





用Linux系统跑DeepFaceLab的文章我之前已经写过好几篇,有专门针对阿里云的,也有专门针对滴滴云的。今天来搞一搞矩池云(Linux系统安装DFL最新版)。
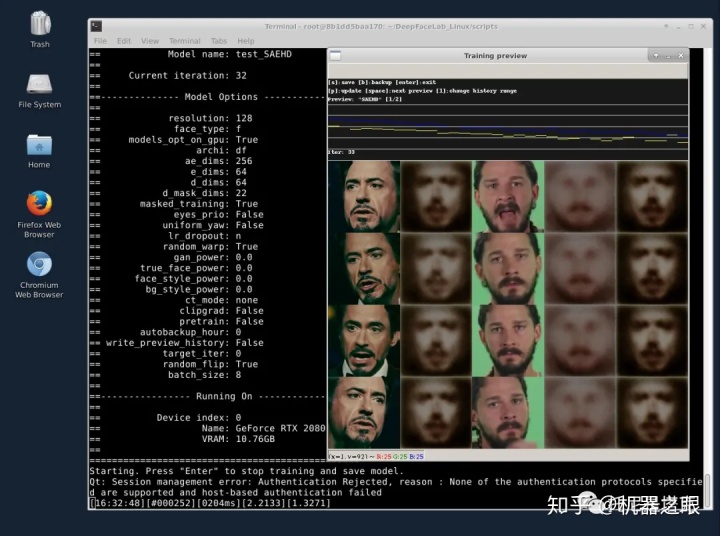
这次的搞法会和以前不一样,这次将用可视化算的方法使用Linux,在便捷性上会有大幅的提升。基本能实现和window远程桌面一样的效果。对于使用远程Linux系统的人来说,是一种非常方便的一种方式。
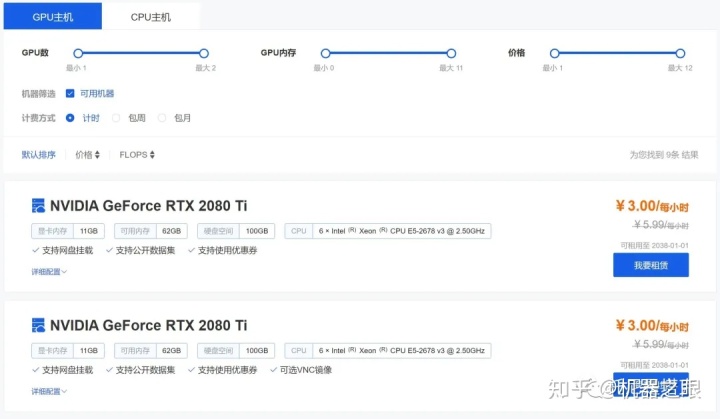
矩池云主要是按时间出租2080ti等游戏显卡,价格上来说还是比较有优势,同时深度学习的镜像种类非常多,可以直接使用预装各种Python,tensorfolw,pytorch版本的镜像。对于按时租用,不停中断的平台来说,一个直接可用的预装系统非常重要,可以节省你的时间,时间就是钱啊。近期推出了预装VNC的镜像,这样操作就更加便捷了。
期间也有不少人问过我这个(这类)平台怎么跑DeepFaceLab,今天我就专门写篇文章吧。整个流程我已经提前扫雷。
开干!!!
- 矩池云的使用
- 安装和使用VNC客户端。
- 配置Conda和PiP镜像
- 安装ffmpeg
- 创建虚拟环境
- 获取源代码并安装依赖
- 可视化的方式使用DeepFaceLab
别看细分步骤那么多,其实网络好的话,操作起来非常快。
- 矩池云的使用
矩池云可以按时,按周,按月购买。我这里演示按时购买。
在主机市场上面选择合适的显卡,主要是2080ti和2070,选择的时候还需要注意一点,必须选“可选VNC镜像”的机子 。选好后点击蓝色的我要租用按钮。
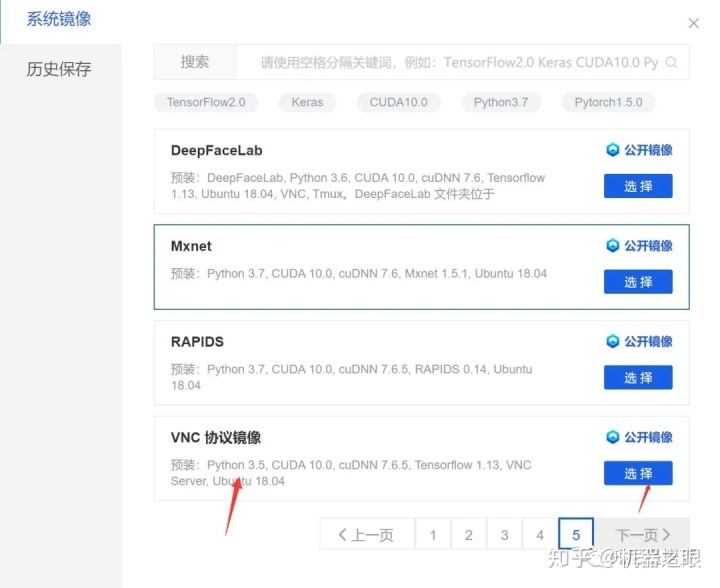
然后选择镜像,VNC镜像目前在最后一页,也可以通过搜索VNC 找到,找到后点击选择。还可以使用自己的历史镜像。然后设置一下系统密码,点击下单就好了。
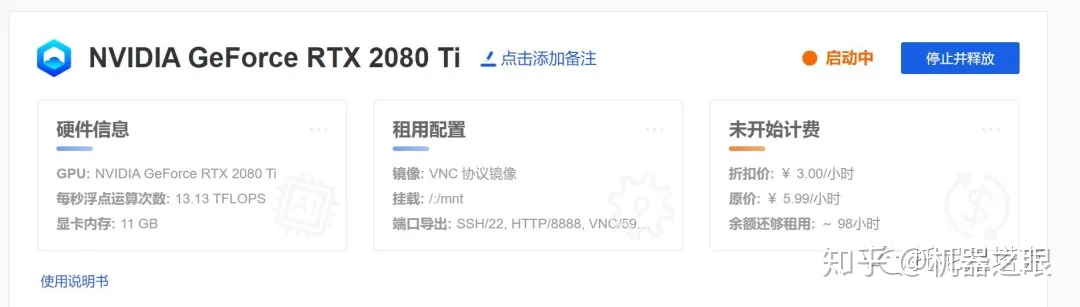
然后页面会跳转到如上界面,右上角显示启动中。

稍等片刻就会出现运行中。此时左边会出现SSH链接,JupyterLab 链接,VNC链接。点击VNC链接后面的小图标复制地址。这个地址在下一步使用VNC的时候会用到。
- 安装和使用VNC客户端。
软件的获取和安装都非常简单。详细的方法可以参考:
https://www.matpool.com/supports/doc-vnc-connect-matpool/
就是一路Next,安装完成后在windows的开始菜单找到图标打开。
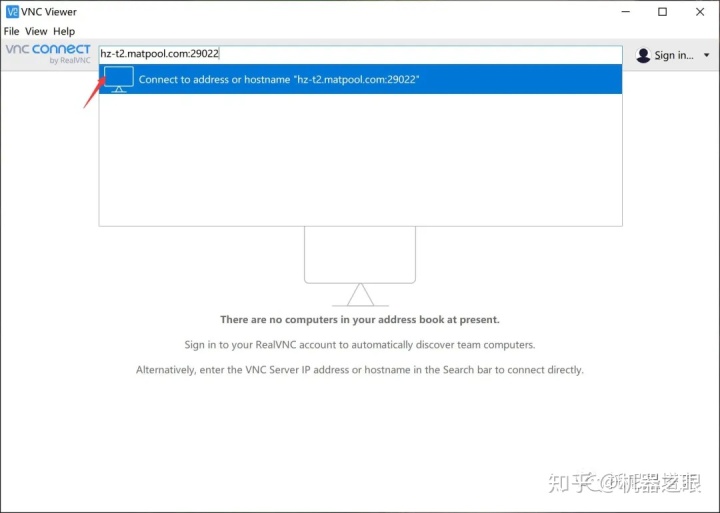
然后把地址黏贴在输入框中,点击箭头所指,就会跳出一个窗口,输入密码,勾选就可以进入服务器桌面了。
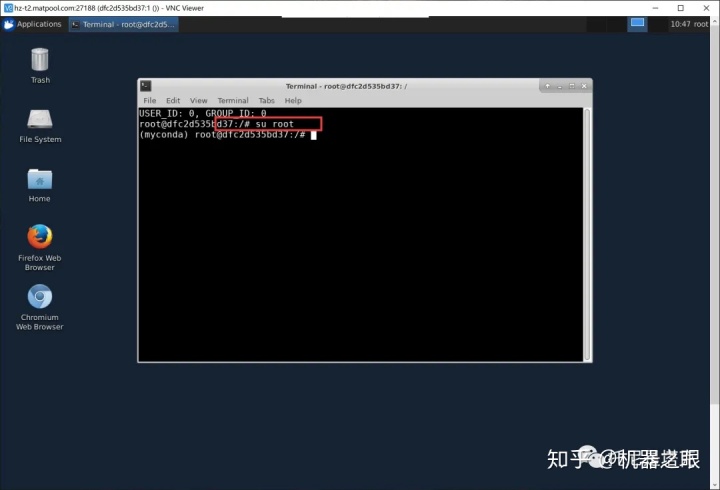
进入root ,不进入无法使用conda虚拟环境。左上角applications 的地方打开命令行工具,输入:
su root
cd ~- 配置Conda和Pip镜像
time is money 所以这一步非常重要。这里不配置,你既有可能一天都装不完成。其实矩池云本身是有设置了一部分镜像源,按理说应该很快,但是实测还是卡住了。所以我把这几类镜像源的设置方法写一写。
设置conda镜像源
进入用户目录,创建配置文件
cd ~
conda config --set show_channel_urls yes
vi .condarc按a进入编辑模式,复制下面的内容黏贴,然后按 ESC -> :->wq->enter 保存修改内容
channels:
- defaults
show_channel_urls: true
channel_alias: https://mirrors.tuna.tsinghua.edu.cn/anaconda
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud清除索引缓存,保证用的是镜像站提供的索引
conda clean -i 设置pip镜像源
需要先手动创建配置文件
mkdir .pip
vi .pip/pip.conf 复制黏贴下面的内容
[global]
timeout = 6000
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host=pypi.tuna.tsinghua.edu.cn保存修改即可。
矩池云官方提供了切换镜像源的脚本,操作起来会更加方便一些:
sh /public/script/switch_pip_source.sh 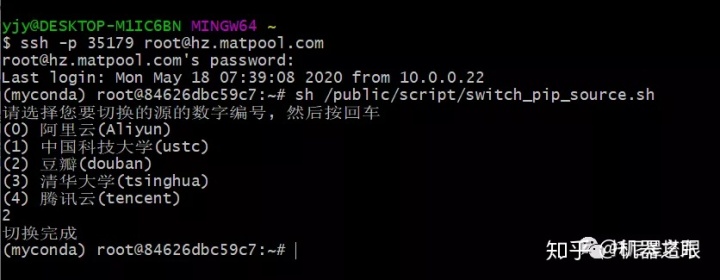
- 安装ffmpeg
Linux平台下FFMEPG往往需要自己安装,为了快速安装ffmpeg,又需要自己设置apt镜像源....(默认20kB/s不到)

设置apt镜像 ,先备份原有的配置文件,然后打开需要修改的文件。
cp /etc/apt/sources.list /etc/apt/sources.list.backup
vim /etc/apt/sources.list黏贴以下内容后保存
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial main restricted
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-updates main restricted
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-updates universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial multiverse
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-updates multiverse
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-backports main restricted universe multiverse
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-security main restricted
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-security universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-security multiverse 更新软件源头
apt-get update 安装 ffmpeg(不装后面会直接报错)
apt install ffmpeg 或者可以使用矩池云一键切换脚本
sh /public/script/switch_apt_source.sh - 创建虚拟环境并激活
使用conda可以非常便捷的创建deepfacelab所需的运行环境。一个命令就会自动安装python,cuda,cudnn等必须的内容。因为上面已经做了一些处理,这个安装过程会很快完成。
conda create -n deepfacelab python=3.6.8 cudnn=7.6.5 cudatoolkit=10.0.130
conda activate deepfacelab- 获取源代码并安装依赖
这一步主要是github的获取时间问题,国内环境要clone源代码的话,可能得好几天。window我们可以用代理,linux上只能是通过gitee来加速了。背后的工作我已经做完,只要执行一下命令即可。
git clone https://github.com/lbfs/DeepFaceLab_Linux.git
cd DeepFaceLab_Linux
git clone https://gitee.com/dream80/DeepFaceLab.git
python -m pip install -r ./DeepFaceLab/requirements-cuda.txt获取测试素材
git clone https://gitee.com/dream80/DFLWorkspace.git workspace 进入脚本目录
cd scripts “不可见字符坑”
上面的步骤做完之后,还有这个字符坑需要填。解决方法在滴滴云那篇文章中有提到过。去deepfacelab的目录找到nn.py这个文件,用VI打开找到红色框中的内容
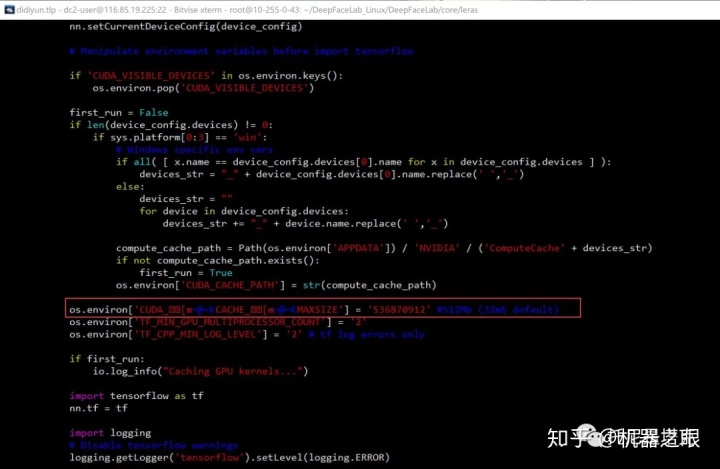
然后把[] 里面的内容手动删除,手动输入CUDA_CACHE_MAXSIZE
os.environ['CUDA_CACHE_MAXSIZE'] = '536870912' #512Mb (32mb default) 然后进入scripts目录,就可以执行各种脚本了,在以往的Linux教程中,我们没法直接筛选素材,没法看到可视化的训练界面,没法使用可视化的合成界面。这一次,这一些都可以可视化了。
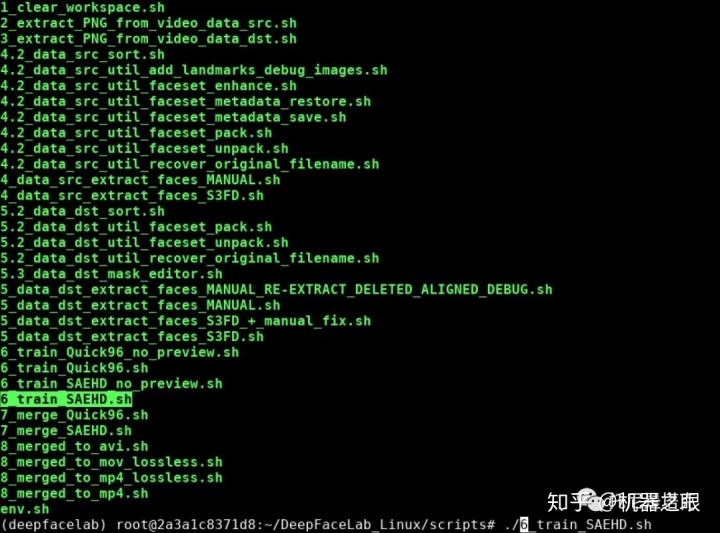
到了这里我们就可以按照DFL工作流程来一步一步运行了。在命令行中输入脚本名称即可运行。比如视频转图片:
./2_extarct_PNG_from_video_data_src.sh 以往我们通过命令行的方式训练模型都是使用nopreview的脚本。这次我们可以直接使用train _saehd.sh 。启动后可以直接看到界面,支持所有预览图上的快捷键,合成的时候也可以启用可视化交互界面。
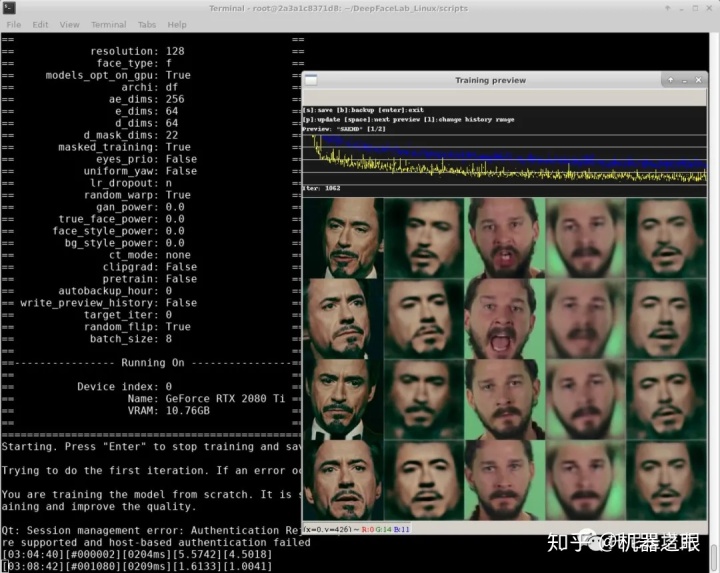

一切运行成功之后,下次使用只需打开终端命令行工具,切换到root (su root), 进入用户目录(cd ~),然后激活虚拟环境(conda activate deepfacelab),然后就可以运行相应的脚本了。

第一次使用这个系统,并且踩了各种坑,记录中间过程,用时大概两个小时。第二次写文章,又搞了几个小时,主要是安装依赖莫名卡住了... 最后做了个镜像,以后就方便了!矩池云部分实例支持镜像保存和还原功能,意思就是即便中断了,下次再次购买时,无需重新配置环境,直接使用。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









