






以下是使用SMO算法的多类别SVM代码:
import torch
import numpy as np
from random import shuffle
from sklearn.utils import shuffle as shuffle_ds
def rbf(sigma=1):
def rbf_kernel(x1,x2,sigma):
X12norm = torch.sum(x1**2,1,keepdims=True)-2*x1@x2.T+torch.sum(x2**2,1,keepdims=True).T
return torch.exp(-X12norm/(2*sigma**2))
return lambda x1,x2: rbf_kernel(x1,x2,sigma)
def poly(n=3):
return lambda x1,x2: (x1 @ x2.T)**n
def grpf(sigma, d):
return lambda x1,x2: ((d + 2*rbf(sigma)(x1,x2))/(2 + d))**(d+1)
class svm_model_torch:
def __init__(self, m, n_class, device="cpu"):
self.device = device
self.n_svm = n_class * (n_class - 1)//2
self.m = m # number of samples
self.n_class = n_class
self.blacklist = [set() for i in range(self.n_svm)]
# multiplier
self.a = torch.zeros((self.n_svm,self.m), device=self.device) # SMO works only when a is initialized to 0
# bias
self.b = torch.zeros((self.n_svm,1), device=self.device)
# kernel function should input x [n,d] y [m,d] output [n,m]
# Example of poly kernel: lambda x,y: torch.matmul(x,y.T)**2
self.kernel = lambda x,y: torch.matmul(x,y.T)
# Binary setting for every SVM,
# Mij says the SVMj should give
# Mij label to sample with class i
self.lookup_matrix=torch.zeros((self.n_class, self.n_svm), device=self.device)
# The two classes SVMi concerns,
# lookup_class[i]=[pos, neg]
self.lookup_class=torch.zeros((self.n_svm, 2), device=self.device)
k=0
for i in range(n_class-1):
for j in range(i+1,n_class):
self.lookup_class[k, 0]=i
self.lookup_class[k, 1]=j
k += 1
for i in range(n_class):
for j in range(self.n_svm):
if i == self.lookup_class[j,0] or i == self.lookup_class[j,1]:
if self.lookup_class[j, 0]==i:
self.lookup_matrix[i,j]=1.0
else:
self.lookup_matrix[i,j]=-1.0
def fit(self, x_np, y_multiclass_np, C, iterations=1, kernel=rbf(1)):
x_np, y_multiclass_np = shuffle_ds(x_np,y_multiclass_np)
self.C = C # box constraint
# use SMO algorithm to fit
x = torch.from_numpy(x_np).float() if not torch.is_tensor(x_np) else x_np
x = x.to(self.device)
self.x = x.to(self.device)
y_multiclass = torch.from_numpy(y_multiclass_np).view(-1,1) if not torch.is_tensor(y_multiclass_np) else y_multiclass_np
y_multiclass=y_multiclass.view(-1)
self.y_matrix = torch.stack([self.cast(y_multiclass, k) for k in range(self.n_svm)],0).to(self.device)
self.kernel = kernel
a = self.a
b = self.b
for iteration in range(iterations):
print("Iteration: ",iteration)
for k in range(self.n_svm):
y = self.y_matrix[k, :].view(-1).tolist()
index = [i for i in range(len(y)) if y[i]!=0]
shuffle(index)
traverse = []
if index is not None:
traverse = [i for i in range(0, len(index)-1, 2)]
if len(index)>2:
traverse += [len(index)-2]
for i in traverse:
if str(index[i])+str(index[i+1]) not in self.blacklist[k]:
y1 = y[index[i]]
y2 = y[index[i+1]]
x1 = x[index[i],:].view(1,-1)
x2 = x[index[i+1],:].view(1,-1)
a1_old = a[k,index[i]].clone()
a2_old = a[k,index[i+1]].clone()
if y1 != y2:
H = max(min(self.C, (self.C + a2_old-a1_old).item()),0)
L = min(max(0, (a2_old-a1_old).item()),self.C)
else:
H = max(min(self.C, (a2_old + a1_old).item()),0)
L = min(max(0, (a2_old + a1_old - self.C).item()),self.C)
E1 = self.g_k(k, x1) - y1
E2 = self.g_k(k, x2) - y2
a2_new = torch.clamp(a2_old + y2 * (E1-E2)/self.kernel(x1 - x2,x1 - x2), min=L, max=H)
a[k,index[i+1]] = a2_new
a1_new = a1_old - y1 * y2 * (a2_new - a2_old)
a[k, index[i]] = a1_new
b_old = b[k,0]
K11 = self.kernel(x1,x1)
K12 = self.kernel(x1,x2)
K22 = self.kernel(x2,x2)
b1_new = b_old - E1 + (a1_old-a1_new)*y1*K11+(a2_old-a2_new)*y2*K12
b2_new = b_old - E2 + (a1_old-a1_new)*y1*K12+(a2_old-a2_new)*y2*K22
if (0<a1_new) and (a1_new<self.C):
b[k,0] = b1_new
if (0<a2_new) and (a2_new<self.C):
b[k,0] = b2_new
if ((a1_new == 0) or (a1_new ==self.C)) and ((a2_new == 0) or (a2_new==self.C)) and (L!=H):
b[k,0] = (b1_new + b2_new)/2
if b_old == b[k,0] and a[k,index[i]] == a1_old and a[k,index[i+1]] == a2_old:
self.blacklist[k].add(str(index[i]) + str(index[i+1]))
def predict(self,x_np):
xp = torch.from_numpy(x_np) if not torch.is_tensor(x_np) else x_np
xp = xp.float().to(self.device)
k_predicts = (self.y_matrix.to(self.device) * self.a) @ self.kernel(xp,self.x).T + self.b
result = torch.argmax(self.lookup_matrix @ k_predicts,axis=0)
return result.to("cpu").numpy()
def cast(self, y, k):
# cast the multiclass label of dataset to
# the pos/neg (with 0) where pos/neg are what SVMk concerns
return (y==self.lookup_class[k, 0]).float() - (y==self.lookup_class[k, 1]).float()
def wTx(self,k,xi):
# The prediction of SVMk without bias, w^T @ xi
y = self.y_matrix[k, :].reshape((-1,1))
a = self.a[k,:].view(-1,1)
wTx0 = self.kernel(xi, self.x) @ (y * a)
return wTx0
def g_k(self,k,xi):
# The prediction of SVMk, xi[1,d]
return self.wTx(k,xi) + self.b[k,0].view(1,1)
def get_w(self, k):
y = self.cast(self.y_multiclass, k)
a = self.a[k,:].view(-1,1)
return torch.sum(a*y*self.x,0).view(-1,1)
def get_svms(self):
for k in range(self.n_svm):
sk = 'g' + str(self.lookup_class[k, 0].item()) + str(self.lookup_class[k, 1].item()) + '(x)='
w = self.get_w(k)
for i in range(w.shape[0]):
sk += "{:.3f}".format(w[i,0].item()) + ' x' + "{:d}".format(i) +' + '
sk += "{:.3f}".format(self.b[k,0].item())
print(sk)
def get_avg_pct_spt_vec(self):
# the average percentage of support vectors,
# test error shouldn't be greater than it if traing converge
return torch.sum((0.0<self.a) & (self.a<self.C)).float().item()/(self.n_svm*self.m)以下示例代码使用了此SVM模型:
import numpy as np
#from svm_torch import *
data_x = np.array([[-2,1],[-2,2],[-1,1],[-1,2],[1,1],[1,2],[2,1],[2,2],[1,-1],[1,-2],[2,-1],[2,-2],[-2,-1],[-2,-2],[-1,-1],[-1,-2]])
data_y = np.array([[0],[0],[0],[0],[1],[1],[1],[1],[2],[2],[2],[2],[3],[3],[3],[3]])
m = len(data_x)
c = len(np.unique(data_y))
svm = svm_model_torch(m,c)
svm.fit(data_x,data_y,1,10)
print(svm.predict(data_x)) # 预测结果
svm.get_svms() # Cn2 个SVM分类界面的表达式
print(svm.a) # 拉格朗日乘子使用mlxtend绘制随机生成的二维数据集的分类界面,三角形指示支持向量的位置:
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
import numpy as np
from sklearn.datasets import make_classification
colors = ['red','green','blue','yellow']
data_x,data_y = make_classification(n_samples=100, n_features=2, n_informative=2, n_redundant=0,n_clusters_per_class=1, n_classes=4,class_sep=2)
fig = plt.figure()
fig = plt.scatter(data_x[:,0],data_x[:,1],c=data_y, cmap=ListedColormap(colors), marker='o')
m = len(data_x)
c = len(np.unique(data_y))
svm = svm_model_torch(m,c)
svm.fit(data_x,data_y, 1, 10, rbf(1))
from mlxtend.plotting import plot_decision_regions
x=np.linspace(-4,4,100)
test_x = np.array(np.meshgrid(x,x)).T.reshape(-1,2)
test_y = svm.predict(test_x).reshape(-1)
scatter_kwargs = {'alpha': 0.0}
fig =plot_decision_regions(test_x, test_y, clf=svm,scatter_kwargs=scatter_kwargs)
xx = np.linspace(-4,4,10)
for i in range(svm.n_svm):
ak = svm.a[i,:].reshape(-1)
mask = (svm.C*0.0001< ak) & (ak<svm.C*(1-0.0001))
fig.scatter(data_x[mask, 0]+i/8, data_x[mask,1],marker=4)
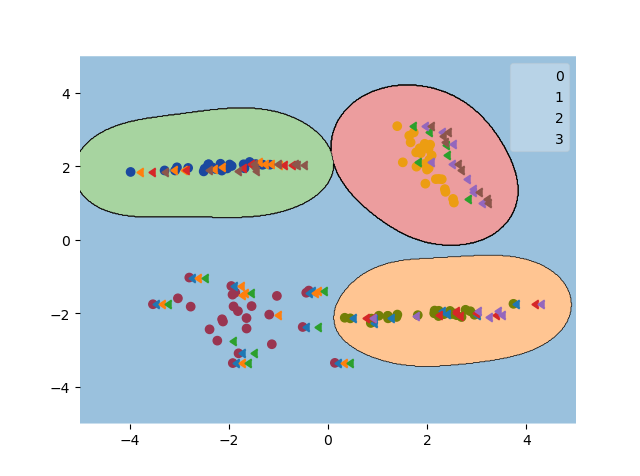
plt.show()绘制结果:















 255
255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









