






参考列表:
https://blog.csdn.net/fangqingan_java/article/details/51020653
https://www.cnblogs.com/yaoyaohust/p/10733050.html
https://blog.csdn.net/u011239443/article/details/80528717
工程实践视角下的广告点击率预估
摘要
广告点击率预估是一个非常有钱途的问题。本文中我们提出了一个案例研究和主题的选择,从最近的实验中,设置了一个部署的CTR预测系统。在传统的监督学习环境下,基于FTRL-Proximal在线学习算法,并使用了协调学习率。
我们还探讨了现实世界系统中出现的一些挑战,这些挑战最初可能出现在传统机器学习研究领域之外。这些包括节省内存的有用技巧、评估和可视化性能的方法、为预测概率提供置信估计的实用方法、校准方法和自动管理功能的方法。最后还给出了一些失败的尝试。
本文的目的是强调在产业背景下,理论进步与实际工程之间的密切关系,并指出将传统的机器学习方法应用于复杂动态系统这一思路所面临的挑战。
P.S.TRL-Proximal学习算法可以参考这一篇文章https://zhuanlan.zhihu.com/p/35449814
绪论
点击率预估现在也是一个热门的研究话题,因为它可以直观地带来巨大的经济效应。本文中提出了一系列研究,并着眼于内存节省、性能分析、预测评估、校准和功能管理等问题。本文的目的是让读者了解在实际工业环境中所面临的挑战的深度,并分享可应用于其他大范围的技巧和见解。
系统概述
点击率预估的基本问题是,如果用户搜索了![]() ,那么系统应该给出那些广告,以及这些广告应该如何排名?对于我们研究者来说,就是要估计这个概率
,那么系统应该给出那些广告,以及这些广告应该如何排名?对于我们研究者来说,就是要估计这个概率
![]()
即给定搜索关键词和广告,预测点击这个广告的概率。我们再做这件事的时候,使用了各种来源,包括查询,文字广告创意,和各种广告相关的元数据。数据是非常稀疏的。
我们会想到正则化逻辑斯蒂回归等算法。注意点击率预估这个问题要求每天进行大量的计算,而且数据是以流的形式提供的。本文中,我们不在系统架构上花费太多的笔墨,重点介绍如何训练和应用算法。和谷歌大脑团队不同,我们没有用深度神经网络,而是使用了单层的感知机模型,为此我们可以解决大规模的模型训练和应用。
稀疏矩阵下的在线学习
首先给出符号表示
![]() ,t表示训练实例的索引,
,t表示训练实例的索引,![]() 表示前者的第i维
表示前者的第i维
![]() 压缩求和的简写
压缩求和的简写
![]() 是给出的特征向量
是给出的特征向量
![]() 是模型参数
是模型参数
那么,预测结果为![]()
![]() ,其中
,其中![]()
![]() 是标签
是标签
![]() 是损失函数
是损失函数
显然梯度为![]()
以上是一个经典的估计方法,但是在我们的方案中并不适用,因为我们的数据规模非常大,而且非常稀疏。关于如何解决和产生稀疏矩阵的问题,已经有很多研究,比如RDA,FOBOS等,都有不错的成果。这里我们使用FTRL算法,它可以在减少计算量的前提下有效地处理稀疏矩阵。
为了说明算法的原理,先给出一个例子。正常的梯度下降法是这样的:
![]()
itat是学习率,随时间单调不增,gt是梯度。
而FTRL使用下面的迭代式更新
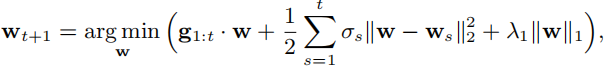
deltas和itat有一样的物理意义。如果我们令lambda1为0,则会得到一个不变的序列,如果我们令lambda1大于零,就会得到一个优秀的稀疏序列。
为了方便计算,将上式改写为
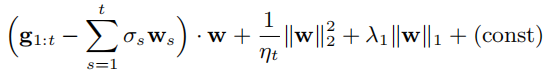
然后令![]() ,更新式就简化为
,更新式就简化为
![]()
![]()
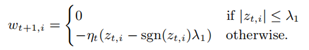
算法的完整流程可以写为

实验结果证明,这个算法很好。下面讲一下学习率的调整。
一个常用的思路是让迭代步长随着迭代次数的增加而减小,这个看似有道理,实际上解释不通,而且也有人已经证明了这个算法的性能不行。我们介绍下面的学习率更新方法:
![]()
![]()
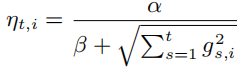
实验结果也证明,这个方法是好的。
大规模节省内存
特征方面:由于大多数特征只出现一次,却占用了极多的空间,这里采用概率特征加入/布隆过滤器方法,以某一个概率加入新特征,或当新特征出现超过n次才加入。
存储方面:因为系数的范围都比较小,利用一种叫做q2.13的数据格式而不是浮点数格式。
训练方面:高度相似的模型之间可以共享参数
用计数计算学习率
下采样学习率:保留至少点击一个ad的query或按概率r采样无点击ad的query
下采样之后,要对权重做归一化
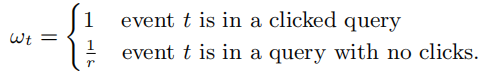
(这一部分看的比较粗糙,因为自己目前没有这方面的应用需求,而且硬件知识比较匮乏也没有看太懂)
评估模型性能
使用离线测试,AucLoss,Logloss和均方误差
渐进验证
这里使用渐进验证而不是交叉验证,因为计算学习的梯度无论如何都需要计算一个预测,所以我们可以便宜地将这些预测流出来,以便进行随后的分析,每小时汇总,而且这还可以模仿在线测试。
通过可视化加深理解
分门别类地展示预测结果,防止聚合分布掩盖了一些内在的机理。
置信度估计
校准预测
对最后的结果进行校准,纠正系统偏差。
自动特征管理
将特征空间组织成各种信号(signals),比如ad words、country,能转换为实数特征。为了管理signals和models,做了metadata index。
失败的尝试
对特征使用哈希技巧:一些文献声称的feature hashing(用于节省内存)的方式在试验中无效。因此保存可解释(即non-hashed)的特征数值向量。
Dropout:没有增强泛化性能反而损害了精度。我们认为这是在深度学习领域(比如图像识别)中特征是稠密的,所以Dropout可以大放异彩,我们的数据本来就很稀疏,再Dropout就没了。
特征打包:也就是ml中的bagging方法。不知道为什么反正就是结果并不好。
特征标准化:可能是由于学习速度和正规化的相互作用,特征归一化之后效果并不好。
这篇文章没有没耐心看的结论。
个人总结
其实从笔记中就可以很明显的看出来,这篇文章看的没有很走心。一方面是因为点击率预估这个问题我本身不是很关心,一方面是因为论文过于专业和工程,既不太看得懂眼下也不太用得上。
不过,在很多其他方面还是受教了:
1.灵活地调整学习率
2.采样之后要做权重调整,训练之后要做模型偏差弥补
3.渐进验证
4.最后一部分给出的失败尝试大多数都是特征工程的应用。这启示我们很多特征工程的技巧并不是都是有用的,要多尝试,不能想当然,才能根据数据的特征给出最好的预处理。















 93
93











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









