





数据集
minist数据集为
MNIST数据集原网址:http://yann.lecun.com/exdb/mnist/

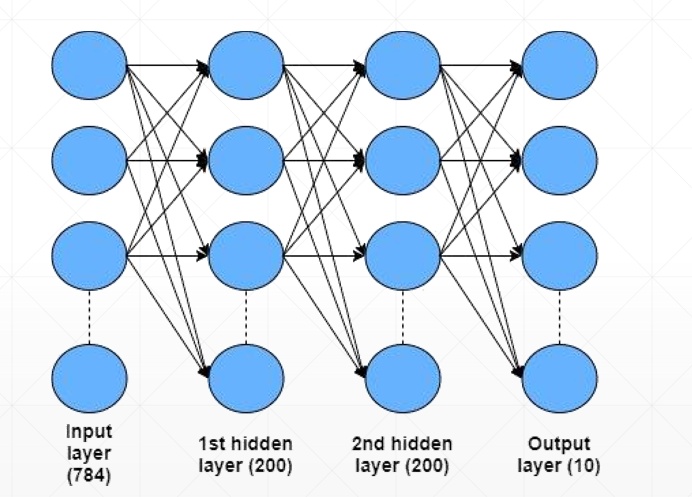
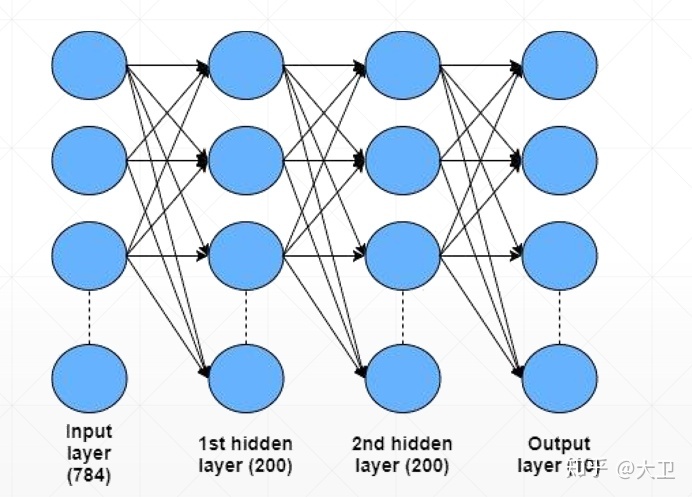
网络结构
3层全连接神经网络
PyTorch 实现
数据下载
import 权重随机初始化
w1,b1 = torch.randn(200,784,requires_grad=True),torch.zeros(200,requires_grad=True)
w2,b2 = torch.randn(200,200,requires_grad=True),torch.zeros(200,requires_grad=True)
w3,b3 = torch.randn(10,200,requires_grad=True),torch.zeros(10,requires_grad=True)Kaiming normal 权重初始化
torch.nn.init.kaiming_normal_(w1)
torch.nn.init.kaiming_normal_(w2)
torch.nn.init.kaiming_normal_(w3)前向传播
def forward(x):
x = torch.matmul(x,w1.t())+b1
x = F.relu(x)
x = torch.matmul(x,w2.t())+b2
x = F.relu(x)
x = torch.matmul(x,w3.t())+b3
x = F.relu(x)
return x定义优化器和损失函数
optimizer = optim.SGD(params=[w1,b1,w2,b2,w3,b3],lr=learning_rate)
criterion = nn.CrossEntropyLoss()训练(Train)
for epoch in range(epochs):
for batch_idx,(data,target) in enumerate(train_loader):
data = data.view(-1,28*28)
logits = forward(data)
loss = criterion(logits,target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx % 100 ==0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data,target in test_loader:
data = data.view(-1,28*28)
logits = forward(data)
test_loss += criterion(logits,target).item()
pred = logits.data.max(1)[1]
correct+=pred.eq(target.data).sum()
test_loss /= len(test_loader.dataset)
print('nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))实验结果
实验1:权重随机初始化
Train Epoch: 0 [0/60000 (0%)] Loss: 3944.256592
Train Epoch: 0 [20000/60000 (33%)] Loss: 2.302583
Train Epoch: 0 [40000/60000 (67%)] Loss: 2.302583
Test set: Average loss: 0.0115, Accuracy: 1010/10000 (10%)
Train Epoch: 1 [0/60000 (0%)] Loss: 2.302583
Train Epoch: 1 [20000/60000 (33%)] Loss: 2.302583
Train Epoch: 1 [40000/60000 (67%)] Loss: 2.302583
Test set: Average loss: 0.0115, Accuracy: 1010/10000 (10%)
...
...
...
Train Epoch: 28 [0/60000 (0%)] Loss: 2.302583
Train Epoch: 28 [20000/60000 (33%)] Loss: 2.302583
Train Epoch: 28 [40000/60000 (67%)] Loss: 2.302583
Test set: Average loss: 0.0115, Accuracy: 1010/10000 (10%)
Train Epoch: 29 [0/60000 (0%)] Loss: 2.302583
Train Epoch: 29 [20000/60000 (33%)] Loss: 2.302583
Train Epoch: 29 [40000/60000 (67%)] Loss: 2.302583
Test set: Average loss: 0.0115, Accuracy: 1010/10000 (10%)实验2:Kaiming normal 权重初始化
Train Epoch: 0 [0/60000 (0%)] Loss: 2.482455
Train Epoch: 0 [20000/60000 (33%)] Loss: 0.850703
Train Epoch: 0 [40000/60000 (67%)] Loss: 0.374376
Test set: Average loss: 0.0018, Accuracy: 8953/10000 (89%)
Train Epoch: 1 [0/60000 (0%)] Loss: 0.325740
Train Epoch: 1 [20000/60000 (33%)] Loss: 0.359853
Train Epoch: 1 [40000/60000 (67%)] Loss: 0.334542
Test set: Average loss: 0.0014, Accuracy: 9207/10000 (92%)
....
...
..
Train Epoch: 28 [0/60000 (0%)] Loss: 0.092884
Train Epoch: 28 [20000/60000 (33%)] Loss: 0.076229
Train Epoch: 28 [40000/60000 (67%)] Loss: 0.032110
Test set: Average loss: 0.0005, Accuracy: 9714/10000 (97%)
Train Epoch: 29 [0/60000 (0%)] Loss: 0.037632
Train Epoch: 29 [20000/60000 (33%)] Loss: 0.095928
Train Epoch: 29 [40000/60000 (67%)] Loss: 0.084531
Test set: Average loss: 0.0005, Accuracy: 9721/10000 (97%)实验小结
通过实验1和实验2,我们发现随机初始化权重导致梯度置零,损失函数无法收敛,准确率一直在10%。
如果使用KaiMing Normal进行权重初始化,则准确率能达97%。
参考官方文档([torch.nn.init.kaiming_normal_][1]):
> Fills the input Tensor with values according to the method described in “Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification” - He, K. et al. (2015), using a normal distribution. The resulting tensor will have values sampled fromwhere
![]()
Also known as He initialization.
Parameters:
- tensor – an n-dimensional torch.Tensor
- a – the negative slope of the rectifier used after this layer (0 for ReLU by default)
- mode – either ‘fan_in’ (default) or ‘fan_out’. Choosing fan_in preserves the magnitude of the variance of the weights in the forward pass. Choosing fan_out preserves the magnitudes in the backwards pass.
- nonlinearity – the non-linear function (nn.functional name), recommended to use only with ‘relu’ or ‘leaky_relu’ (default).
[1]: torch.nn.init - PyTorch master documentation















 231
231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









