





原创作者:如人饮水冷暖自知
责任编辑:AcDante



前言
开门见山,今天和大家聊聊如何对PL/SQL代码进行优化,以及如何编写高效的PL/SQL代码,如果您是开发DBA,或者您是数据库开 发人员,对于PL/SQL苦苦纠结应该如何优化,请耐心把本篇文章看完,文章内容涉及的知识点较多,案例也相对较多,请您跟紧我的思 路,耐心看完,谢谢。为了更好的阅读体验,我们主要分享如下主题:
PL / SQL优化器
候选人调优
减少CPU开销如何
批量SQL和批量绑定
为多个转换链接管道化的表函数
并行更新大表
收集关于用户定义标识符的数据
分析和跟踪PL/SQL程序
编译用于本机执行的PL/SQL单元
PL/SQL优化器
在Oracle10g之前,PL/SQL编译器是将源文本翻译成系统代码,而没有应用很多更改来提高性能。到了Oracle 11gR2版本 以后PL/SQL使用了一个优化器,它可以重新排列代码以获得更好的性能
优化器在默认情况下是启用的。在极少数情况下,如果优化器的开销使非常大的应用程序的编译太慢,我们可以通过设置编 译参数PLSQL_OPTIMIZE_LEVEL=1而不是其默认值2来降低优化。在更罕见的情况下,PL/SQL可能会比预期更早地抛出异常,或 者根本不会抛出异常。设置PLSQL_OPTIMIZE_LEVEL=1可以防止重新排列代码
子程序内联
编译器可以执行的一种优化是子程序内联。子程序内联使用被调用子程序的副本替换子程序调用(如果被调用和调用的子程序 位于同一程序单元中)。要允许子程序内联,要么接受PLSQL_OPTIMIZE_LEVEL编译参数的默认值(即2),要么将其设置为3
使用PLSQL_OPTIMIZE_LEVEL=2,必须指定每个子程序与内联的pragma,如果子程序被重载,则前面的pragma应用于具 有该名称的每个子程序
PLSQL_OPTIMIZE_LEVEL=3的情况下,PL/SQL编译器寻找机会进行内联子程序。我们不需要指定要内联的子程序。但是, 我们可以使用内联pragma(使用前面的语法)为内联赋予一个子程序较高的优先级
如果子程序内联降低了特定PL/SQL程序的性能,那么使用PL/SQL分层分析器(在Oracle Database Advanced Application Developer指南中进行了解释)来识别我们希望关闭内联的子程序。要关闭子程序的内联,就需要使用内联pragma
调优查询中的function调用,从而降低cpu利用率
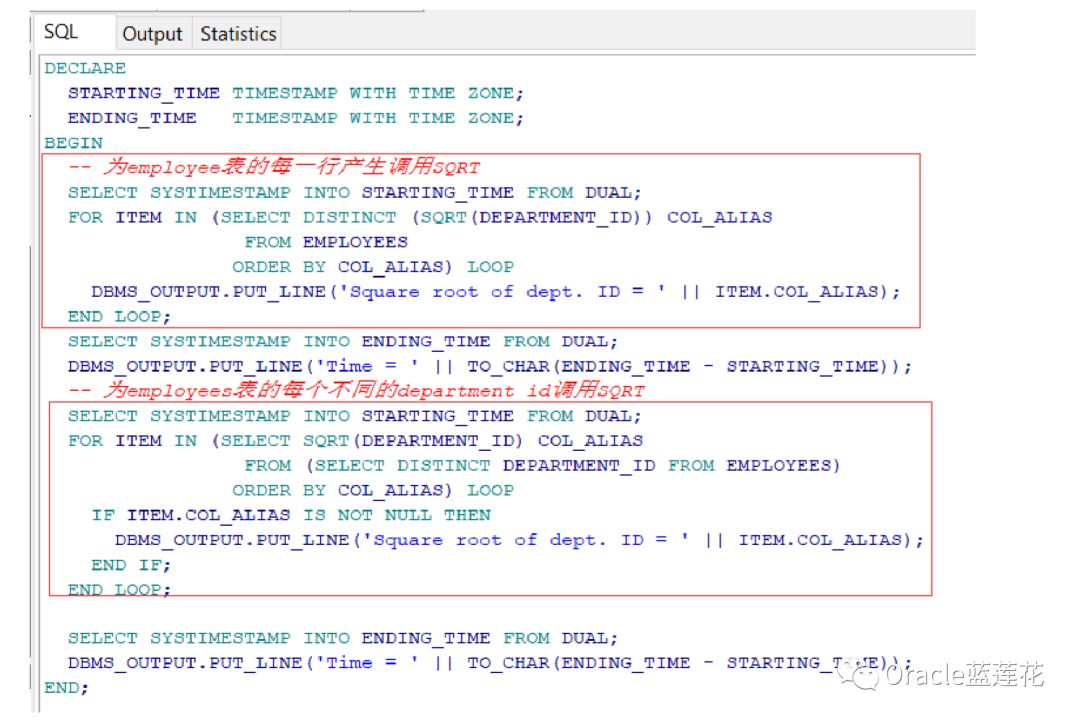
如果查询过程中使用了自定义函数,那么可能日常生产oltp环境会被调用几百万甚至上千万次,我们通过函数索引作用在自 定义函数上,这样可以缓存每一行的函数值。
如果查询将一个列传递给自定义函数,那么查询就不能在该列上使用用户创建的索引,因此查询可能会为表的每一行产生(可 能非常大)调用该函数。要最小化函数调用的数量,需要使用嵌套查询。让内部查询将结果集过滤为少量的行,并让外部查询仅为这 些行调用该函数
来看一个例子,两个查询生成相同的结果集,但是第二个查询比第一个查询更有效
我们来看一个例子
调整子查询调用
如果子程序有OUT或IN OUT参数,有时可以通过使用NOCOPY提示(在“NOCOPY”中描述)声明这些参数来减少其调用开销
默认情况下,PL/SQL按值传递和传入子程序参数。在运行子程序之前,PL/SQL将每个OUT和IN OUT参数复制到一个临时变 量中,该变量在子程序执行期间保存参数的值。如果子程序正常退出,则PL/SQL将临时变量的值复制到对应的实际参数。如果子程 序以未处理的异常退出,则PL/SQL不会更改实际参数的值
当OUT或IN OUT参数表示大型数据结构(如集合、记录和ADT实例)时,复制它们会减慢执行速度并增加内存使用—特别是
对于ADT实例 对于ADT方法的每次调用,PL/SQL都会复制ADT的每个属性。如果该方法正常退出,那么PL/SQL将应用该方法对属性所做 的任何更改。如果方法以未处理的异常退出,则PL/SQL不会更改属性
如果您的程序在子程序以未处理的异常结束时不要求OUT或IN OUT参数保留其预调用值,则在参数声明中包含NOCOPY提 示。NOCOPY提示请求(但不确保)编译器通过引用而不是值传递相应的实际参数。有关NOCOPY的更多信息直接参考Oracle官网, 由于篇幅问题这里就不过多介绍了。
如果编译器遵循调用do_nothing2的NOCOPY提示,那么do_nothing2的调用比do_nothing1的调用快
我们来看一个例子

优化计算密集型PL/SQL代码
由于PL/SQL应用程序通常是围绕循环构建的,因此优化循环本身和其中的代码非常重要。如果我们必须不止一次地遍历结 果集,或者在遍历结果集时发出其他查询,那么可能能够更改原始查询,以得到我们想要的结果。这时候我们通常允许程序组合多 个查询的SQL集合操作符
避免使用NUMBER数据类型族(在“NUMBER数据类型族”中描述)中使用数据类型。这些数据类型在内部以一种设计用于 可移植性、任意规模和精度的格式表示,而不是为了性能。对这些类型的数据的操作使用库算法,而对PLS_INTEGER、 BINARY_FLOAT和BINARY_DOUBLE类型的数据的操作使用硬件算法
对于本地整数变量,使用PLS_INTEGER和BINARY_INTEGER数据类型。对于不具有NULL值、不需要溢出检查并且在性能关 键代码中不使用的变量,使用PLS_INTEGER的SIMPLE_INTEGER
避免在性能关键型代码中使用受约束的子类型
在性能关键型代码中,避免使用受约束的子类型(在“受约束的子类型”中描述)。对受约束子类型的变量或参数的每个赋值 都需要在运行时进行额外检查,以确保所赋值不违反约束
最小化隐式数据类型转换
在运行时,如果需要,PL/SQL在不同数据类型之间隐式(自动)转换。例如,如果将PLS_INTEGER变量分配给数字变量,那 么PL/SQL将PLS_INTEGER值转换为数字值(因为值的内部表示不同)
如果要将变量插入表列或从表列中指定值,则为该变量指定与表列相同的数据类型
使每个字面值与赋值给它的变量或出现在其中的表达式的数据类型相同。
将值从SQL数据类型转换为PL/SQL数据类型,然后在表达式中使用转换后的值
例如,将数字值转换为PLS_INTEGER值,然后在表达式中使用PLS_INTEGER值。PLS_INTEGER操作使用硬件运算,因此它 们比使用库运算的NUMBER运算要快
批量sql绑定
当我们尝试在pl/sql运行SELECT INTO或DML语句,PL/SQL引擎将查询或DML语句发送到SQL引擎。SQL引擎运行查询或 DML语句,并将结果返回给PL/SQL引擎
组成批量SQL的PL/SQL特性是FORALL语句和bulk COLLECT子句。FORALL语句将DML语句从PL/SQL分批发送到SQL,而 不是一次发送一条。BULK COLLECT子句将结果从SQL分批返回到PL/SQL,而不是一次返回一个。如果查询或DML语句影响更多 数据库行,那么批量SQL可以显著提高性能
对于内绑定和外绑定,bulk SQL使用批量绑定;也就是说,它一次绑定整个值集合。对于n个元素的集合,bulk SQL使用一 个操作来执行相当于n个SELECT INTO或DML语句的操作。使用批量SQL的查询可以返回任意数量的行,而不需要为每一行使用 FETCH语句
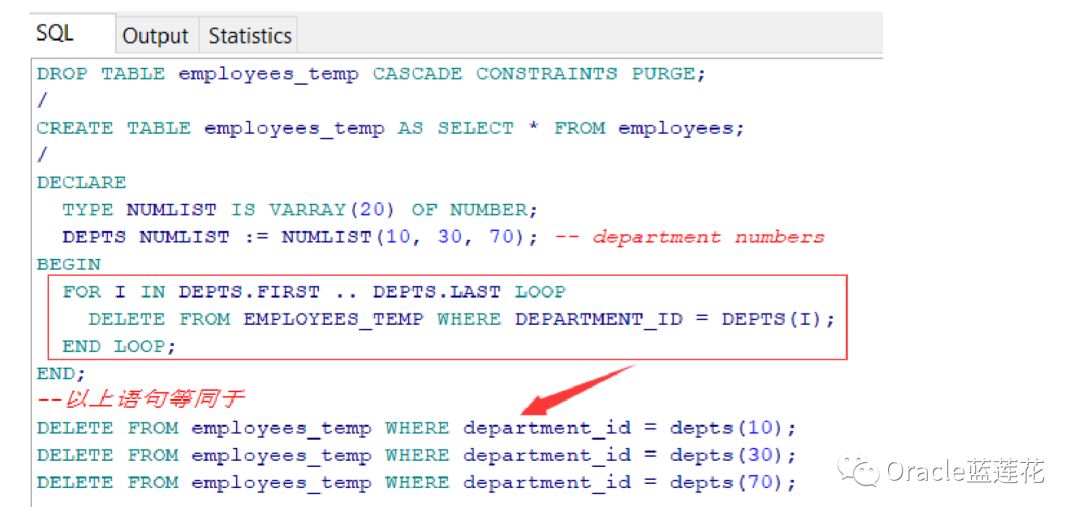
FORALL语句是bulk SQL的一个特性,它将DML语句从PL/SQL分批发送到SQL,而不是一次发送一条。要理解FORALL语 句,我们首先考虑下面小案例中的FOR循环语句。它每次将这些DML语句从PL/SQL发送到SQL引擎
我们来看一个例子
利用批量绑定后的代码如下:
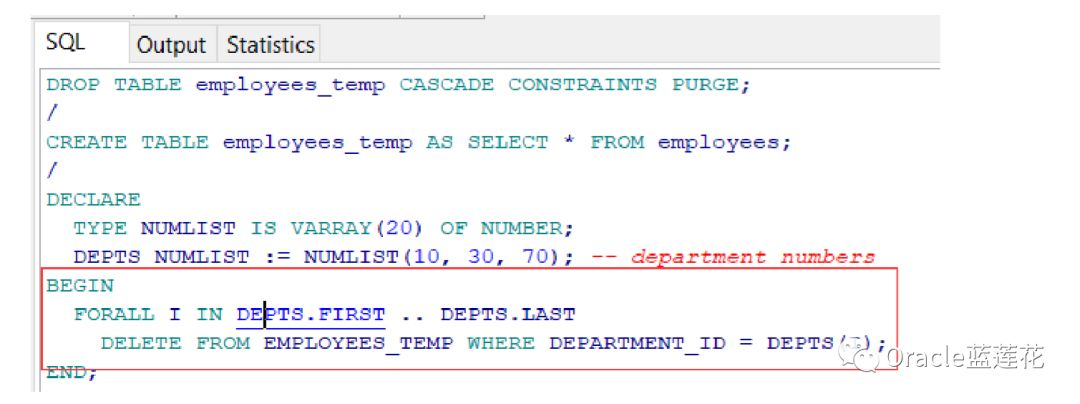
FORAL比等效的FOR循环语句快得多。然而,FOR循环通常语句可以包含多个DML语句,而FORALL语句只能包含一个。 FORALL语句发送给SQL的DML语句的批处理只在它们的值和WHERE子句中有所不同。这些子句中的值必须来自现有的、填充的集合
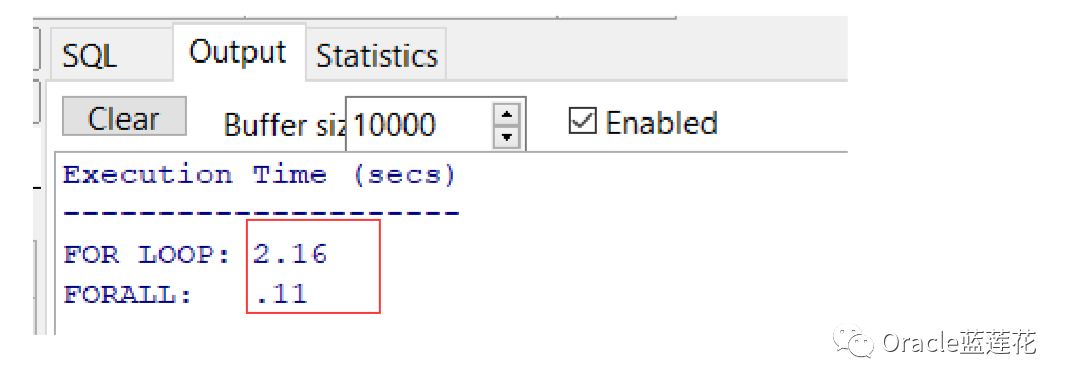
再看整合上面例子里的代码,下面的案例是将相同的集合元素插入两个数据库表中,第一个表使用FOR循环语句,第二个表 使用FORALL语句,并显示每个语句所花费的时间

我们再看具体的执行结果截图
关于稀疏集合的FORALL语句
如果FORALL语句bounds子句引用稀疏集合,则仅指定现有索引值,使用子句的索引或值。除了按字符串索引的关联数组外,可 以为任何集合使用索引。只能对由PLS_INTEGER索引的PLS_INTEGER元素的集合使用值。
由PLS_INTEGER索引的PLS_INTEGER元素集合可以是索引集合;也就是说,指向另一个集合(索引集合)的元素的指针的集合
索引集合用于处理具有不同FORALL语句的相同集合的不同子集。与其将原始集合的元素复制到表示子集(可能会占用大量时间和 内存)的新集合中,不如使用索引集合表示每个子集,然后在不同FORALL语句的VALUES子句中使用每个索引集合
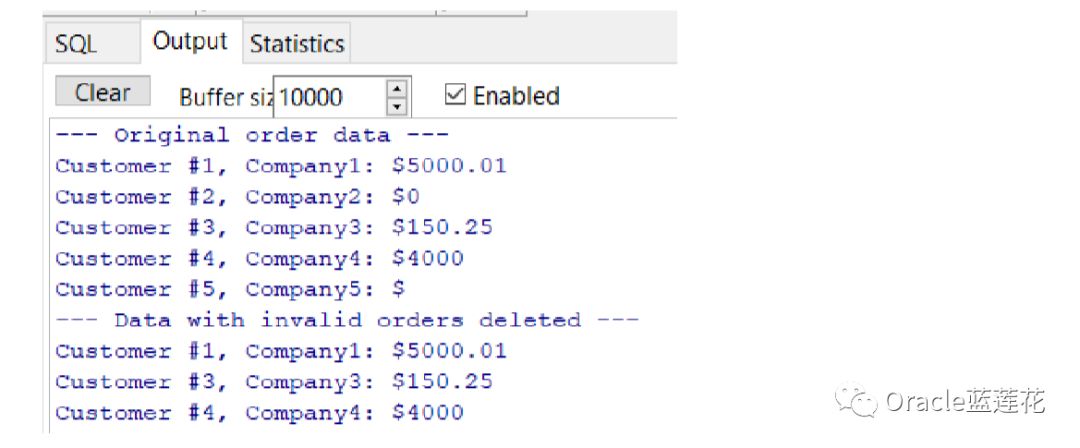
使用带有index OF子句的FORALL语句用稀疏集合的元素填充表。然后,它使用带有子句值的两个FORALL语句用集合的子集填 充两个表
我们来看一个例子

结果集截图如下
FORALL语句未处理的异常行为
在没有SAVE exception子句的FORALL语句中,如果一个DML语句引发一个未处理的异常,那么PL/SQL将停止FORALL语 句并回滚以前DML语句所做的所有更改
若要立即处理FORALL语句中引发的异常,需要省略SAVE exceptions子句并编写适当的异常处理程序。(有关异常处理程序 的信息这里我们不多讲,还是看官网,没办法扩展太多内容信息))如果一条DML语句引发了一个已处理的异常,那么PL/SQL回滚该 语句所做的更改,但不回滚以前的DML语句所做的更改
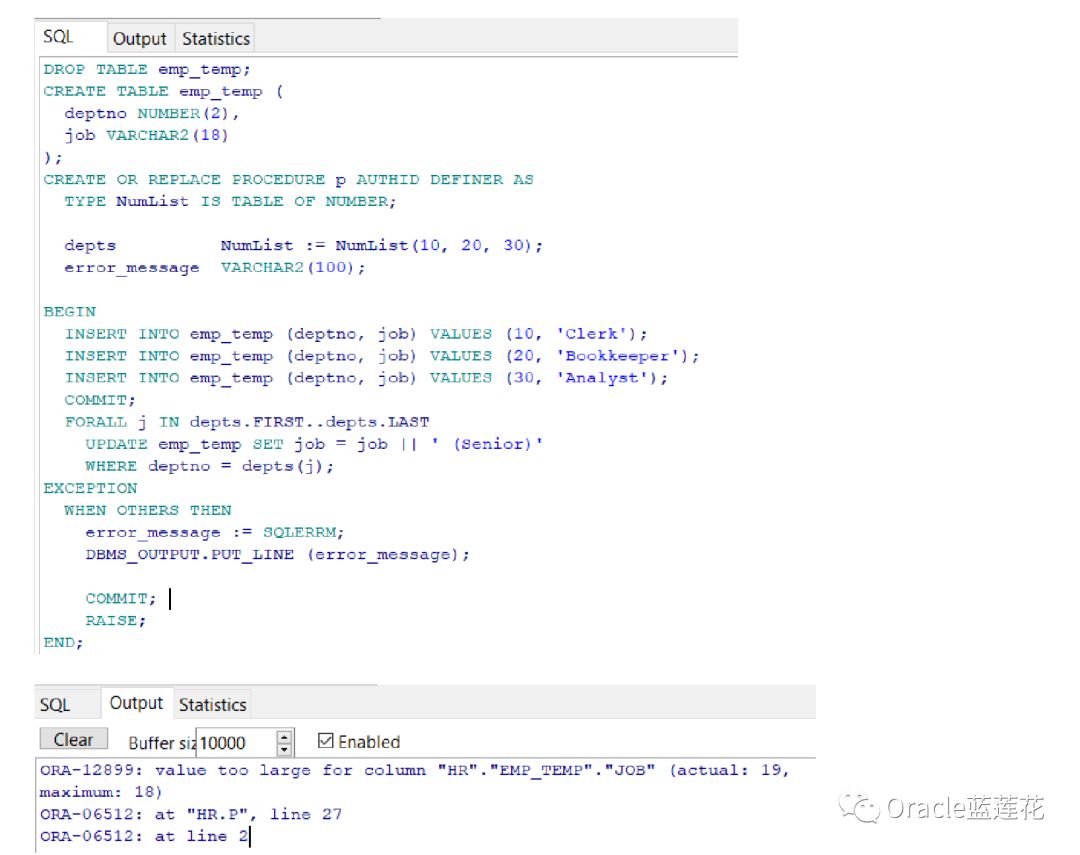
来看一个例子,FORALL语句被设计为运行三个UPDATE语句。但是,第二个会引发异常。异常处理程序处理异常,显示错误消息并提交第一个UPDATE语句所做的更改。第三条UPDATE语句从不运行
我们来看一个例子
那么我们如何在FORALL语句完成以后在处理异常呢,若要允许FORALL语句在某些DML语句失败的情况下继续执行,请包 含SAVE exception子句。当DML语句失败时,PL/SQL不会引发异常;相反,它保存有关失败的信息。在FORALL语句完成之 后,PL/SQL为FORALL语句(ORA-24381)引发一个异常。在ORA-24381的异常处理程序中,可以从隐式游标属性
SQL%BULK_EXCEPTIONS获得关于每个DML语句失败的信息,以下为Oracle官方部分介绍:
SQL%BULK_EXCEPTIONS is like an associative array of information about the DML statements that failed during the most recently run FORALL statement.
SQL%BULK_EXCEPTIONS.COUNT is the number of DML statements that failed. If
SQL%BULK_EXCEPTIONS.COUNT is not zero, then for each index value i from 1 through
SQL%BULK_EXCEPTIONS.COUNT:
SQL%BULK_EXCEPTIONS(i).ERROR_INDEX is the number of the DML statement that failed.
SQL%BULK_EXCEPTIONS(i).ERROR_CODE is the Oracle Database error code for the failure.
For example, if a FORALL SAVE EXCEPTIONS statement runs 100 DML statements, and the tenth and sixty-fourth ones fail with error codes ORA-12899 and ORA-19278, respectively, then:
SQL%BULK_EXCEPTIONS.COUNT = 2
SQL%BULK_EXCEPTIONS(1).ERROR_INDEX = 10
SQL%BULK_EXCEPTIONS(1).ERROR_CODE = 12899
SQL%BULK_EXCEPTIONS(2).ERROR_INDEX = 64
SQL%BULK_EXCEPTIONS(2).ERROR_CODE = 19278
FORALL语句包含SAVE exception子句。
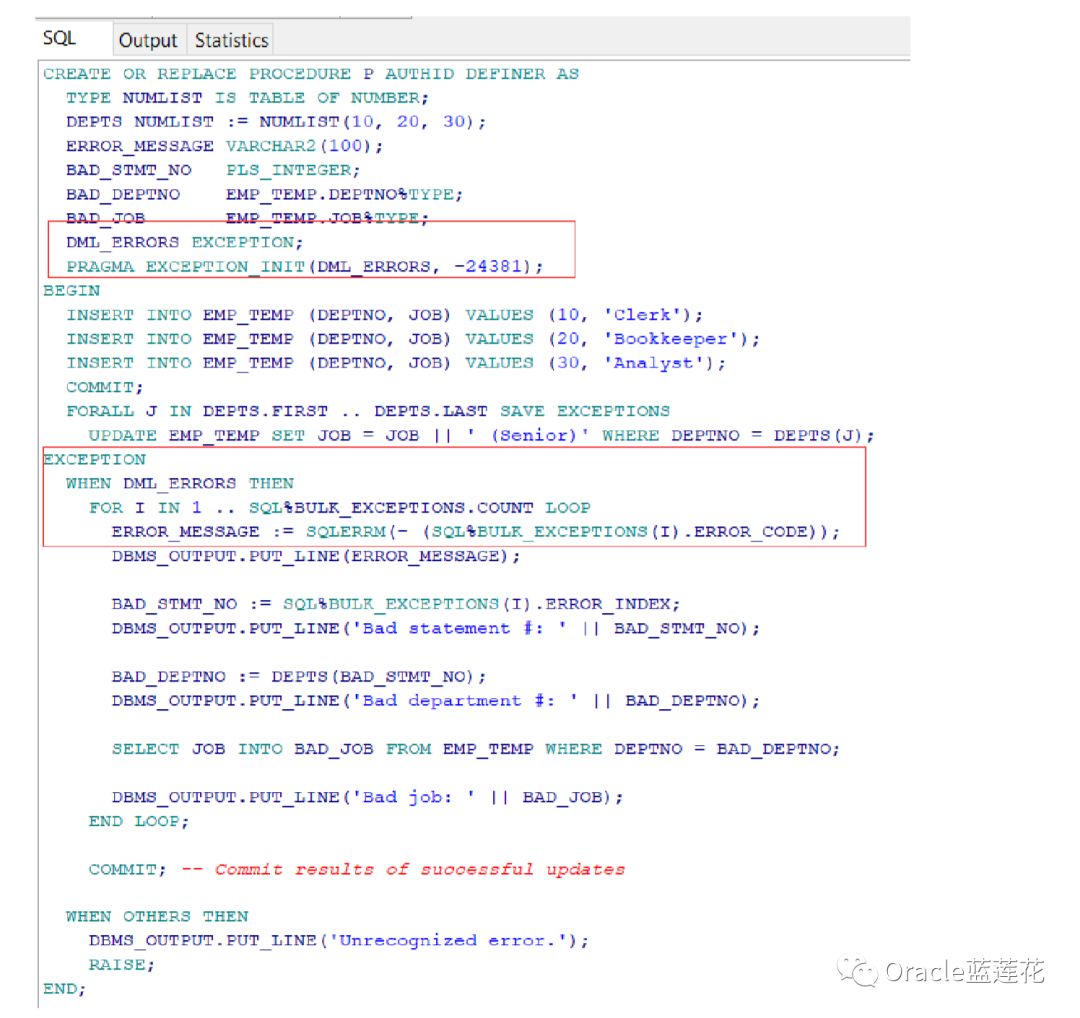
异常处理部分为ORA-24381提供了一个异常处理程序,当批量操作引发并保存异常时,PL/SQL将隐式地引发内部定义的异 常。这个示例为ORA-24381提供了用户定义的名称dml_errors。
我们来看一个例子
dml_errors的异常处理程序使用SQL%BULK_EXCEPTIONS和SQLERRM(以及一些本地变量)来显示错误消息,以及导致错误的语句、集合项和字符串。看下面的代码示例
稀疏集合和SQL%BULK_EXCEPTIONS
如果FORALL语句bounds子句引用了一个稀疏集合,那么要找到导致DML语句失败的集合元素,必须逐个遍历这些元素,直到 找到索引为SQL%BULK_EXCEPTIONS(i). error_index的元素。然后,如果FORALL语句使用VALUES OF子句引用指向另一个集合的 指针集合,则必须找到另一个集合的元素,该集合的索引是SQL%BULK_EXCEPTIONS(i). error_index

使用SQL%BULK_ROWCOUNT显示插入的FORALL语句中每个INSERT SELECT构造的行数,使用SQL%ROWCOUNT显示插入的 行数

结果截图显示如下:
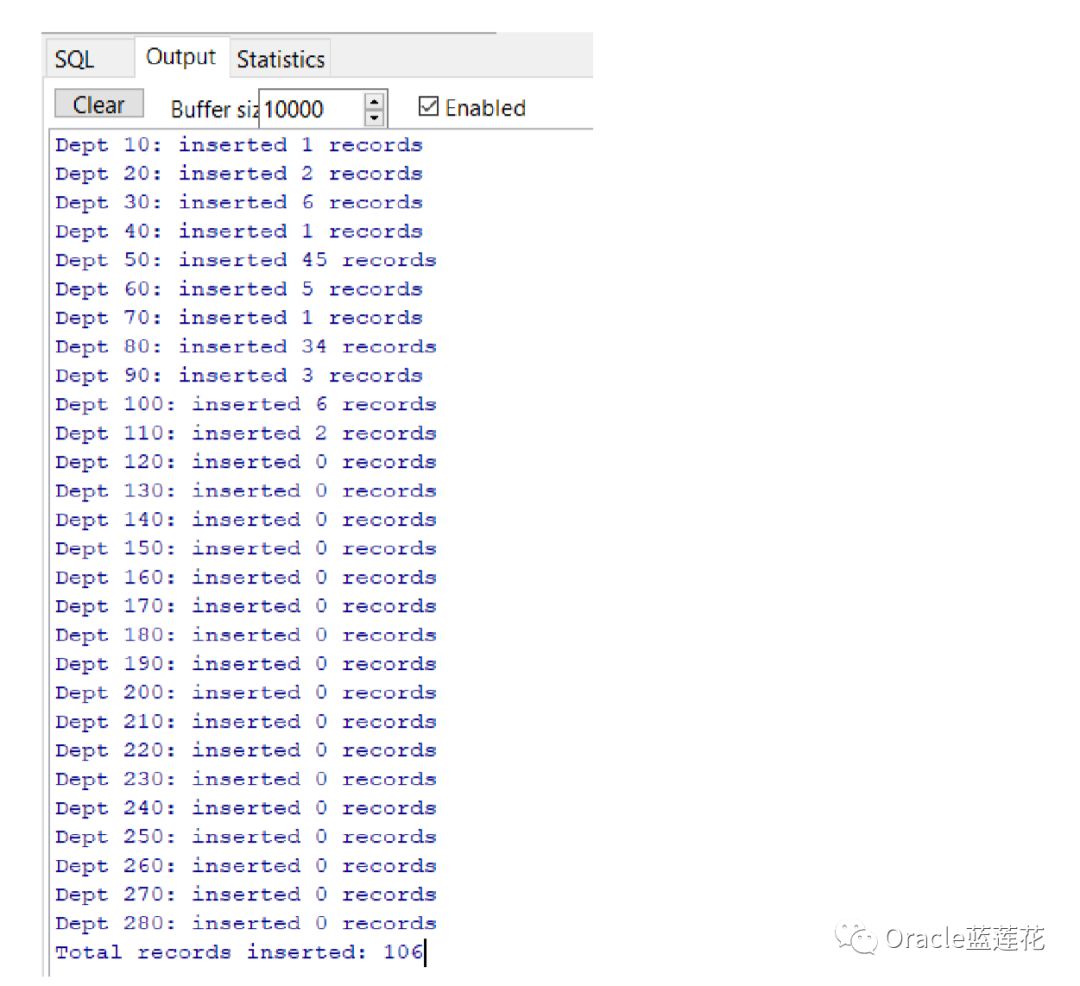
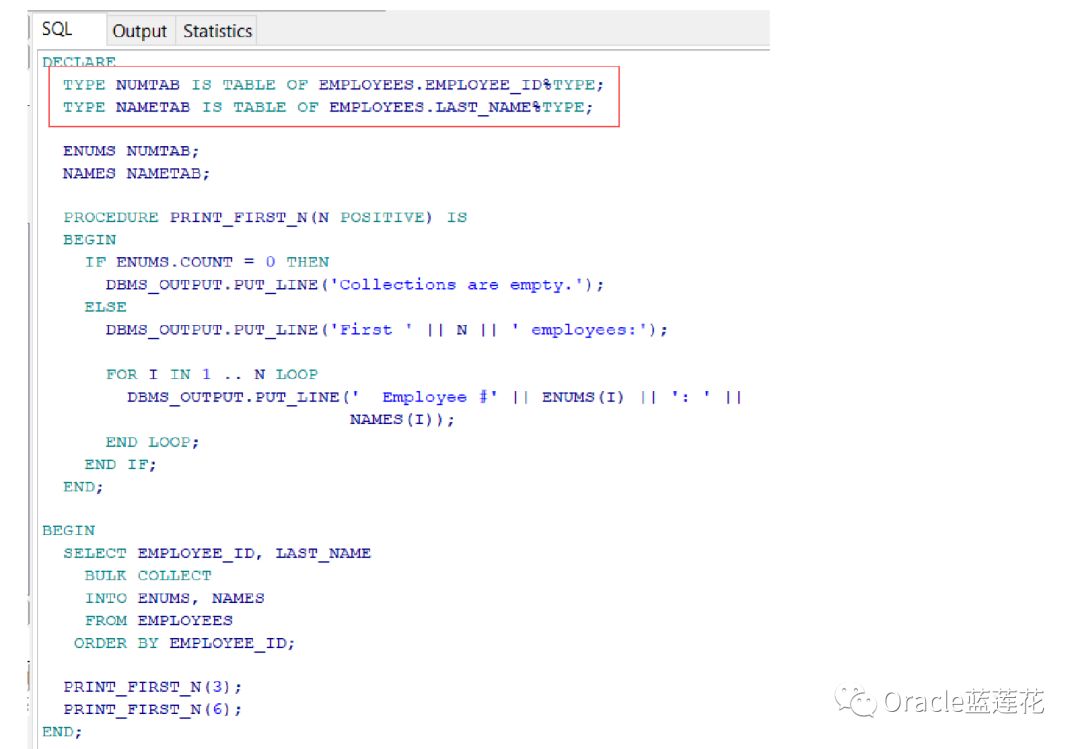
使用SELECT BULK COLLECT INTO语句将两个数据库列选择为两个集合(嵌套表)
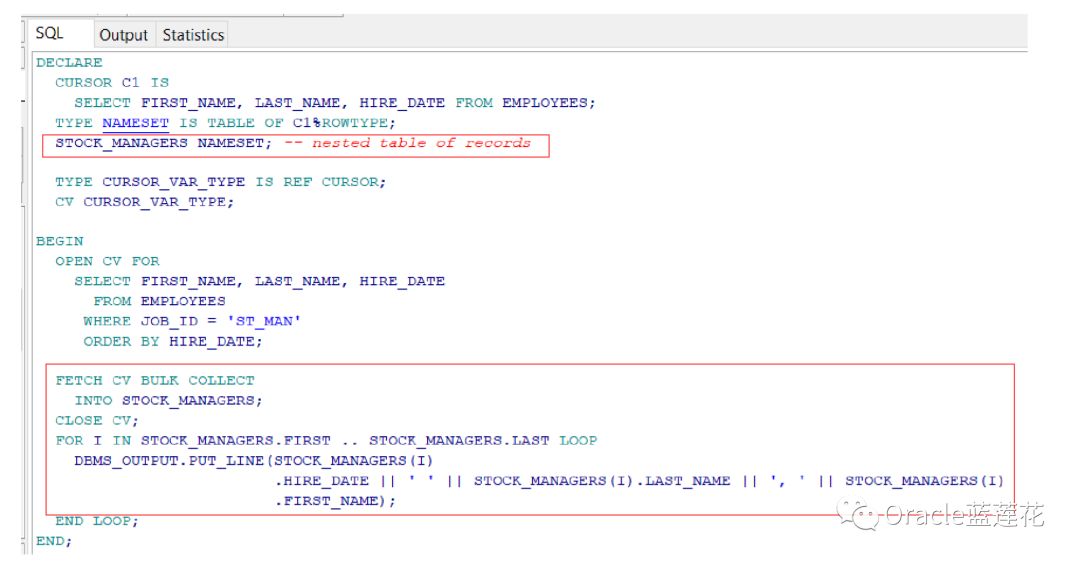
带有BULK COLLECT子句的FETCH语句(也称为FETCH BULK COLLECT语句)将整个结果集提取到一个或多个集合变量中,来看下面的例子:

代码太长,哈哈,截图截不下,只能复制原代码,下面的例子是使用FETCH BULK COLLECT语句将结果集提取到记录的集合(嵌 套表)中
为多个转换链接管道化的表函数
表函数是用户定义的PL/SQL函数,它返回行集合(嵌套的表或varray)。我们可以通过调用select语句中的table子句中的table函 数,从这个集合中进行选择,就好像它是一个数据库表一样
表函数可以接受一组行作为输入(也就是说,它可以有一个输入参数,该参数是一个嵌套的表、varray或游标变量)。因此,表函 数tf1的输出可以输入到表函数tf2,表函数tf2的输出可以输入到表函数tf3,
要提高表函数的性能,可以:
1.使用PARALLEL_ENABLE选项使函数能够并行执行。
2.支持并行执行的函数可以并发运行。
3.使用Oracle流将函数结果直接发送到下一个进程。
4.流消除了进程之间的中间阶段。有关Oracle Streams的信息,请参见Oracle Streams概念和管理。这超出本次分享范围了,只 是单纯提供一个技术idea
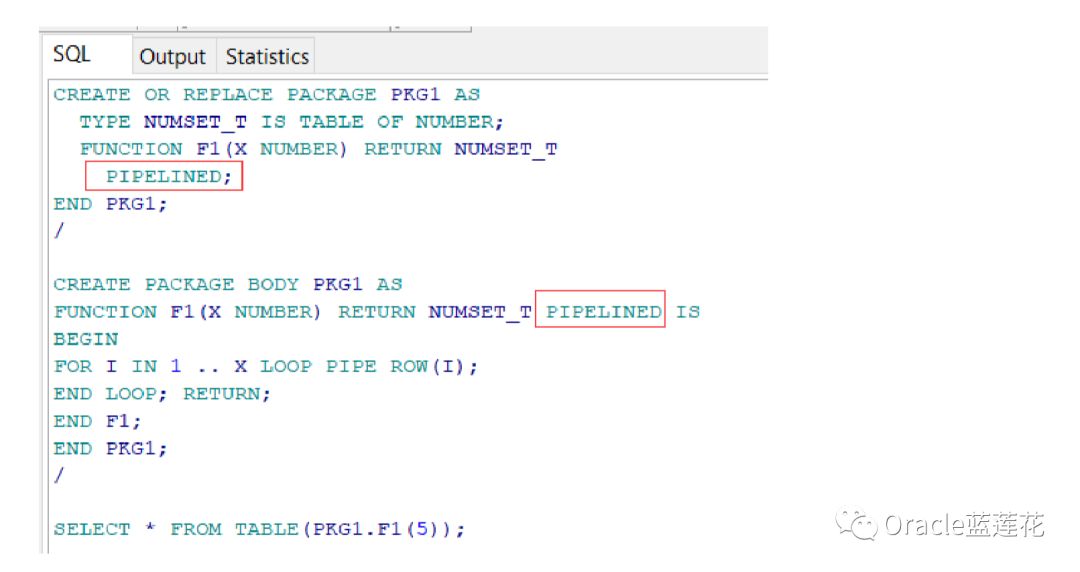
5.管道化函数的结果,带有管道化选项,也就是,我经常和600团队成员推荐的pipelined
4.管道化的表函数在处理行之后立即将行返回给它的调用程序,并继续处理行。响应时间有所改善,因为在查询返回单个结果行之 前,不需要构造整个集合并将其返回到服务器。(另外,函数需要更少的内存,因为对象缓存不需要物化整个集合)。
创建管道化的表函数
管道化的表函数必须是独立函数或包函数,管道化表函数返回的值的数据类型必须是在模式级别或包中定义的集合类型(因此,它 不能是关联数组类型)。集合类型的元素必须是SQL数据类型,而不是仅由PL/SQL支持的数据类型(如PLS_INTEGER和BOOLEAN)
可以使用SQL数据类型ANYTYPE、ANYDATA和ANYDATASET动态封装和访问任何其他SQL类型(包括对象和集合类型)的类型描 述、数据实例和数据实例集。我们还可以使用这些类型创建未命名类型,包括匿名集合类型
创建包含管道表函数f1的包,然后从f1返回的行集合中进行选择
管道化的表函数作为转换函数
具有游标变量参数的流水线表函数可以用作转换函数。使用游标变量,函数获取输入行。函数使用PIPE ROW语句将转换后的行 或行传输到调用程序。如果FETCH和PIPE ROW语句位于循环语句中,则函数可以转换多个输入行
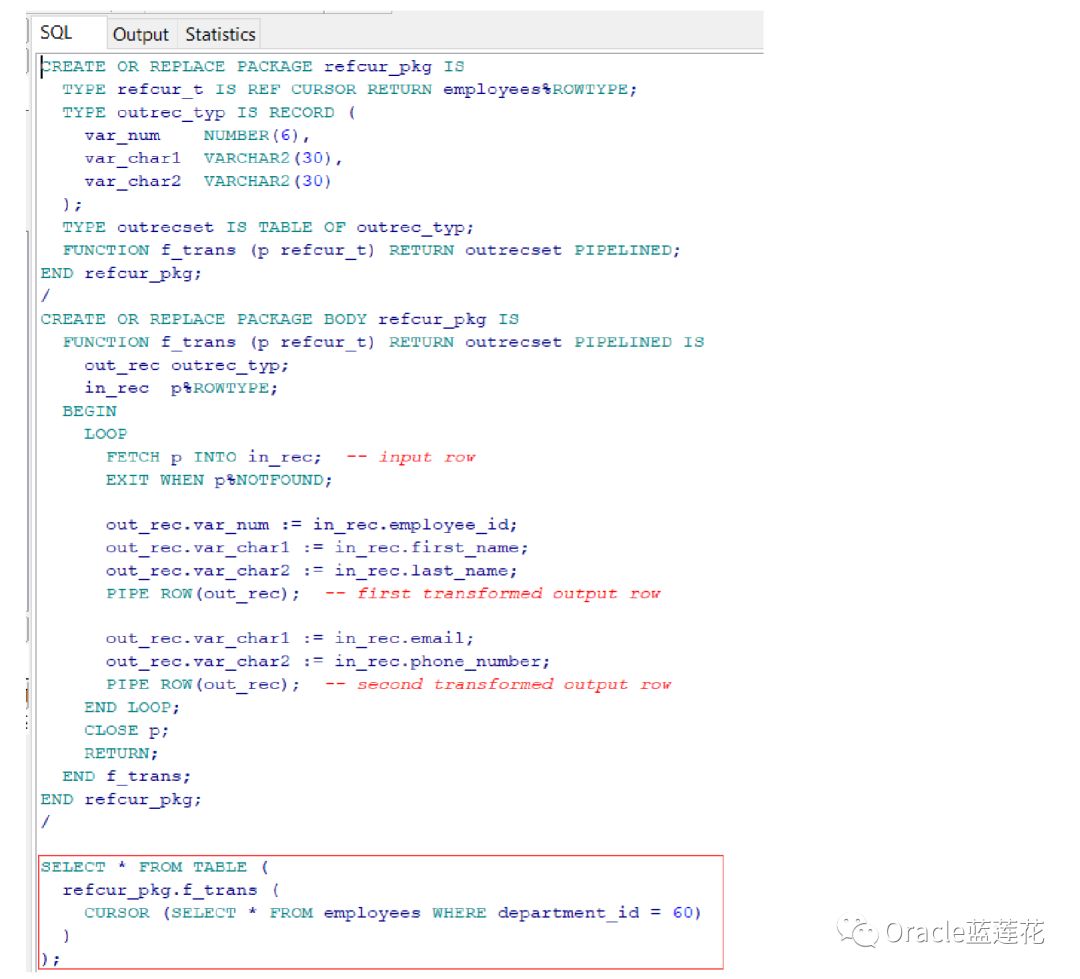
如何把cursor传递给管道函数
直接看例子吧,这里只需要具体的调用方式即可,sql工作原理和上面解释的内容相同

下面是一个综合案例:

如何并行更新大表
DBMS_PARALLEL_EXECUTE包使我们能够在两个高级步骤中并行地增量更新大型表中的数据:
将表中的行集分组为更小的块。
并行地对块应用所需的UPDATE语句,每次处理完块后提交。
在更新大量数据时,建议使用这种技术。它的优点是:
在相对较短的时间内,一次只锁定一组行,而不是锁定整个表。
如果在整个操作之前发生故障,我们不会丢失已经完成的工作
下面是我在2016年写的综合例子,大家感兴趣可以借鉴,切记,更新大表用dbms_parallel_execute



如何分析和跟踪PL/SQL程序
以下截图中的API,是PLSQL性能调优的利器,也是我之前做Oracle数据仓库期间,经常调优用到的程序包,这里也推荐给大家:

Profiler API实现为PL/SQL包DBMS_PROFILER,它的服务计算PL/SQL程序在每一行和每个子程序中花费的时间,并将这些 统计数据保存在数据库表中,我们可以查询这些数据字典表来分析程序
TRACE API(被实现为PL/SQL包DBMS_TRACE,其服务通过子程序或异常跟踪执行,并将这些统计信息保存在数据库表 中,我在之前分享的公众号文章中提到过trace的程序跟踪,如果您感兴趣,不妨回顾一下,真的很好用。










总
结
陈
词
优化PL/SQL程序代码是需要和业务应用紧密结合起来的工作,当然,像您学习Oracle Troubleshooting,分析awr报 告,rac报错一样,PL/SQL同样也存在工作原理,熟知这些工作原理,我们才能懂得如何使用方法和函数让程序跑的更快。
今天我们主要学习的方向包括PL/SQL优化器概念性介绍
批量绑定的使用方法和工作原理
管道函数方式降低cpu使用率和递归循环调用
如何更新一张超级大表,用什么方式更新
三个用来进行PL/SQL程序代码分析的利器,利器没有展开讲,以后如果您对我们文章感兴趣,我们可以单独通过案例讲解 方式帮助您如何使用这三个API来定位问题,谢谢

















 337
337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









