






本系列文章力求浓缩论文要点,同时讲清楚论文的来龙去脉。
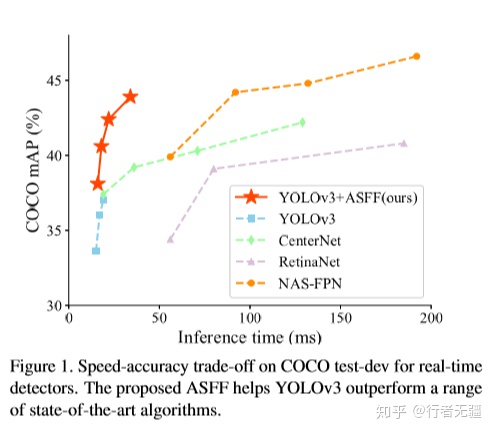
今天要讲解的论文是《Learning Spatial Fusion for Single-Shot Object Detection》,它解决了特征金字塔中深浅层特征融合时,特征尺度不一致造成的冲突问题(下文中会进行详细解释)。如上图所示,YOLOV3+ASFF相比于原始的YOLOV3 baseline有较为明显的涨点。按照以下结构来组织
- 论文要解决的问题(背景)
- 论文怎么解决的该问题(创新点)
- 代码层而怎么实现(实现)
论文要解决的问题(背景)
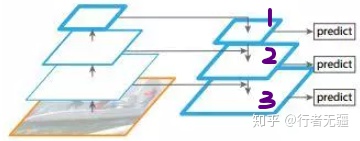
上图是目标检测中特征金字塔(FPN)的结构图。该结构的意义在于:每个预测分枝有效的结合了深度网络特征图的主义信息和浅层网络特征图的位置信息。网络层次越深时,深层网络的语义信息越明确,知道图像中是什么,但深层特征中包含的空间位置信息较少。网络浅层中保存的空间信息丰富。因此,FPN深浅拼接结构可以有效的解决目标检测中不同大小物体的:分类(语义信息,是什么)+定位(在哪里)。这和本文有啥关系呢?且听我细细道来。
上图中有三个检测分枝的输入,从上到小称之为特征图1、特征图2、特征图3。三个分枝中1号特征图感受野小(相对于2、3而言),适合检测网络输入图片中的小物体;3号特征图由网络主干中深层产生,感受野最大,适合检测大物体;同理,2号特征图适合检测中等大小的物体。那么问题来了,3号特图中既有大物体也有小物体,它的目标是检测大物体,能不能使用一个过滤器,来将3号特征图中小物体激活值过滤掉,同时结合1、2图特征图中的对应大物体的特征值来丰富3中大物体信息?
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 970
970











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









