






1.什么是代价函数?
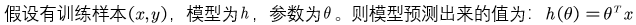


2.逻辑回归的代价函数
获得逻辑回归的数学形式
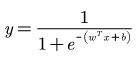
接下来就是对模型进行求解。一般的方法都是使用极大似然估计法来求解,即找到一组参数,使得在这组参数下,我们的数据的似然度最大

3.函数求解
求解逻辑回归的方法用的比较多的有梯度下降法和牛顿法,优化的主要目标是找到一个方向,参数朝这个方向移动之后使得损失函数的值能够减小。逻辑回归的损失函数是:
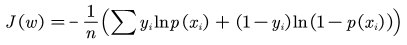
求解的步骤如下:
1- 随机一组参数w,
2- 将w代入到损失函数中,让得到的点沿着负梯度的方向移动
3- 循环以上步骤,直到函数的值最小
更新方法为求导对函数求导:
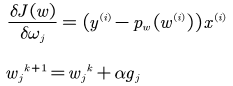
其中k为迭代次数,每次更新参数后,可以通过比较

小于阈值或者达到最大迭代次数来停止迭代。
2.牛顿法
牛顿法的思路是在现有的极小点估计值的附近对f(x)做二阶泰勒展开,进而找到极小点的下一个估计值。

正则化:
正则化是为了解决过拟合现象的出现,一般的形式有L1范式,
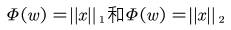
1. L1正则化又称之为LASOO回归,相当于给模型添加了一个先验知识:w服从拉普拉斯分布:

加入了先验知识,那么似然函数就变成了:
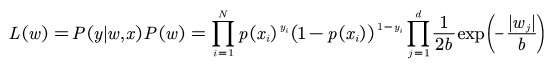
取log后得到目标函数:
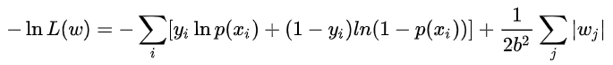
等价于原始损失函数的后面加上了 L1 正则。
2. L2正则化,又称为Ridge回归,它相当于给模型添加一个先验知识:w服从零均值正态分布。
首先正态分布的形式如下:

当引入正态分布后,似然函数可以写为:

取ln后得到目标函数:
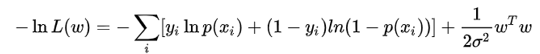
等价于原始的损失函数后面加上了 L2 正则
L1和L2正则的区别:
L1 正则化增加了所有权重 w 参数的绝对值之和逼迫更多w为零,也就是变稀疏.
L2 正则化中增加所有权重 w 参数的平方之和,逼迫所有w尽可能趋向零但不为零.
正则化之所以能够降低过拟合的原因在于,正则化是结构风险最小化的一种策略实现。
简单总结如下:给 loss function 加上正则化项,能使新得到的优化目标函数

需要在 f 和 ||w|| 中做一个权衡,如果只优化 f 的情况下,那可能得到一组解比较复杂,使得正则项 ||w|| 比较大,那么 h 就不是最优的。那么就需要通过降低模型复杂度,得到更小的泛化误差,降低过拟合程度。L1 正则化就是在 loss function 后边所加正则项为 L1 范数,加上 L1 范数容易得到稀疏解(0 比较多)。L2 正则化就是 loss function 后边所加正则项为 L2 范数的平方,加上 L2 正则相比于 L1 正则来说,得到的解比较平滑(不是稀疏),但是同样能够保证解中接近于 0(但不是等于 0,所以相对平滑)的维度比较多,降低模型的复杂度。















 1950
1950











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









