






什么是Gecco ?
Gecco 是一款用java语言开发的轻量化的易用的网络爬虫,整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架。
为什么使用Gecco?
我是在码云上面搜了java爬虫框架,结果如下
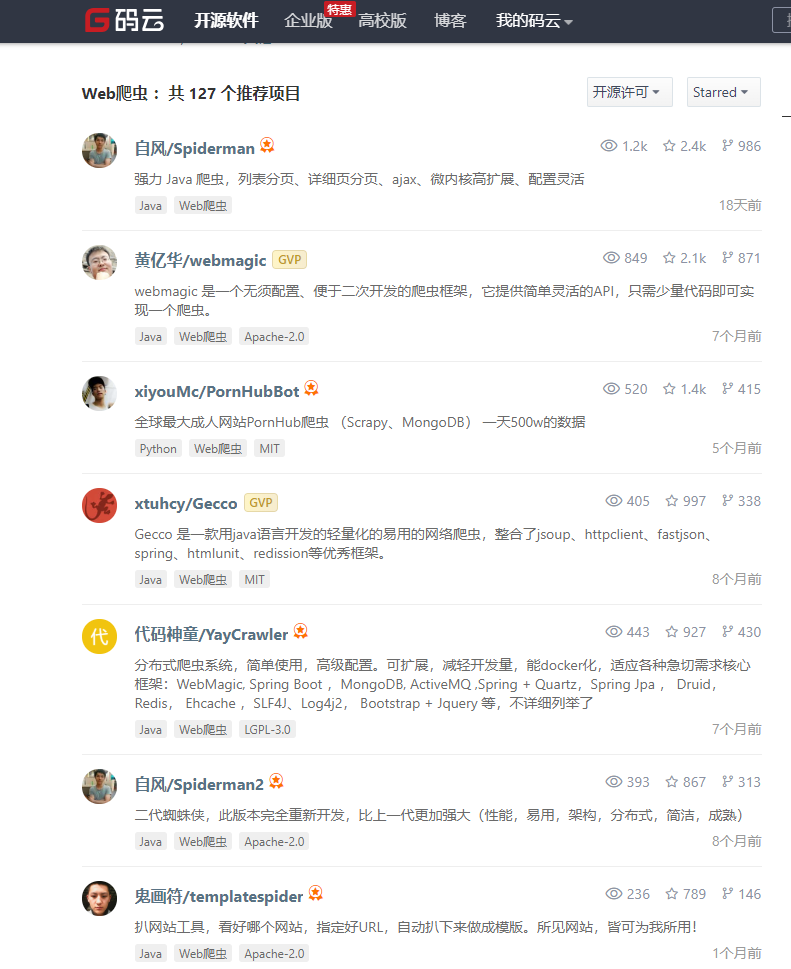
前三个都有试过,但是远远没有Gecco的API简洁,上手简单。最重要的一点是:它跟我学过的Python的爬虫框架Scrapy用法很相似。

看图,不多说。
接下来我们上手吧
开源地址
官网文档
依赖
目前最新版本1.3.0
com.geccocrawler
gecco
1.3.0
为了使我们代码更简洁,我们还要引入LomBok
org.projectlombok
lombok
1.16.18
provided
gecco的内容抽取都是直接映射到java bean的属性中,利用注解可以方便的注入页面中的各种信息包括html页面内容、Ajax请求、javascript变量、request信息等
常用注解@HtmlField
html属性定义,表示该属性是通过html查找解析,在html的渲染器下使用cssPath:jquery风格的元素选择器,使用jsoup实现。jsoup在分析html方面提供了极大的便利。计划实现xpath风格的元素选择器。@Href
表示该字段是一个链接类型的元素,jsoup会默认获取元素的href属性值。属性必须是String类型。value:默认获取href属性值,可以多选,按顺序查找click:表示是否点击打开,继续让爬虫抓取@Image
表示该字段是一个图片类型的元素,jsoup会默认获取元素的src属性值。属性必须是String类型。value:默认获取src属性值,可以多选,按顺序查找download:表示是否需要将图片下载到本地@Attr
获取html元素的attribute。属性支持java基本类型的自动转换。value:表示属性名称@Text
获取元素的text或者owntext。属性支持java基本类型的自动转换。own:是否获取owntext,默认为是@Html
默认类型,可以不写,获取html元素的整个节点内容。属性必须是String类型。
快速开始packageme.liao.gecco.liaowo;importcom.geccocrawler.gecco.GeccoEngine;importcom.geccocrawler.gecco.annotation.*;importcom.geccocrawler.gecco.spider.HtmlBean;importlombok.Data;//Lombok注解 省去get/set方法@Data// matchUrl是要抓取的地址 这里的{id}是个占位符pipelines后面讲@Gecco(matchUrl="https://sanii.cn/article/{id}",pipelines="liaowome")
public classliaowoimplements HtmlBean{
private static final longserialVersionUID= -7127412585200687225L;@RequestParameter("id")
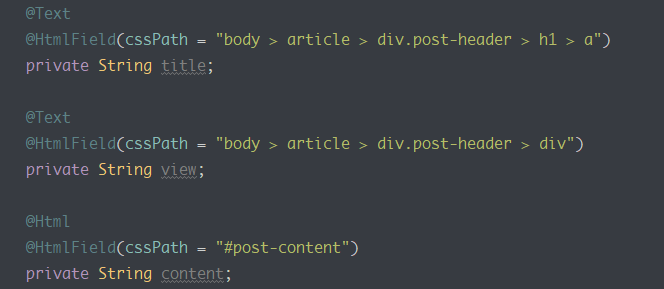
privateStringid;@Text@HtmlField(cssPath="body > article > div.post-header > h1 > a")
privateStringtitle;@Text@HtmlField(cssPath="body > article > div.post-header > div")
privateStringview;@Html@HtmlField(cssPath="#post-content")
privateStringcontent;public static voidmain(String[] args) {
GeccoEngine.create()
//工程的包路径.classpath("me.liao.gecco.liaowo")
//开始抓取的页面地址.start("https://sanii.cn/article/249")
//开启几个爬虫线程.thread(1)
//单个爬虫每次抓取完一个请求后的间隔时间.interval(2000)
//循环抓取.loop(true)
//使用pc端userAgent.mobile(false)
//非阻塞方式运行.start();
}
}
HtmlField字段的提取规则我们怎么写呢?
我们可以借助chrome浏览器解决
拿上面的代码举例(唉,我又拿自己的站点举例了 受伤)
我们要爬取title、view、content的数据。
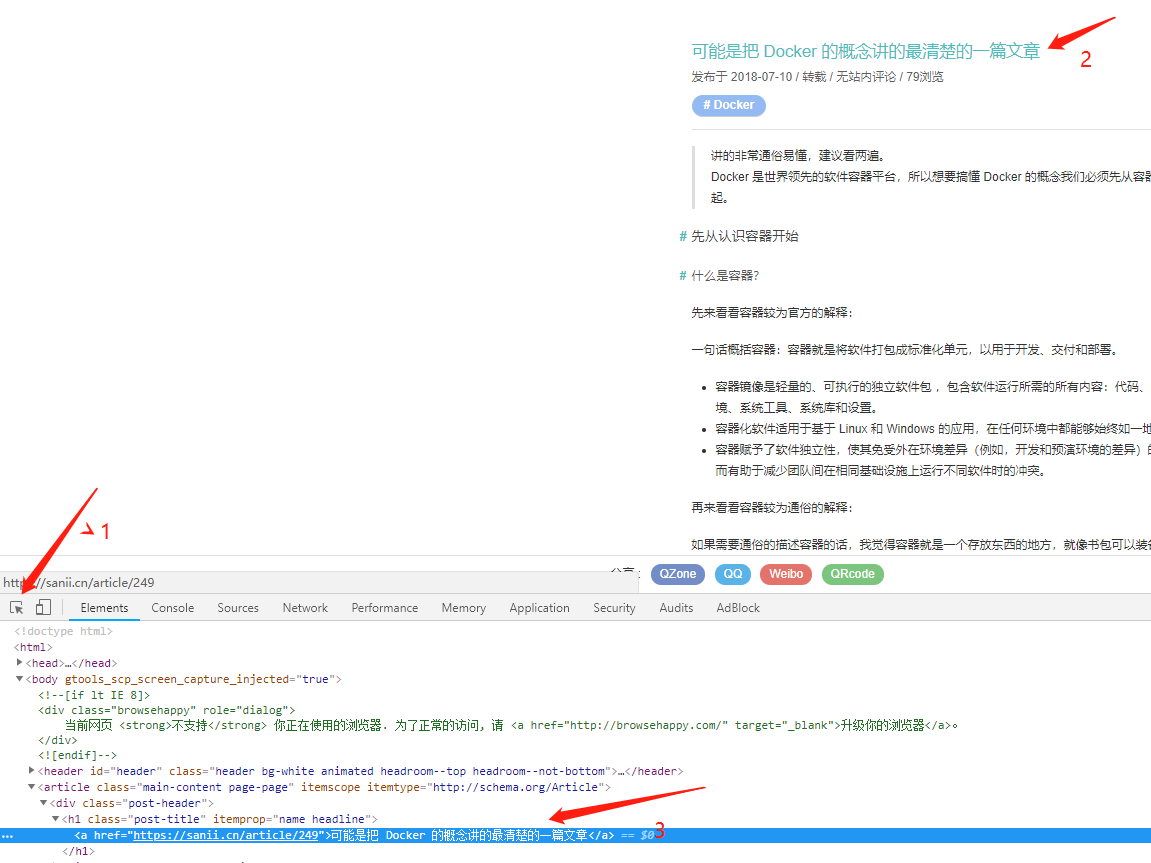
如上图,会得到页面的DOM节点(如3),此时右键Copy>Copy selector 即可得到> body > article > div.post-header > h1 > a 类似这样的内容,直接填入HtmlField即可。
重复如下可以得到
我们可以直接在main方法中启动测试一下public static voidmain(String[] args) {
GeccoEngine.create()
//工程的包路径.classpath("me.liao.gecco.liaowo")
//开始抓取的页面地址.start("https://sanii.cn/article/249")
//开启几个爬虫线程.thread(1)
//单个爬虫每次抓取完一个请求后的间隔时间.interval(2000)
//循环抓取.loop(true)
//使用pc端userAgent.mobile(false)
//非阻塞方式运行.start();}
Gecco如何运行
Gecco的初始化和启动通过GeccoEngine完成,GeccoEngine主要负责初始化配置、开始请求的配置和启动爬虫运行,最基本的启动方法:GeccoEngine.create()
.classpath("com.geccocrawler.gecco.demo")
.start("https://github.com/xtuhcy/gecco")
.start();
classpath是必填项,指定扫描@Gecco的包路径。start是初始请求地址。start()表示采用非阻塞方式运行爬虫。
GeccoEngine基本配置项loop(true):表示是否循环抓取,默认为false
thread(2):表示开启的爬虫线程数量,默认是1,需要注意的是线程数量要小于或者等于start请求的数量
interval(2000):表示某个线程在抓取完成一个请求后的间隔时间,单位是毫秒,系统会在左右1秒时间内随机。如果为2000,系统会在1000~3000之间随机选取。
mobile(false):表示使用移动端还是pc端的UserAgent。默认为false使用pc端的UserAgent。
debug(true):是否开启debug模式,如果开启debug模式,会在控制台输出jsoup元素抽取的日志。
pipelineFactory(PipelineFactory):自定义Pipeline工厂类
scheduler(Scheduler):自定义请求队列管理器
非阻塞启动和阻塞启动start():非阻塞启动,GeccoEngine会单独启动线程运行,推荐以该方式运行。线程模型如下:
Main Thread-->GeccoEngine Thread-->Spider Threadrun():阻塞启动,GeccoEngine在主线程中启动运行,非循环模式GeccoEngine需要等待其他爬虫线程运行完毕后才会退出。线程模型r如下:
Main Thread-->Spider Thread
输出结果

我们怎么得到爬取的数据bean呢?
这个问题我在官网的文档中找了很久,并没有找到相关的文章。最后是在翻一些Demo的时候找到的@PipelineName("liaowome")
public classConsolePipelineimplements Pipeline{
@Overridepublic voidprocess(SpiderBeanbean) {
System.out.println("爬虫结果:"+JSON.toJSONString(bean));
}
}
创建一个类,格式如上。在Process中就可以得到我们的数据
这里有一个坑:
PipelineName的名字最好不要是consolePipeline,我从demo上照搬了这个名字,导致在获取的时候死活得不到数据。
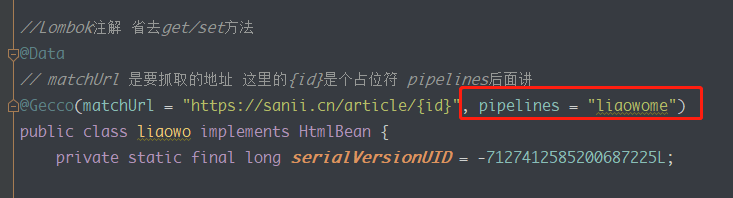
改成我们定义的PipelineName。
把爬到的数据保存到文本中@PipelineName("liaowome")
public classConsolePipelineimplements Pipeline{
@Overridepublic voidprocess(SpiderBeanbean) {
System.out.println("爬虫结果:"+JSON.toJSONString(bean));try{
Fileto =newFile("E:\\liaowome.txt");Files.append(JSON.toJSONString(bean) +System.getProperty("line.separator"),to,Charsets.UTF_8);} catch(IOExceptione) {
e.printStackTrace();}
}
}
System.getProperty("line.separator") 得到当前操作系统的换行符;
上面使用了Guava包(Gecco自带了Guava依赖)的Files类,一行代码解决。
代码下载

本文由 SAn 创作,采用 知识共享署名4.0 国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为:
2018/07/11 20:00














 475
475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









