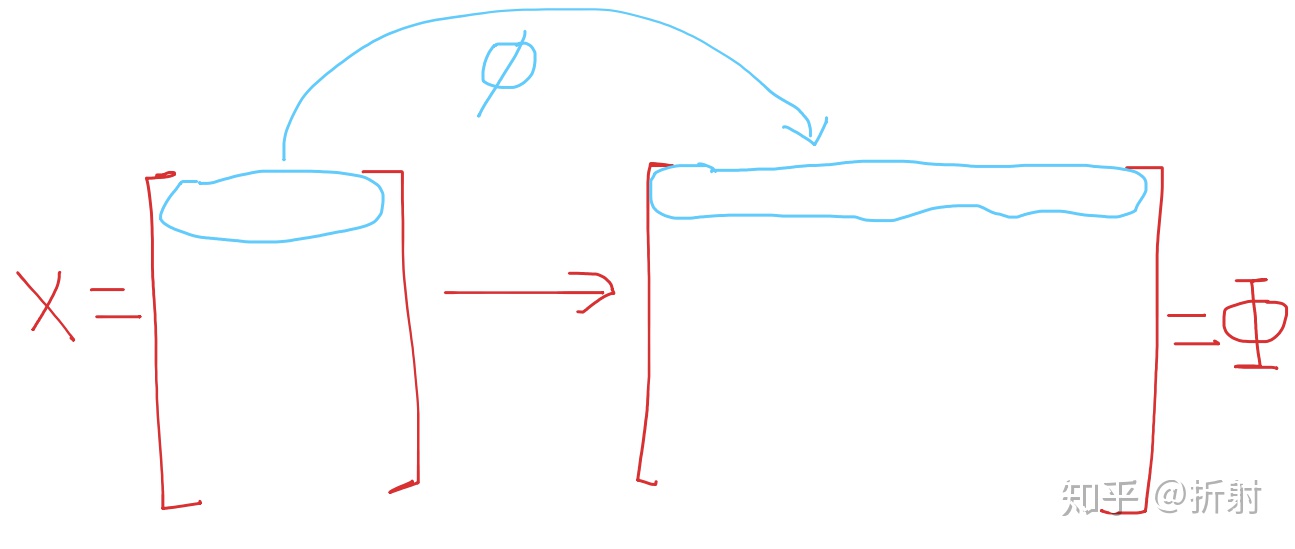
我们用
好了,右边全都是已知量,我们已经解出来了这个模型了。
我们做完高维映射之后的线性方程,要如何去预测模型呢?来模拟一下这个过程:
假设,我们现在有
第一步,我们得计算出
首先把每个数据当成一行,拼成一个矩阵
第二步,下面我们就来利用它做预测了,假如我们要预测
看看上面的过程中,我们用了多少次拉伸函数。在训练过程中,我们对训练集里面每个样本都用了一次拉伸。在预测的时候,我们又要对预测集里面的每个样本做一次拉伸。现在我告诉你,拉伸函数往往计算量非常大,那么计算这个拉伸显然是一个非常大的开销。
虽然说理论上,因为有限维度的数据必然存在一个拉伸函数将数据映射到高维并且满足线性分布。也就是说必然存在一个完美的拉伸函数。然而,我们往往并不知道到底怎么样的函数才是完美的拉伸函数,选择合适的拉伸函数也是一个非常麻烦的问题。
现在我告诉你,我们有一种取巧的办法。使得我们根本不用计算拉伸函数,有时候甚至你都不需要知道拉伸函数是什么,我们依然能够做预测。这个无比巧妙的简便方法,帮助我们跳过了拉伸的步骤,这个方法就叫做核方法。
三、核函数(Kernel function)
你可能非常迫切地想知道这个巧妙的核方法到底是什么。但是我要在这里卖个关子,不直接告诉你核方法是怎么来的,我们从定义出发一步一步慢慢推导出来。
现在我要转换一下话题,我们先研究研究这个拉伸函数
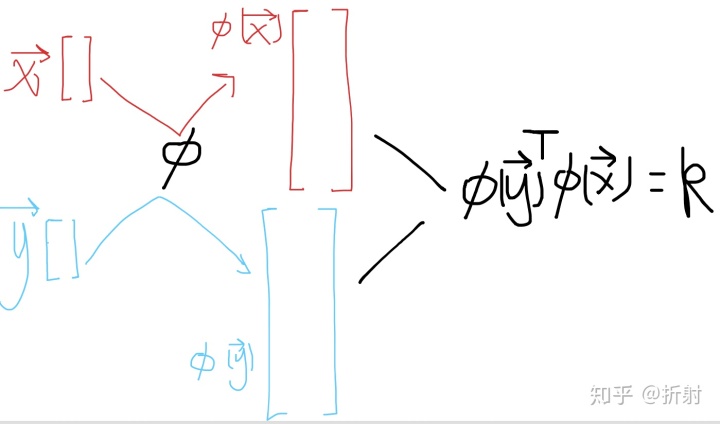
我们知道,两个向量做内积得到的是一个值。这个过程中,我们先是把两个向量拉伸到高维,然后又通过求内积变回一维。
在数学里面,有这样一类函数,它的参数是2个向量,它的输出是一个标量值。它有个特点,就是对于任何相同形状的输入向量
解释一下,这类函数对于任何输入向量
这类核函数每个都有各自的表达式,举个例子:
线性核:
多项式核:
注意到,这个表达式里面是不含有拉伸函数的。但是它既然满足核函数的条件,它一定是能改写成两个向量拉伸求内积的形式。
线性核里面隐藏的变换就是做线性拉伸变换(我们之前讨论过,光用线性拉伸是不能解决非线性问题的)。多项式核自然就是做几次方的拉伸变换。换句话说,每一个能被叫做核函数的函数,里面都藏着一个对应拉伸的函数。这些核函数的命名通常也跟如何做拉伸变换有关系。
总结一下,我们现在反了过来,先找满足核函数条件的的表达式,再倒推出一种映射关系。我们选哪个核函数,实际上就是在选择用哪种方法映射。通过核函数,我们就能跳过映射的过程。
四、核方法(Kernel method)
好了,现在我们打定主意,要利用核函数来跳过做映射了。我们假如找到了一个核函数,也就是说我们的拉伸函数也定下来了。我们改写一下核函数的参数,写成这样的形式:
到底要怎么利用呢?先观察一下高维映射以后的模型表达式:
观察一下上面两个公式,你一定能够联想到,肯定要从这个
先看看
在这里跟拉伸项最有关系的一项就是
我们我们可以令
使用
试着把它展开一下,矩阵乘向量的怎么写成求和的形式呢。其实矩阵右乘一个向量,相当于对矩阵的每一列都乘对于向量位置的分量再累加,如图所示:
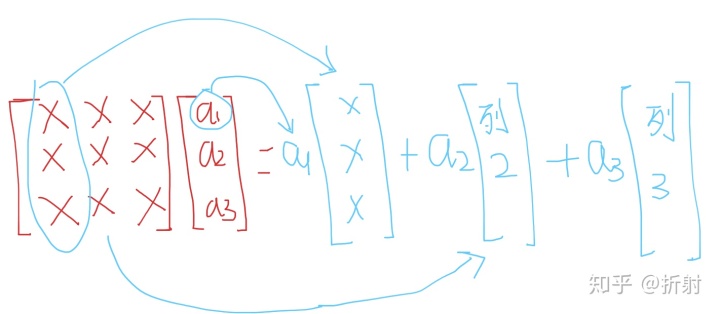
矩阵
用右边这个替换我们模型里面的
看到没有,我们右边已经出现了一个核函数的表达形式了。我们可以直接根据公式
现在的y表达式中,已经不含有拉伸函数项了,这样我们就避开了求拉伸函数的过程。
但是你会发现,我们并不知道
我们得从求
如果加了L2正则以后的线性损失函数的公式看不懂,可以去看我写的 机器学习中的正则化,L1 L2正则。 令
求关于
解得:
再看
现在我们把所有的拉伸函数都消除掉了。我们现在就可以用求出来的
五、总结
在使用机器学习模型做回归或者分类的时候,假如在低维度空间下数据集不好用,那么可以尝试通过把输入的值做高维映射来解决。高维映射不仅仅用于线性回归,包括逻辑回归,还有SVM,尤其是SVM。
由于做高维映射的计算量比较大。当我们遇到需要做高维映射的时候
利用核方法并非没有缺点。原来的线性模型显然是一种参数化方法,好处是训练完成的模型只需要存储权重向量
原创,转载请注明出处。
初学者,不可避免出现错误。如果有任何问题,欢迎指正。也欢迎一起交流、讨论。
欢迎关注我的专栏:
https://zhuanlan.zhihu.com/c_1024970634371186688zhuanlan.zhihu.com














 5928
5928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









